
Are you building GenAI programs and want to use them, or want to learn more about FastAPI? Then this is exactly what you’ve been looking for! Imagine you have a lot of PDF reports and you want to search for some answers in them. Either you can spend hours scrolling, or you can build a system that reads for you and answers your questions. We are building a RAG system to be deployed and accessed via an API using FastAPI. So without further ado, let’s dive in.
What is FastAPI?
FastAPI is a Python framework for building APIs. FastAPI allows us to use HTTP methods to communicate with the server.
One of its useful features is that it automatically generates documentation for the APIs you create. After writing your code and creating APIs, you can visit the URL and use the interface (Swagger UI) to test your points without having to code the front-end.
Understanding REST APIs
A REST API is a link that creates communication between a client and a server. REST API is short for Representational State Transfer API. A client can send HTTP requests to a specific API endpoint, and the server processes those requests. There are several HTTP methods available. A few we will use in our project using FastAPI.
HTTP methods:
In our project, we will use two communication methods:
- GET: This is used to retrieve information. We will use the /health GET request to check if the server is running.
- SUBMIT: This is used to send data to the server to create or process something. We will use / log in and / ask for post requests. We use POST here because it involves sending complex data like files or JSON objects. More about this in the getting started section.
What is RAG?
Retrieval-Augmented Generation (RAG) is one way to give the LLM access to specific information that it was not originally trained on.
Components of RAG:
- Retrieval: Finding the right sentences in documents based on a query.
- Generation: Passing those sentences to LLM so it can summarize them into an answer.
Let’s understand more about RAG in the next implementation section.
Implementation
Problem Statement: Creating a system that allows users to upload documents, especially .txt or PDF files. It then points them to a searchable database and ensures that the LLM can answer questions about the new data. This program will be implemented and implemented with API endpoints that we will create with FastAPI.
