
Anthropic recently released Claude Sonnet 5. The Sonnet. I had to say it twice.
This is it the middle child of the Claude family, and one that many people will actually use. It’s fast, it’s capable, it’s cheap to run, too free to use for all users without subscription.
In this article, we look at the latest iteration of the Claude’s Sonnet family Sonnet 5. We put it to the test to see if its agent claims have any truth to them or not. And how Claude’s usual usr is affected by this free upgrade.
The Human Model
Sonnet 5 is now the default model for all users. If you’re using Claude without paying, this is the model you’re talking about. Opus stays behind the paid planso for most people, Sonnet 5 is just what Claude is. In short, the following is optimized:
- Job Tracking: you complete complex multi-step tasks fully instead of stopping early.
- Self-verification: checks and validates its own work without being told to do it.
- Use of Agent Tool: organizes, implements, extracts, and reviews its output.
- Low cost: cheaper per token than Opus, with a discounted launch price.
- Improved Reliability: reject bad requests better and not appear more often.
Meet the Family
Claude comes in three sizes. The Haiku is the fastest, the Opus is the heavyweight, and the Sonnet sits comfortably in between.
Here’s the part to be aware of: Sonnet just moved to 5th version. Haiku is still 4.5 and Opus is 4.8, so The Sonnet 5 is a newly redesigned model across the board.

It’s Less Expensive
Running Sonnet 5 is much cheaper than running Opus. Right now it’s still cheap, thanks to an introductory price that lasts until the end of August. For anyone who uses it a lot, that gap widens quickly.
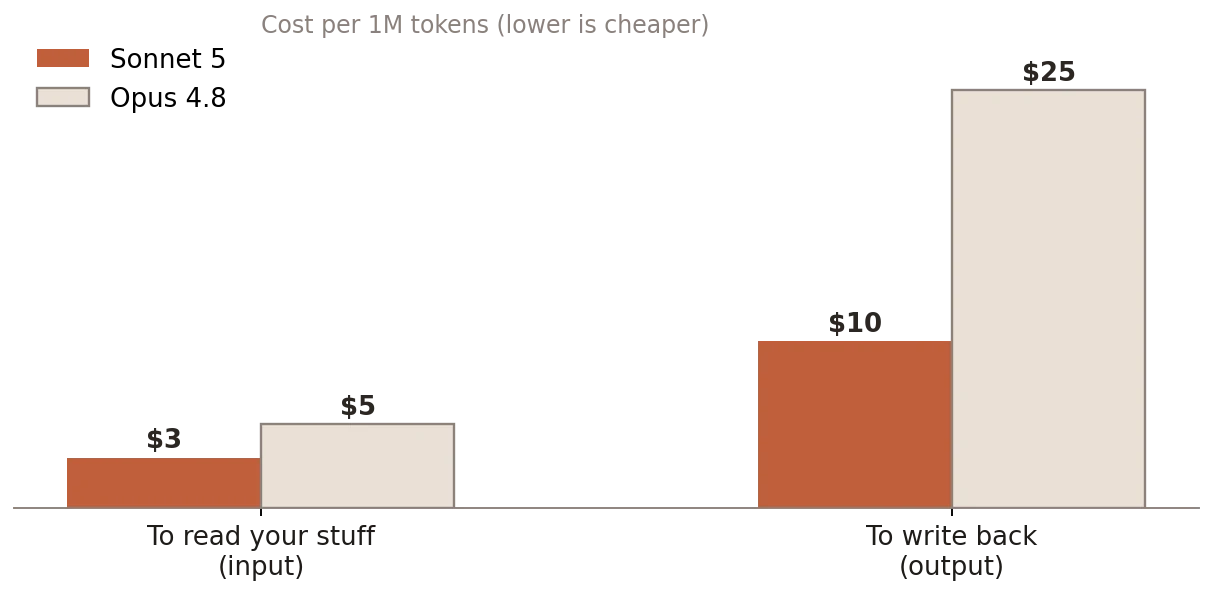
Agentic Focus: What It Really Does
Sonnet 5 is not just about conversation. It can take a job and get it done. It executes a program, using tools such as a web browser and your files, performs a task, and checks its own response before returning it.

The biggest change since the last version is you finish the job. Previous models were often stationary during long tasks. Sonnet 5 is familiar with them, and double-checks them without being told.
It is also a little safer to move things in them. It’s better to refuse dodgy requests, which are hard to fool, and make things a little more subtle than the Sonnet before it (something most people might not like).
