
AI researcher Andrej Karpathy has developed an educational tool microGPT which provides easy access to GPT technology based on his research findings. This project uses 243 lines of Python code that does not require any external dependencies to show users the basic mathematical principles that govern the performance of the Large Language Model because it removes all the complexities of modern deep learning systems.
Let’s get down to the nitty-gritty and find out how he managed to achieve the miracle in such an economical way.
What makes MicroGPT revolutionary?
Most GPT tutorials today rely on PyTorch, TensorFlow, or JAX that work as powerful frameworks, but hide the fundamentals of math through an easy-to-use interface. Karpathy’s microGPT takes a different approach because it builds all of its functions with built-in Python modules that include basic programming tools.
The code does not contain the following:
- The code does not include PyTorch or TensorFlow.
- The code does not contain NumPy or any other numerical libraries.
- The program does not use GPU acceleration or any optimization techniques.
- The code does not contain hidden structures or unexposed systems.
The code contains the following:
- The program uses pure Python to create autograd that performs automatic classification.
- The system includes the complete structure of GPT-2 which includes the attention of many heads.
- Adam’s optimizer is built on first principles.
- The program provides a comprehensive training and mentoring program.
- The program produces an active text output that produces the actual text output.
This system works as a complete language model that uses real training data to create logical written content. The program is designed to prioritize comprehension over fast processing speed.
Understanding the Main Components
Autograd Engine: Building Backpropagation
Automatic segmentation serves as a key component of all neural network frameworks because it enables computers to automatically calculate gradients. Karpathy made a basic version of PyTorch autograd that he named micrograd that includes only one Value class. Enumeration uses Value objects to keep track of each number that contains two parts.
- Actual number value (data)
- Gradient with respect to loss (grad)
- What operation did you create (addition, multiplication, etc.)
- How to get back with that job
Value objects form a count graph when you use a + b working or i a*b to work. The program calculates all the gradients by using the chain rule application when signing loss.backward() commandment. This implementation of PyTorch performs its main functions without its efficiency and GPU power.
# Let there be an Autograd to apply the chain rule recursively across a computation graph
class Value:
"""Stores a single scalar value and its gradient, as a node in a computation graph."""
def __init__(self, data, children=(), local_grads=()):
self.data = data # scalar value of this node calculated during forward pass
self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass
self._children = children # children of this node in the computation graph
self._local_grads = local_grads # local derivative of this node w.r.t. its children
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other):
return Value(self.data**other, (self,), (other * self.data**(other - 1),))
def log(self):
return Value(math.log(self.data), (self,), (1 / self.data,))
def exp(self):
return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self):
return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self):
return self * -1
def __radd__(self, other):
return self + other
def __sub__(self, other):
return self + (-other)
def __rsub__(self, other):
return other + (-self)
def __rmul__(self, other):
return self * other
def __truediv__(self, other):
return self * other**-1
def __rtruediv__(self, other):
return other * self**-1GPT Architecture: Transformers Demystified
The model uses a simplified GPT-2 architecture with all the main transformer components:
- The system uses token embedding to create vector representations that represent each character in its corresponding read vector.
- The system uses spatial embedding to show the model the exact location of each token in the sequence.
- Multi-head attention enables all positions to view previous positions while integrating various data streams.
- The visited information is processed by forwarding networks that use the learned changes to analyze the data.
The implementation uses ReLU² (squared ReLU) instead of GeLU, and eliminates bias terms throughout the system, making the code easier to understand while maintaining its basic properties.
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # token embedding
pos_emb = state_dict['wpe'][pos_id] # position embedding
x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and position embedding
x = rmsnorm(x)
for li in range(n_layer):
# 1) Multi-head attention block
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(k)
values[li].append(v)
x_attn = []
for h in range(n_head):
hs = h * head_dim
q_h = q[hs:hs + head_dim]
k_h = [ki[hs:hs + head_dim] for ki in keys[li]]
v_h = [vi[hs:hs + head_dim] for vi in values[li]]
attn_logits = [
sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5
for t in range(len(k_h))
]
attn_weights = softmax(attn_logits)
head_out = [
sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h)))
for j in range(head_dim)
]
x_attn.extend(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP block
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() ** 2 for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logitsThe Training Loop: Learning Through Action
The training process is refreshingly simple:
- The code processes each document of the dataset by first converting its text into character ID tokens.
- The code processes each document by first converting its text into character ID tokens and then sending those tokens through the model for processing.