Prerequisites
– We will need an OpenAI API key, and we will use the gpt-4.1-mini model as the brain of the program. You can get your hands on an API key from the link: (
– An IDE for running Python scripts, I’ll use VSCode for the demo. Create a new project (folder).
– Make an .env file in your project and add your OpenAI key exactly:
OPENAI_API_KEY=sk-proj... – Create a Virtual Environment for this project (Split project dependencies).
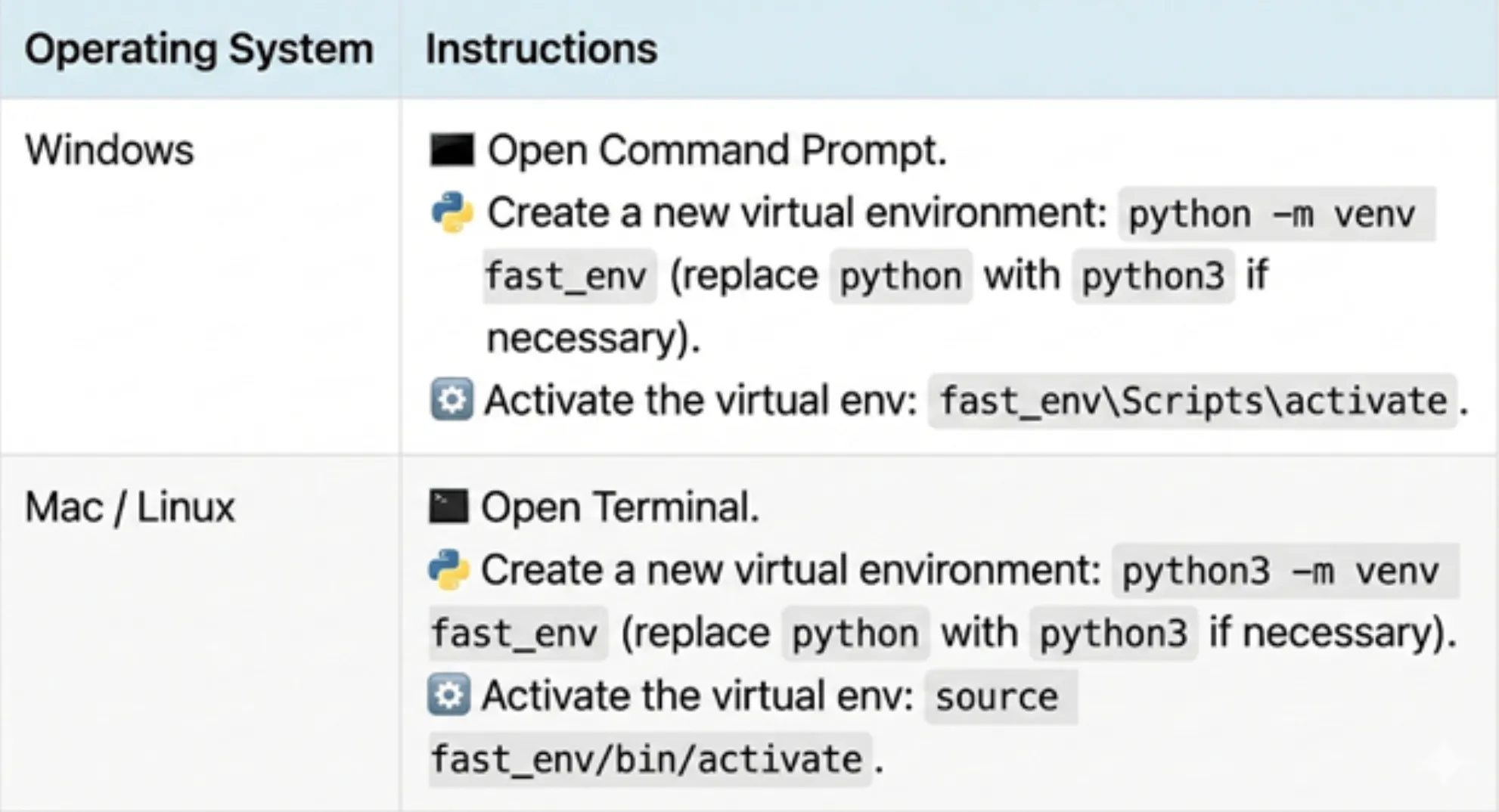
Note:
- Make sure that fast_env is created in your project, as path errors may occur if the working directory is not set to the project directory.
- Once activated, any packages you install will be contained in this location.
– Download the blog below as a PDF using the ‘download icon’ that you can use in our RAG program:
Requirements
To solve this, we need a stack that handles the heavy lifting:
- FastAPI: To handle web requests and file uploads.
- LangChain: Expanding LLM skills.
- FAISS (Facebook AI Similar Search): It helps to search through pieces of text. We will use it as a vector database.
- Uvicorn: Server hosting.
You can create requits.txt in your project and run ‘pip install -r needs.txt’:
fastapi==0.129.0
uvicorn[standard]==0.41.0
python-multipart==0.0.22
langchain==1.2.10
langchain-community==0.4.1
langchain-openai==1.1.10
langchain-core==1.2.13
faiss-cpu==1.13.2
openai==2.21.0
pypdf==6.7.1
python-dotenv==1.2.1How to Get Started
We will use two FastAPI endpoints:
1. Ingest Pipe (/ingest)
When a user uploads a file, we use the RecursiveCharacterTextSplitter from LangChain. This function breaks long documents into small pieces (we will set the function to make each piece size like 500 characters).
These pieces are then converted into embeds and stored on our site FAISS index (vector database). We will use FAISS local storage so that even if the server restarts, the uploaded documents will not be lost.
2. Query Pipe (/query)
When you ask a question, the question turns into a vector. We then use FAISS to find the top uk (typically 4) text fragments that are most similar to the query.
Finally, we use it LCEL (LangChain Expression Language) to use the Generations section of RAG. We are posting the question and those 4 patches to gpt-4.1-mini along with our prompts for an answer.
