Google AI Launches STATIC: Sparse Matrix Framework Delivers 948x Compulsory Code Extraction Based on LLM for Productivity

In industrial recommendation systems, switching to him Productive Return (GR) it replaces neighbor embedding-based nearest search using Large-scale Language Models (LLMs). These models represent things like Semantic IDs (SIDs)-a sequence of various tokens-and treat retrieval as an automatic record function. However, industrial applications often require strict adherence to business logic, such as enforcing content innovation or asset availability. Conventional automated decoding cannot naturally enforce these constraints, often leading the model to “see” invalid or out-of-stock identifiers.
Accelerator Bottleneck: Trying vs. TPUs/GPUs
To ensure valid output, developers often use a hash tree (try) to hide invalid tokens during each encoding step. Although conceptually straightforward, the traditional trie implementation does not perform well on hardware accelerators such as TPUs and GPUs.
The performance gap arises from two main issues:
- Memory Latency: Pointer-chasing structures result in inconsistent, random access to memory. This prevents memory clustering and fails to utilize the High-Bandwidth Memory (HBM) power of modern accelerators.
- Integration Incompatibility: Accelerators that rely on static computing graphs to integrate machine learning (eg, Google’s XLA). The Standard attempts to use data-dependent control flow and iterative branches, which are inconsistent with this paradigm and often force expensive round-trips of the host device.
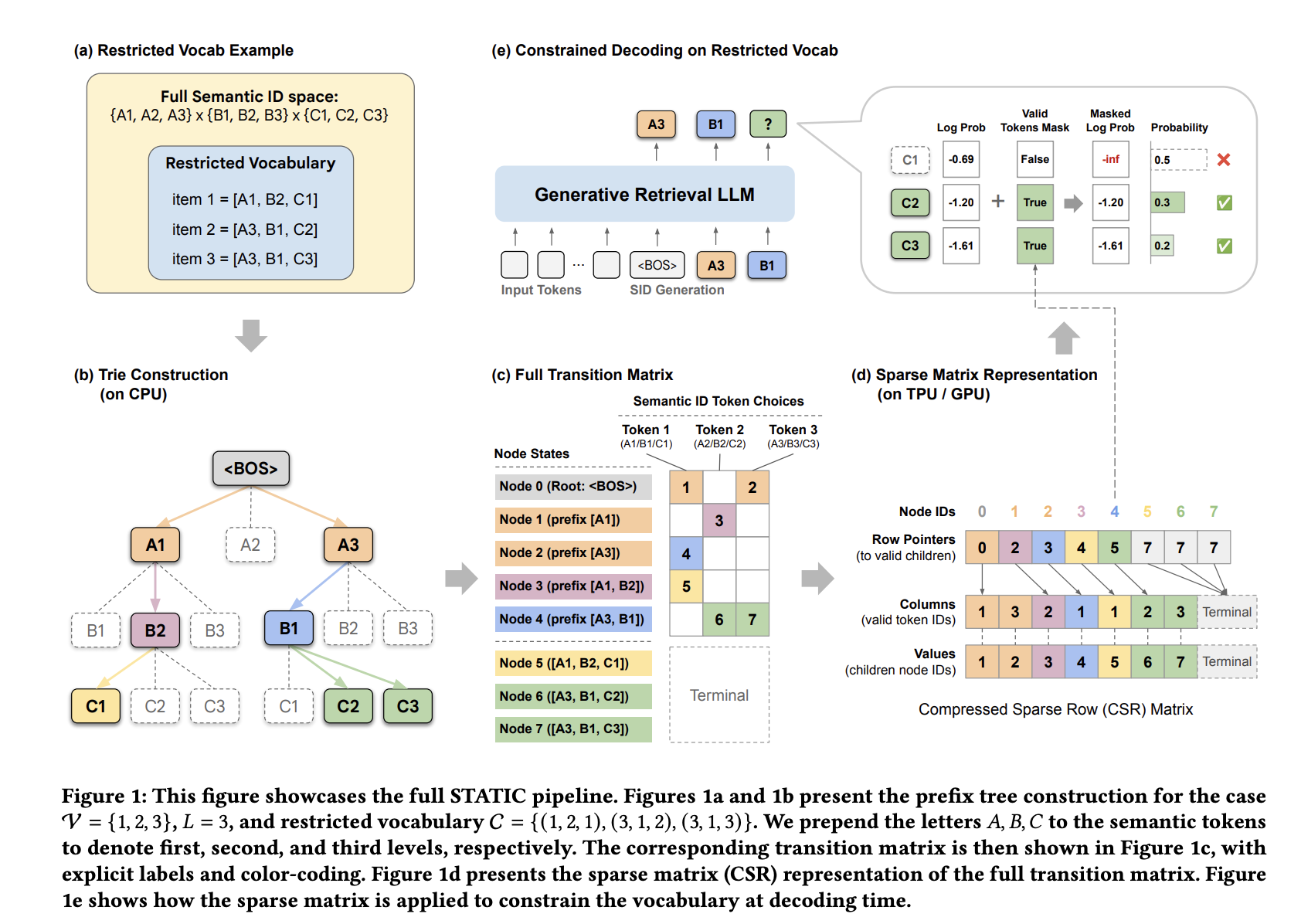
STATIC: Sparse Transition Matrix-Accelerated Trie Index
Google DeepMind and YouTube researchers presented STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding) to solve these problems. Instead of treating the trie as a graph to be drawn, STATIC flattens it. Compressed Short Line (CSR) the matrix. This transformation allows irregular tree intersections to be performed as fully vectorized empty matrix functions.
