A new ETH Zurich study proves that your AI Coding agents are failing because your AGENTS.md files are too detailed

In the advanced world of AI, ‘Content Engineering’ has emerged as the latest frontier to push performance out of LLMs. Industry leaders applauded AGENTS.md (and his cousins like it CLAUDE.md) as the final destination for coding agents—a cache-level ‘North Star’ embedded throughout the conversation to guide AI to complex codes.
But a recent study from researchers at ETH Zurich I just dropped a big reality check. The findings are clear: if you are not deliberate with your context files, you are probably hurting your agent’s performance while paying a 20% premium for the privilege.
Data: More Tokens, Less Success
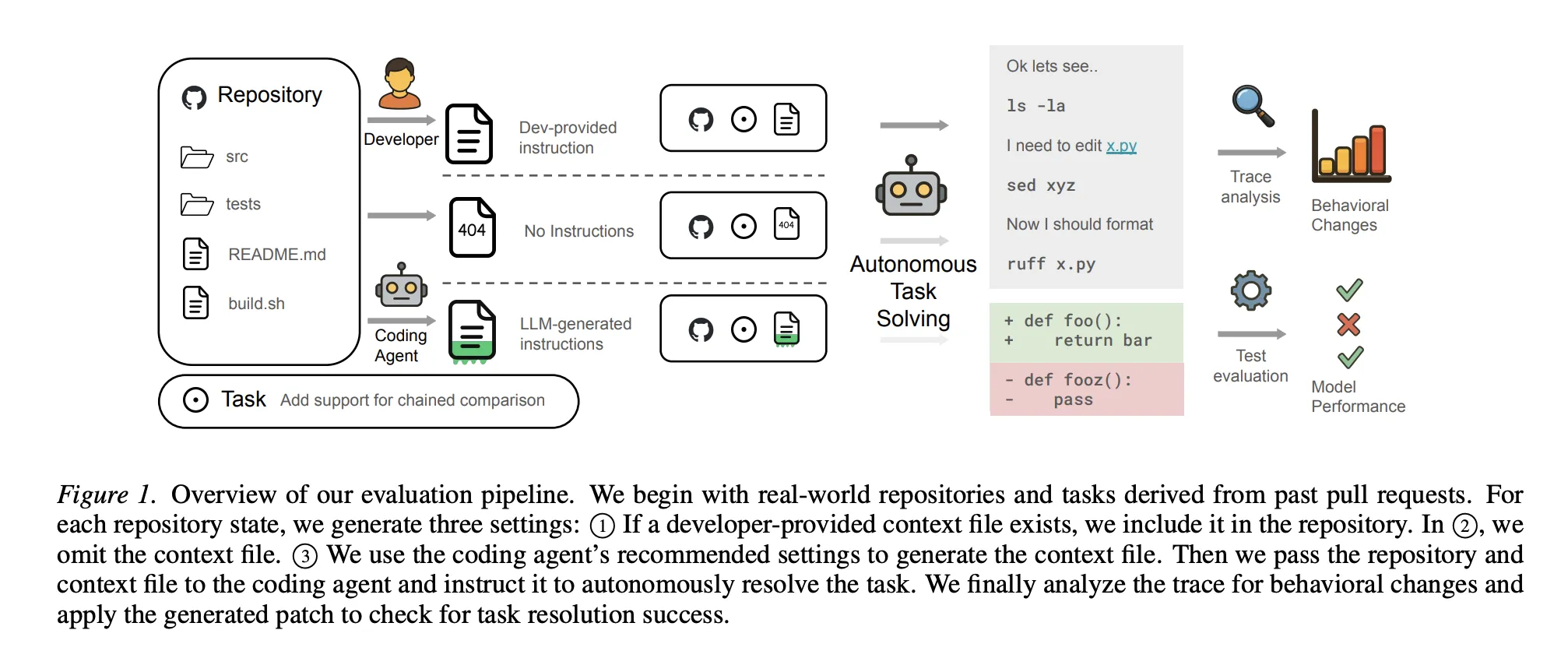
A team of researchers from ETH Zurich analyzed coding agents like these Sonnet-4.5, GPT-5.2again Qwen3-30B across established benchmarks and a novel set of real-world functions called AGENTBENCH. The results were surprisingly slow:
- Automatically Generated Tax: Content files are actually generated automatically lower success rates by about 3%.
- Costs of ‘Help‘: These files increase the cost of thinking by more than 20% and additional thinking steps were required to solve similar tasks.
- The Human Margin: Even files written by humans are only given a 4% performance gain..
- Intelligence Cap: Interestingly, using robust models (such as GPT-5.2) to generate these files did not yield better results. Robust models often have enough ‘parametric’ information for standard libraries that additional context becomes redundant.
Why ‘Good’ Content Fails
The research team highlights the ethical pitfalls: AI agents listen a lot. Coding agents tend to respect instructions found in context files, but when those requirements are not required, they make the job difficult.
For example, researchers found that Codebase overview and directories—basic to most AGENTS.md files—didn’t help agents navigate faster. Agents are surprisingly efficient at automatically detecting file structures; reading manual listings consumes logic tokens and adds more ‘mental’. In addition, the files generated by LLM are often empty if you already have decent documentation elsewhere in the repo.

The New Rules of Content Engineering
To make context files truly useful, you need to move from ‘complete documentation’ to ‘surgical intervention.’
1. What to Include (‘The Essential Few’)
- Technology Stack and Purpose: Explain the ‘What’ and the ‘Why.’ Help the agent understand the purpose of the project and its structure (eg, monorepo structure).
- Obscure Tools: Here it is
AGENTS.mdit shines. Explain how to build, test, and validate changes using specific tools like theseuvinstead ofpiporbuninstead ofnpm. - The Multiplier Effect: The data shows those instructions there is followed; the tools specified in the content file are used the most. For example, a tool
uvwas used 160x always (1.6 times per instance compared to 0.01) when clearly stated.+1
2. What to Release (‘Noise’)
- Details Document Trees: Skip. Agents can find the files they need without a map.
- Style Guides: Don’t waste tokens telling the agent to “use camelCase.” Use deterministic linters and formats instead—they’re cheaper, faster, and more reliable.
- Direct Work Instructions: Avoid rules that only apply to part of your problems.
- Uncensored Default Content: Don’t let the agent write its own content file without human review. Research proves that ‘rigid’ models do not make better guides.
3. How it is Organized
- Keep it Lean: The general consistency of the most efficient context files is less than 300 lines. Professional teams usually keep theirs even tighter—less than 60 lines. Every line is important because every line is injected every time.
- Continuous Disclosure: Don’t include everything in the root file. Use a master file to identify the agent to separate, task-specific scripts (eg
agent_docs/testing.md) only if necessary. - Clues On Copies: Instead of embedding code snippets that will eventually expire, use pointers (eg
file:line) to show the agent where to find design patterns or direct links.
Key Takeaways
- The Negative Impact of Automated Manufacturing: Context files generated by LLM tend to reduce the job success rate by approx 3% on average compared to not providing a cache context at all.
- Essential Costs Are Rising: Including core files increases the cost of consideration more than 20% and leads to a higher number of steps required for agents to complete tasks.
- Less Human Interest: Although human-written (developer-supplied) context files perform better than automatically generated ones, they only provide a small improvement in 4% over using context files.
- Redundancy and roaming: A detailed overview of the codebase in the context files has little to do with existing documentation and does not help agents find important files quickly.
- Following Strict Instructions: Agents generally respect the instructions in these files, but unnecessary or overly restrictive requirements often make solving real-world tasks difficult for the model.
Check it out Paper. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.