Python code
In the same project folder, create two scripts, rag_pipeline.py and main.py:
rag_pipeline.py:
Imported
import os
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.documents import Document
from dotenv import load_dotenv
from typing import List Configuration
# Loading OpenAI API key
load_dotenv()
# Config
FAISS_INDEX_PATH = "faiss_index"
EMBEDDING_MODEL = "text-embedding-3-small"
LLM_MODEL = "gpt-4.1-mini"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50Note: Make sure to add the API key to the .env file
Implementation and Defining Functions
# Shared state
_vectorstore: FAISS | None = None
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
def _load_vectorstore() -> FAISS | None:
"""Load existing FAISS index from disk if it exists."""
global _vectorstore
if _vectorstore is None and os.path.exists(FAISS_INDEX_PATH):
_vectorstore = FAISS.load_local(
FAISS_INDEX_PATH,
embeddings,
allow_dangerous_deserialization=True
)
return _vectorstore
def ingest_document(file_path: str, filename: str = "") -> int:
"""
Chunks, Embeds, Stores in FAISS and returns the number of chunks stored.
"""
global _vectorstore
# 1. Load
if file_path.endswith(".pdf"):
loader = PyPDFLoader(file_path)
else:
loader = TextLoader(file_path)
documents = loader.load()
# Overwriting source with the filename
display_name = filename or os.path.basename(file_path)
for doc in documents:
doc.metadata["source"] = display_name
# 2. Chunk
splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=["nn", "n", ".", " ", ""]
)
chunks = splitter.split_documents(documents)
# 3. Embed and Store
if _vectorstore is None:
_load_vectorstore()
if _vectorstore is None:
_vectorstore = FAISS.from_documents(chunks, embeddings)
else:
_vectorstore.add_documents(chunks)
# 4. Persist to disk
_vectorstore.save_local(FAISS_INDEX_PATH)
return len(chunks)
def _format_docs(docs: List[Document]) -> str:
"""Concatenate document page_content to add to the prompt."""
return "nn".join(doc.page_content for doc in docs)These functions help to combine documents, split the text into embeddings (using the embedding model: embedding-text-3-small) and store them in the FAISS directory (vector store).
Defining Retriever and Generator
def query_rag(question: str, top_k: int = 4) -> dict:
"""
Returns answer text and source references.
"""
vs = _load_vectorstore()
if vs is None:
return {
"answer": "No documents have been ingested yet. Please upload a document first.",
"sources": []
}
# Retriever
retriever = vs.as_retriever(
search_type="similarity",
search_kwargs={"k": top_k}
)
# Prompt
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""You are a helpful assistant. Use only the context below to answer the question.
If the answer is not in the context, say "I don't know based on the provided documents."
Context:
{context}
Question: {question}
Answer:"""
)
llm = ChatOpenAI(model=LLM_MODEL, temperature=0)
# LCEL chain
# Step 1:
retrieve = RunnableParallel(
{
"source_documents": retriever,
"context": retriever | _format_docs,
"question": RunnablePassthrough(),
}
)
# Step 2:
answer_chain = prompt | llm | StrOutputParser()
# Invoke
retrieved = retrieve.invoke(question)
answer = answer_chain.invoke(retrieved)
# Extracting sources
sources = list({
doc.metadata.get("source", "unknown")
for doc in retrieved["source_documents"]
})
return {
"answer": answer,
"sources": sources,
}We used our RAG, which retrieves 4 documents using the same search and passes the query, context, and information to Generator (gpt-4.1-mini).
First, the relevant documents are fetched using the query, then the response_chain is executed which returns the query as a string using StrOutputParser().
Note: top-k and query will be passed as arguments to the function.
main.py
Imported
import os
import tempfile
from fastapi import FastAPI, UploadFile, File, HTTPException
from pydantic import BaseModel
from rag_pipeline import ingest_document, query_ragWe have imported the ingest_document and query_rag functions, which will be used by the API Endpoints we will describe.
Configuration
app = FastAPI(
title="RAG API",
description="Upload documents and query them using RAG",
version="1.0.0"
)
ALLOWED_EXTENSIONS = {
"application/pdf": ".pdf",
"text/plain": ".txt",
}
class QueryRequest(BaseModel):
question: str
top_k: int = 4
class QueryResponse(BaseModel):
answer: str
sources: list[str]Using Pydantic to strictly define the structure of the input to the API.
Note: Validators can also be added here to perform some checks (for example: checking that the phone number is exactly 10 digits long)
/health API
@app.get("/health", tags=["Health"])
def health():
"""Check if the API is running."""
return {"status": "ok"}This API helps to verify if the server is running.