Hands-On: Assessing Agentic Skills
Exercise 1: Agent Skills
Create a temporary Python project called agentic_sonnet_test. Inside it, create these files exactly:
# cart.py
class Cart:
def __init__(self):
self.items = []
def add(self, name, price, quantity=1):
self.items.append({"name": name, "price": price, "quantity": quantity})
def subtotal(self):
return sum(item["price"] for item in self.items)
def discount(self):
total = self.subtotal()
if total > 100:
return total * 0.1
return 0
def total(self):
return self.subtotal() - self.discount()
def receipt(self):
lines = []
for item in self.items:
lines.append(f'{item["name"]}: ${item["price"]}')
lines.append(f"Total: ${self.total()}")
return "n".join(lines)
# test_cart.py
from cart import Cart
def test_subtotal_uses_quantity():
cart = Cart()
cart.add("Book", 10, quantity=3)
cart.add("Pen", 2, quantity=5)
assert cart.subtotal() == 40
def test_discount_applies_at_100_or_more():
cart = Cart()
cart.add("Keyboard", 100, quantity=1)
assert cart.discount() == 10
def test_total_after_discount():
cart = Cart()
cart.add("Monitor", 150, quantity=2)
assert cart.total() == 270
def test_receipt_shows_line_totals_and_quantity():
cart = Cart()
cart.add("Book", 10, quantity=3)
receipt = cart.receipt()
assert "Book x3: $30" in receipt
assert "Subtotal: $30" in receipt
assert "Discount: $0" in receipt
assert "Total: $30" in receipt
Do the following:
1. Run the tests.
2. Inspect the failure output.
3. Fix the implementation in cart.py.
4. Re-run the tests.
5. Keep debugging until all tests pass.
6. Do not edit the tests.
7. At the end, show:
- the final cart.py
- the exact test command you ran
- the final test result
- a short explanation of what was broken and how you fixed itAnswer:
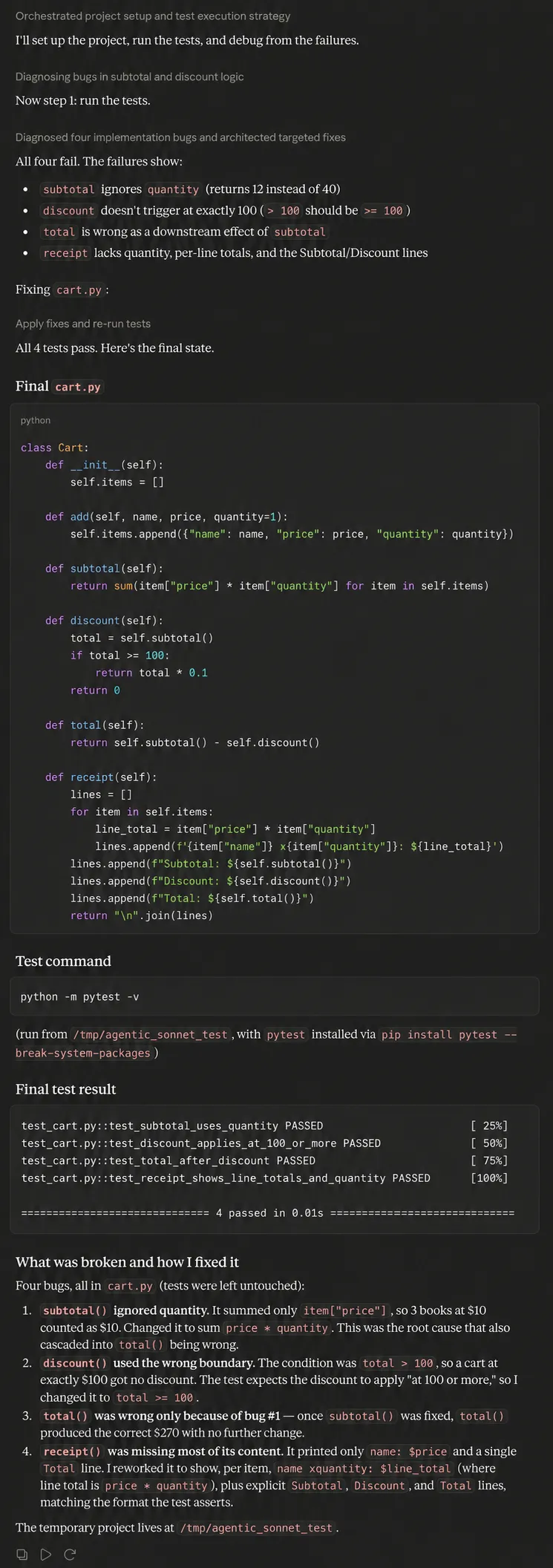
Decision: Sonnet 5 ran the tests before touching any code, found three different bugs instead of blindly debugging, and didn’t edit the test file to force a pass. Then it repeated everything to confirm the fixed fix. Being careful, correcting mistakes to close the loop properly instead of looking for success.