- The system calculates losses by its ability to predict the next character. The system performs backpropagation to obtain the gradient values.
- The program uses the Adam optimizer to perform parameter updates.
The Adam optimizer itself is implemented from scratch with proper bias correction and momentum tracking. The optimization algorithm provides complete transparency because all its steps are visible without hidden processes.
# Repeat in sequence
num_steps = 500 # number of training steps
for step in range(num_steps):
# Take single document, tokenize it, surround it with BOS special token on both sides
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# Forward the token sequence through the model, building up the computation graph all the way to the loss.
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
losses = []
for pos_id in range(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low.
# Backward the loss, calculating the gradients with respect to all model parameters.
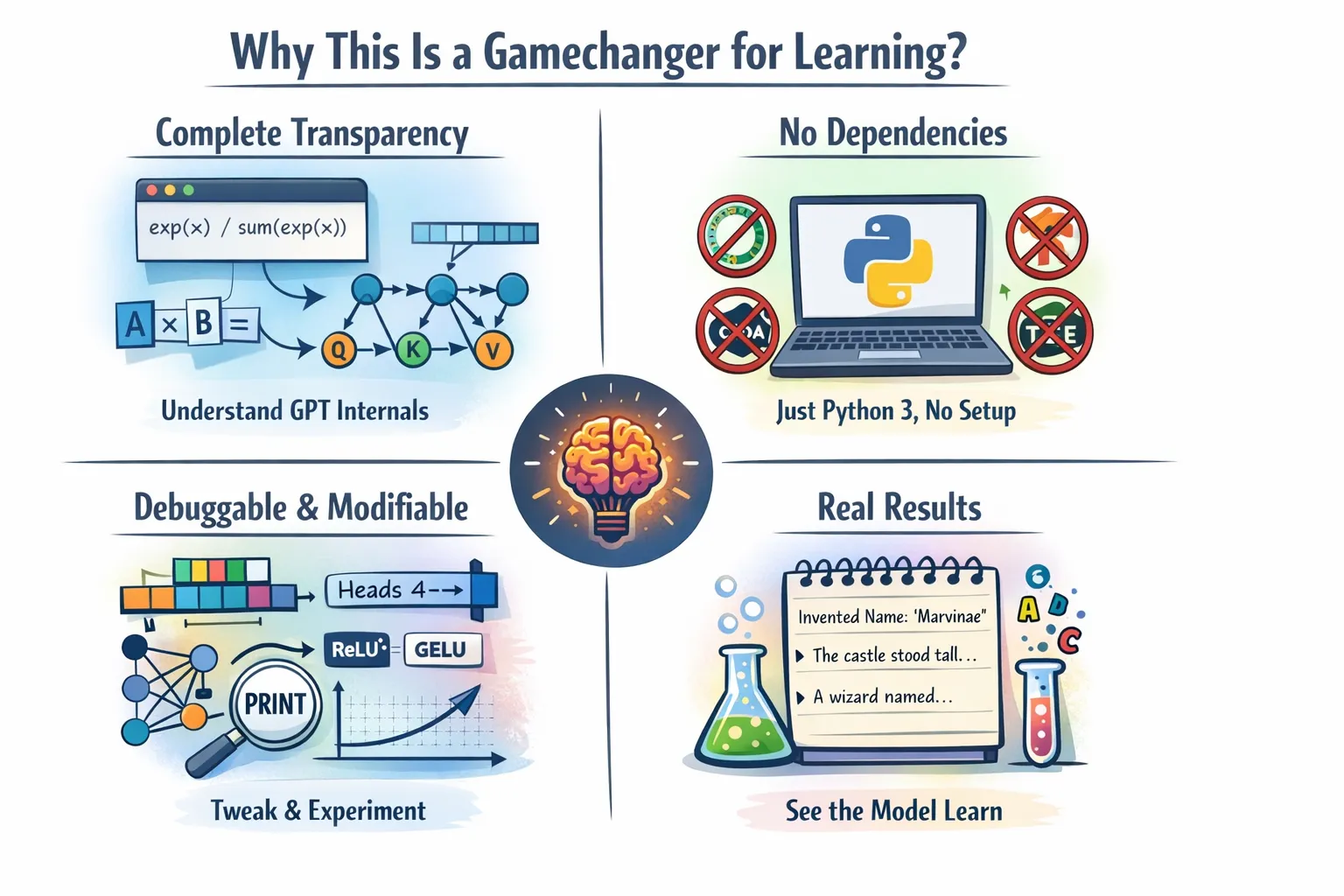
loss.backward()What Makes This Learning Game Changer?