Note: We wrap API functions with a decorator; here, we use @app because we started FastAPI with this variable earlier. Also, followed by the HTTP method, here’s get(). Then we pass the path to the endpoint, “/life” here.
/ingest API (Ingesting a document from the user)
@app.post("/ingest", tags=["Ingestion"], summary="Upload and index a document")
async def ingest(file: UploadFile = File(...)):
"""
Upload a **.txt** or **.pdf** file.
"""
if file.content_type not in ALLOWED_EXTENSIONS:
raise HTTPException(
status_code=400,
detail=f"Unsupported file type '{file.content_type}'. Only .txt and .pdf are supported."
)
suffix = ALLOWED_EXTENSIONS[file.content_type]
contents = await file.read()
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
tmp.write(contents)
tmp_path = tmp.name
try:
num_chunks = ingest_document(tmp_path, filename=file.filename)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
finally:
os.unlink(tmp_path)
return {
"message": f"Successfully ingested '{file.filename}'",
"chunks_indexed": num_chunks
}This function only verifies that a .txt or .pdf has been received and calls the ingest_document() function defined in the rag_pipeline.py script.
/query API (Using the RAG pipeline)
@app.post("/query", response_model=QueryResponse, tags=["Query"], summary="Ask a question about your documents")
def query(request: QueryRequest):
"""
Ask a question related to the provided document.
The pipeline will return the answer and the source file names used to generate it.
"""
if not request.question.strip():
raise HTTPException(status_code=400, detail="Question cannot be empty.")
try:
result = query_rag(request.question, request.top_k)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
return QueryResponse(answer=result["answer"], sources=result["sources"])Finally, we defined an API that calls the query_rag() function and returns the response according to the documentation to the user. Let’s quickly check it out.
It uses an operating system
– Use the command below in your command line or terminal:
uvicorn main:app --reloadNote: Make sure your environment is running and all dependencies are installed. Or you may see errors related to the same.
– Now the app should work again here:
– Open the Swagger UI (Interface) using the URL below:
/documents
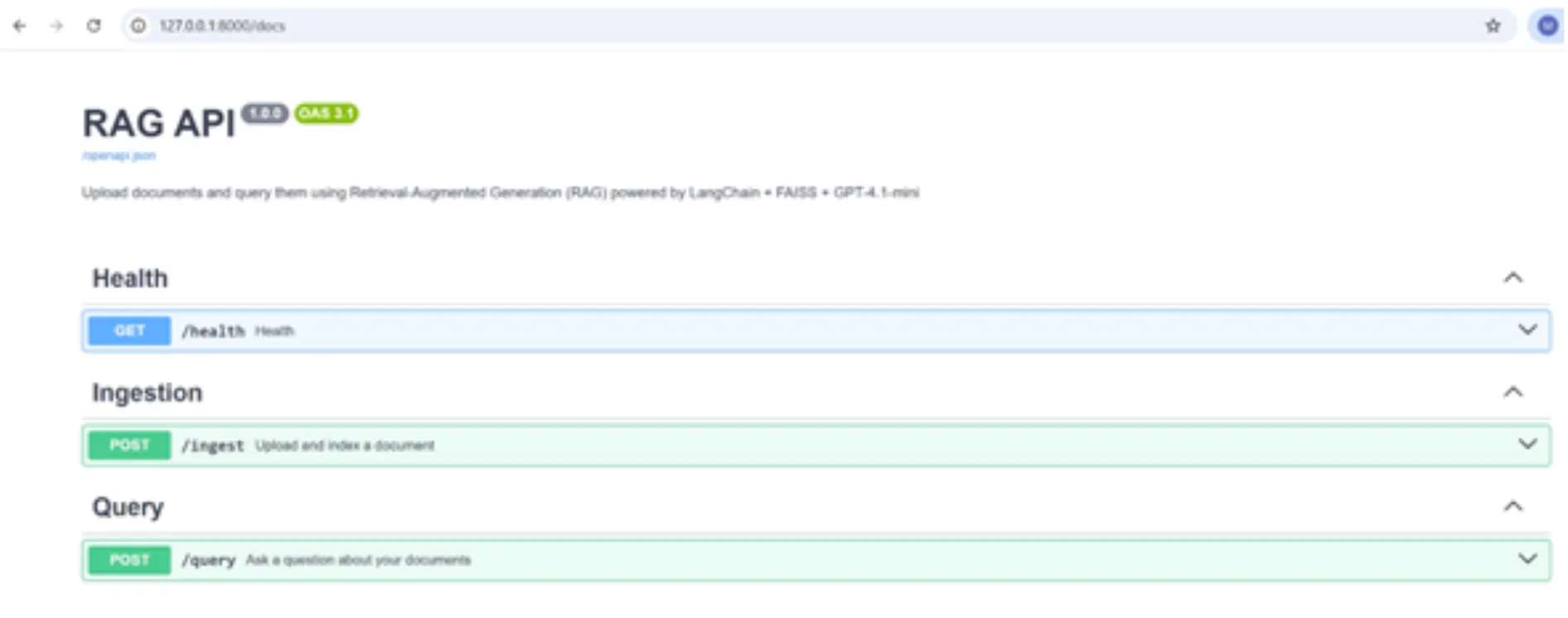
Good! We can test our APIs using the interface by simply passing arguments to the APIs.
Tests Both APIs
1. /ingest API:
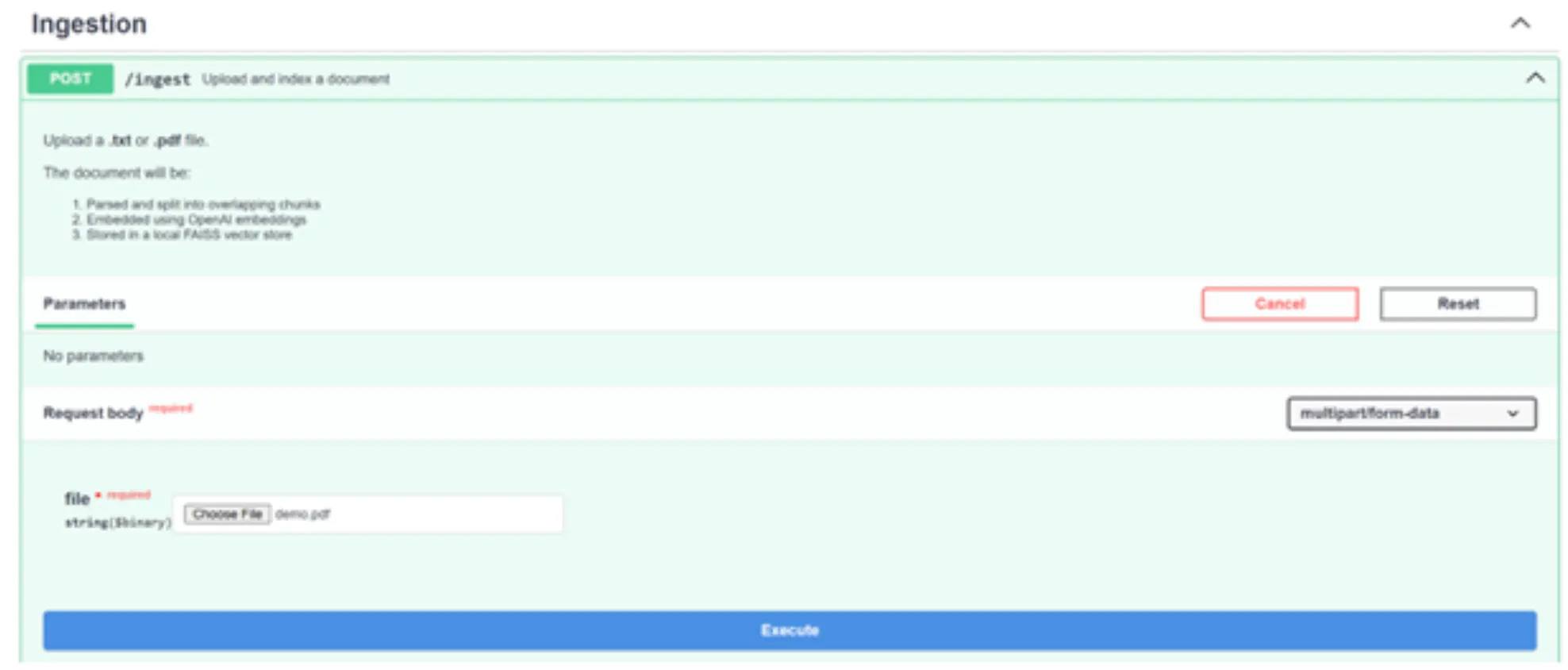
Click ‘Try it’ and upload the demo.pdf (you can replace it with any other PDF). Then click to do.