Exercise 2: Tool Use + Planning + Self-Repair
Notify:
I’m trying to choose the easiest online environment for running small Python experiments with a terminal. Compare Replit, GitHub Codespaces, and Google Colab using current official docs or help pages. For each one, check whether it supports:• creating files
• running shell or terminal commands
• installing packages
• saving or sharing the workspace
• lowest-friction setup for a beginnerPlease don’t rely on memory. Verify from sources.
At the end, give me:
• a comparison table
• your recommendation
• links to the pages you checked
• anything you’re uncertain about
Answer:
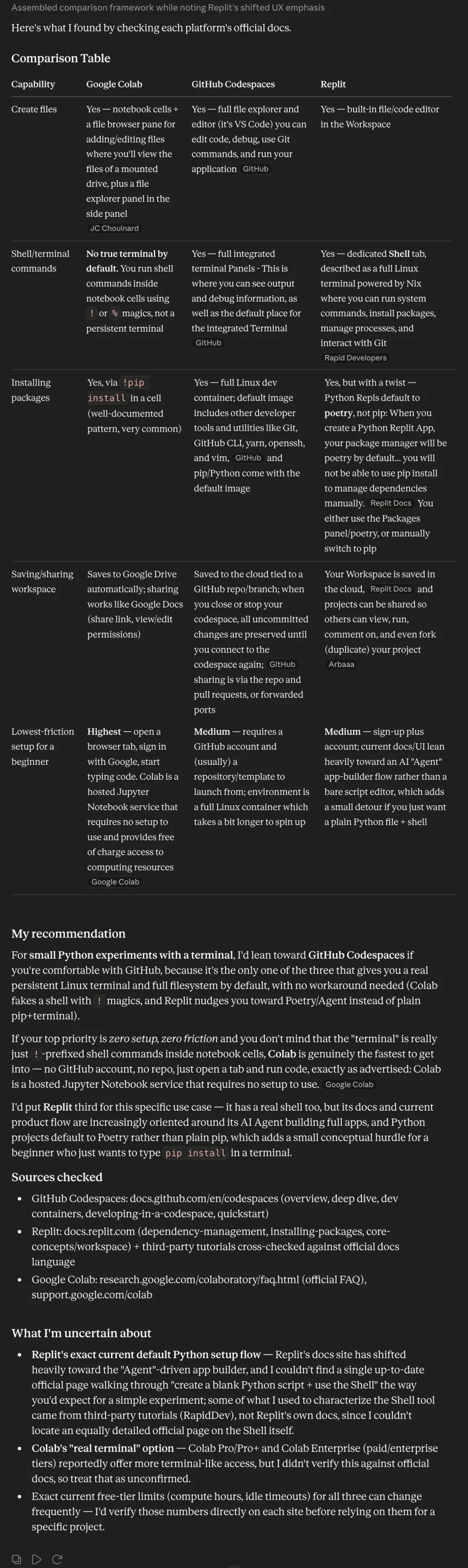
Decision: Sonnet 5 skipped relying on memory and examined the actual writings of each speaker, comparing all three against the same criteria so that nothing felt like it was missing. It concludes with an honest recommendation while marking where its judgment lies subjective. It’s comprehensive, well-researched, and upfront about its limitations.
Note: I use the Pro subscription. For Sonnet 5 with a medium level of reasoning, about 3-5% of the usage limit was used per agent task. This works very well.
The conclusion
The Sonnet 5 isn’t trying to be the smartest model in the world. Opus still owns the most difficult problems. Trying to be the one you reach out to every day.
So not only is the general problem-solving power of the Sonnet models improved, but also the use of the power to do the same is much less (due to using the Sonnet model over the Opus). This leads to longer/dense conversations without fear of limited access.
All in all, end users who may not have a subscription just got an upgrade in their default mode. As for those who subscribed, I don’t think Sonnet 5 will take over your workload in Opus 4.8. When it comes to using them via API, it’s a completely different discussion.
Frequently Asked Questions
IA. Claude Sonnet 5 is an Anthropic June 30, 2026 model designed for agent tasks, coding, tool use, and professional daily work.
A. Yes. It is the default model for Free and Pro users, while Opus resides in paid plans.
A. API pricing starts at $2 entry and $10 withdrawal for each 1M tokens until Aug 31, 2026.
![]()
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience includes AI model training, data analysis, and information retrieval, which allows me to create technically accurate and accessible content.
Sign in to continue reading and enjoy content curated by experts.