Hybrid Decoding Architecture
STATIC uses a two-stage monitoring strategy to measure memory usage and speed:
- Dense Masking (t-1 d): First of all d=2 layers, where the branching factor is very high, STATIC uses a dense boolean tensor. This allows O(1) look at the timing of the first computationally expensive steps.
- Vectorized Node Transition Kernel (VNTK): For deeper layers (l ≥ 3), STATIC uses a branchless kernel. This kernel performs a ‘guess slice’ for a fixed number of entries (Bt), which corresponds to the highest characteristic of the branch at that level. By using a fixed-size slice regardless of the child’s actual count, the entire recording process remains a single, static count graph.
This method achieves i I/O complexity of O(1) compared to the size of the restricted set, while the hardware-accelerated search methods past binary are scaled logarithmically (O(log|C|)).
Performance and Scalability
Tested on Google TPU v6e accelerators using a 3 billion parameter model with a cluster size of 2 and a beam size (M) of 70, STATIC showed significant performance advantages over existing methods.
| The way | Maximum Latency Per Step (ms) | % of Total Indexing Time |
| STATIC (Ours) | +0.033 | 0.25% |
| PPV Approx | +1.56 | 11.9% |
| Hash Bitmap | +12,3 | 94.0% |
| CPU Trie | +31.3 | 239% |
| The PPV of course | +34.1 | 260% |
STATIC achieved a 948x speed over a CPU-loaded attempt and passed the new binary search (PPV) baseline 1033x. Its latency remains almost the same as the Semantic ID word size (|V|) increases.
With a vocabulary of 20 million items, the STATIC maximum usage of HBM is approx 1.5 GB. In practice, due to the non-uniform distribution and clustering of Semantic IDs, the actual usage is often ≤75% of this obligation. The rule of thumb for energy planning is approx 90 MB of HBM with 1 million limits.
Delivery Results
STATIC was installed on YouTube to enforce the new ‘last 7 days’ policy on video recommendations. The program provided a vocabulary of 20 million new items with 100% compatibility.
Online A/B testing shown:
- A + 5.1% increase on new video views for 7 days.
- A + 2.9% increase on new video views for 3 days.
- A + 0.15% increase by click through rate (CTR).
Cold Start Performance
The framework also addresses the ‘cold start’ limitation of generated retrieval—recommending objects that cannot be observed during training. By forcing the model on a cold baseline set on the Amazon Reviews dataset, STATIC significantly improved performance over unconstrained baselines, recording 0.00% Recall@1. In these tests, a Gemma parameter of 1 billion was used L = 4 tokens and a vocabulary size of |V|=256.
Key Takeaways
- Vectorized Operation: STATIC re-encodes from a graph traversal problem to a hardware-friendly, vectorized matrix operation by flattening primitive trees into static Compressed Sparse Row (CSR) matrices.
- Big Speedups: The system achieves 0.033ms latency per step, which represents a 948x speedup over CPU-loaded attempts and a 47–1033x speedup over the hardware-accelerated search baseline.+1
- Scalable O(1) Complexity: By profit O(1) I/O complexity relative to block set size, STATIC maintains high performance with low memory of about 90 MB for 1 million objects.
- Proven Productivity Results: YouTube postings showed 100% compliance with business logic restrictions, resulting in a 5.1% increase in new video views and a 0.15% increase in click-through rates.
- Cold Start Solution: The framework allows generative recall models to effectively recommend cold starts, increasing Recall@1 performance from 0.00% to non-trivial levels in Amazon review benchmarks.
Check it out Paper again Codes. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.