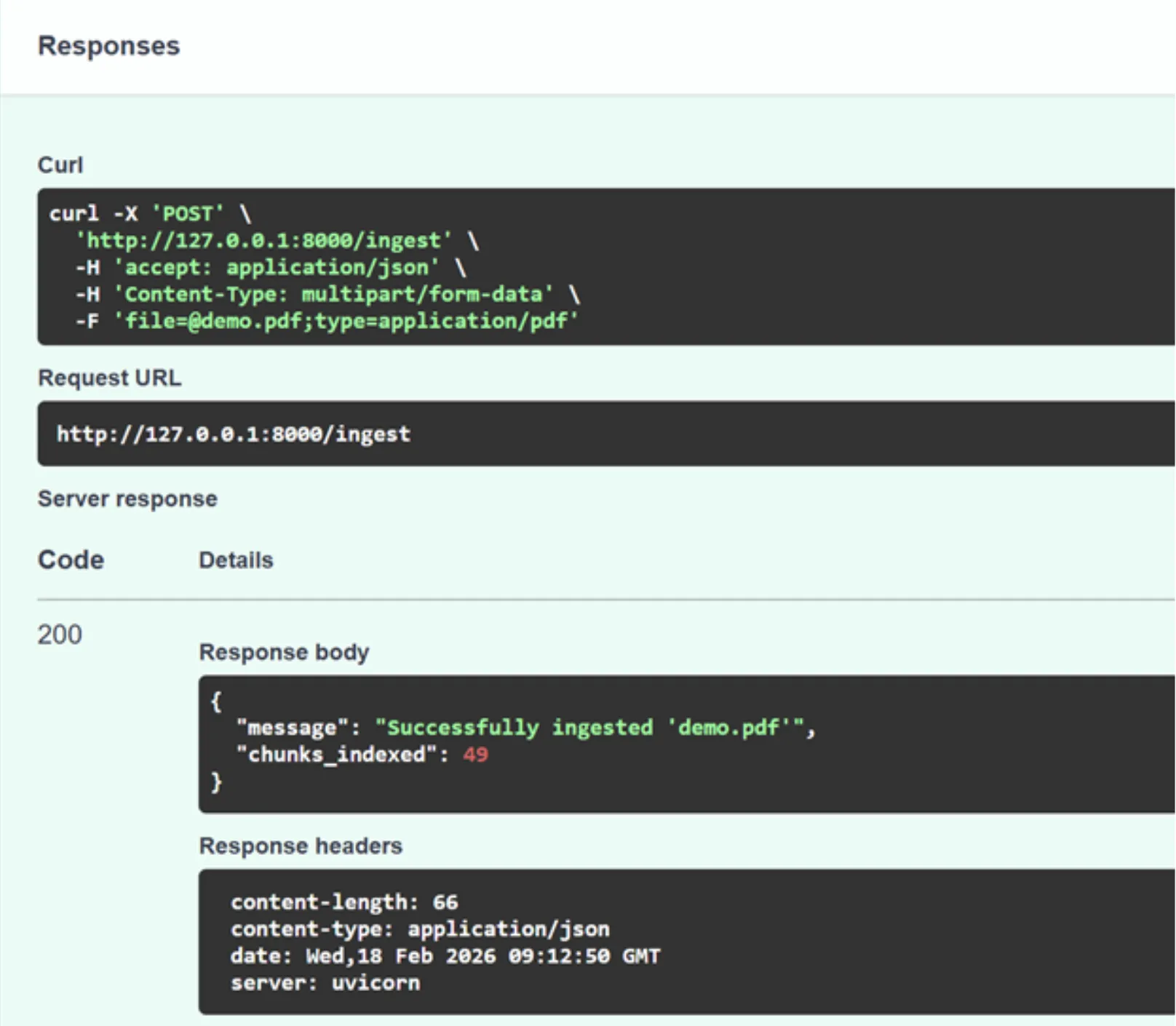
Good! The API processed our request and created a vector store using the PDF. You can confirm the same by checking your project folder, where you can see a new faiss_index folder.