This implementation is pedagogical gold for several reasons:
Complete transparency
Execution of thousands of lines of optimized C++ and CUDA code is possible when using the model.forward() working in PyTorch. A complete set of mathematical equations appears in Python code that you can read. Want to know exactly how softmax works? How are attention points calculated? How do gradients flow through matrix multiplication? All information appears in a transparent form in the code.
No Dependencies, No Installation Issues
The program works without requiring any dependencies while delivering straightforward installation procedures.
No conda areas, no CUDA toolkit, no version conflicts. Just Python 3 and curiosity. You can create a working GPT training system by copying the code from a file and running it. This removes all barriers between you and understanding.
Adjustable and Adjustable
You can test the system by adjusting its head count. You need to replace ReLU² with another activation function. The system allows you to add more layers. The program enables you to change the learning rate schedule by using its settings. The entire text can be read and understood by all students. The program allows you to place print statements at any point throughout the program to see the exact values flowing in the calculation graph.
Real Results
The academic content of this work makes it suitable for learning purposes despite its regulatory shortcomings. The model demonstrates its ability to train effectively while producing understandable text output. The program learns to form literal words after it is trained on a database of words. The inference phase uses temperature-based samples to show how the model generates creative content.
Getting Started: Getting Your GPT Started
The beauty of this project is its simplicity. The project requires you to download the code from the GitHub repository or the Karpathy website and save it as microgpt.py. You can use the following command to do it.
python microgpt.py It shows the process of downloading the training data while training the model and generating the output. The program requires no physical space and no plumbing and no configuration files. The system runs in untainted Python that performs untainted machine learning tasks.
If you’re interested in the full code, check out Andrej Kaparthy’s Github repository.
Working with Practical Limits
The current implementation shows slow performance because the implemented system takes an excessive amount of time to complete its tasks. The training process on a CPU with pure Python requires:
- The system executes tasks simultaneously
- The system performs calculations without GPU support
- The program uses pure Python math instead of advanced numerical libraries
A model trained in seconds with PyTorch requires three hours to complete the training process. The whole program works as a test environment with no real production code.
The academic code prioritizes clarity of learning objectives rather than immediate implementation. The process of learning to drive a manual transmission system is similar to learning to drive an automatic transmission system. The process allows you to feel every gear change while getting complete information about the transmission system.
In depth with experimental ideas
The process of using code requires that you first learn a programming language. Testing begins after gaining an understanding of the code:
- Configure the architecture: Add more layers, change the embedding size, experiment with different focus heads
- Try different datasets: Practice with code snippets, song lyrics, or any text that interests you
- Use new features: Add dropouts, learning rate schedules, or different adaptation schemes
- Correct the gradient flow error: Add an inset to see how the gradients change during training
- Prepare to work: Explore the system with NumPy implementations and basic vectorization implementations while maintaining system performance
The code structure allows users to perform tests without difficulty. Your experiments will reveal the important principles that govern transformer performance.
The conclusion
A 243-line GPT implementation on behalf of microGPT developed by Andrej Karpathy works as more than an algorithm because it shows the beauty of Advanced coding. The program shows that understanding transformers requires only a few lines of keyframe code. The program shows that users can understand how attention works without requiring expensive GPU hardware. Users only need the building blocks to develop their own language modeling program.
The combination of your curiosity and Python programming and your ability to understand 243 lines of educational code creates your learning needs for success. This implementation serves as a real gift for three different groups of people: students, engineers, and researchers who want to learn about neural networks. The program gives you a very accurate view of the transformer properties available in all locations.
Download the file, read the code, make changes or disassemble the whole process and start your version. The program will teach you about GPT functionality with its pure Python code base, which you will read one line at a time.
Frequently Asked Questions
A. It’s a pure implementation of Python GPT that exposes key statistics and properties, helping students understand transformers without relying on complex frameworks like PyTorch.
A. He uses autograd, the GPT architecture, and the Adam optimizer entirely in Python, showing how training and backpropagation work step by step.
A. It runs in pure Python without GPUs or advanced libraries, prioritizing clarity and education over speed and productivity.
![]()
Data Science Trainee at Analytics Vidhya
I currently work as a Data Science Trainer at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analysis, I am passionate about using AI to create impactful, innovative solutions that bridge the gap between technology and business.
📩 You can also contact me at [email protected]
Sign in to continue reading and enjoy content curated by experts.