2. /query API:
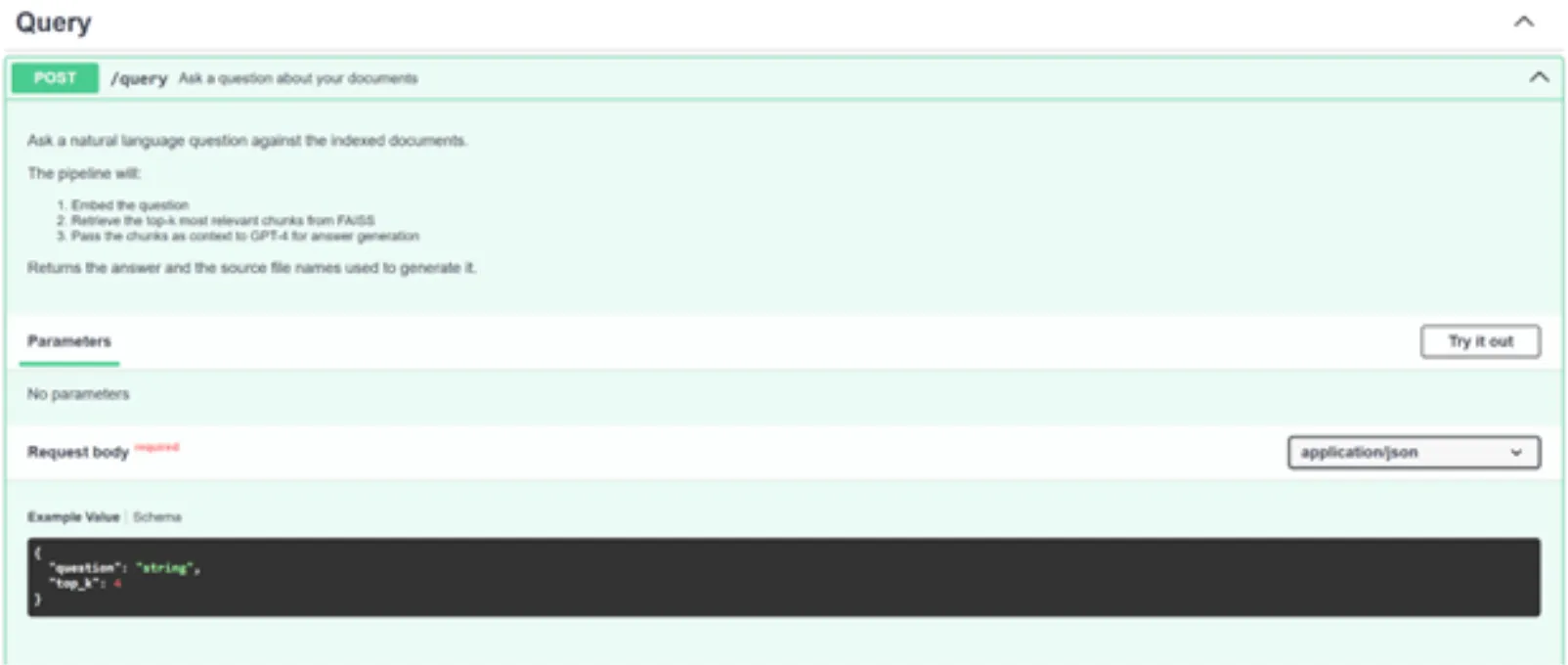
Now, click on Try it and pass the arguments below (Feel free to use different prompts and PDFs).
{
"question": "Name 3 applications of Machine Learning",
"top_k": 4
}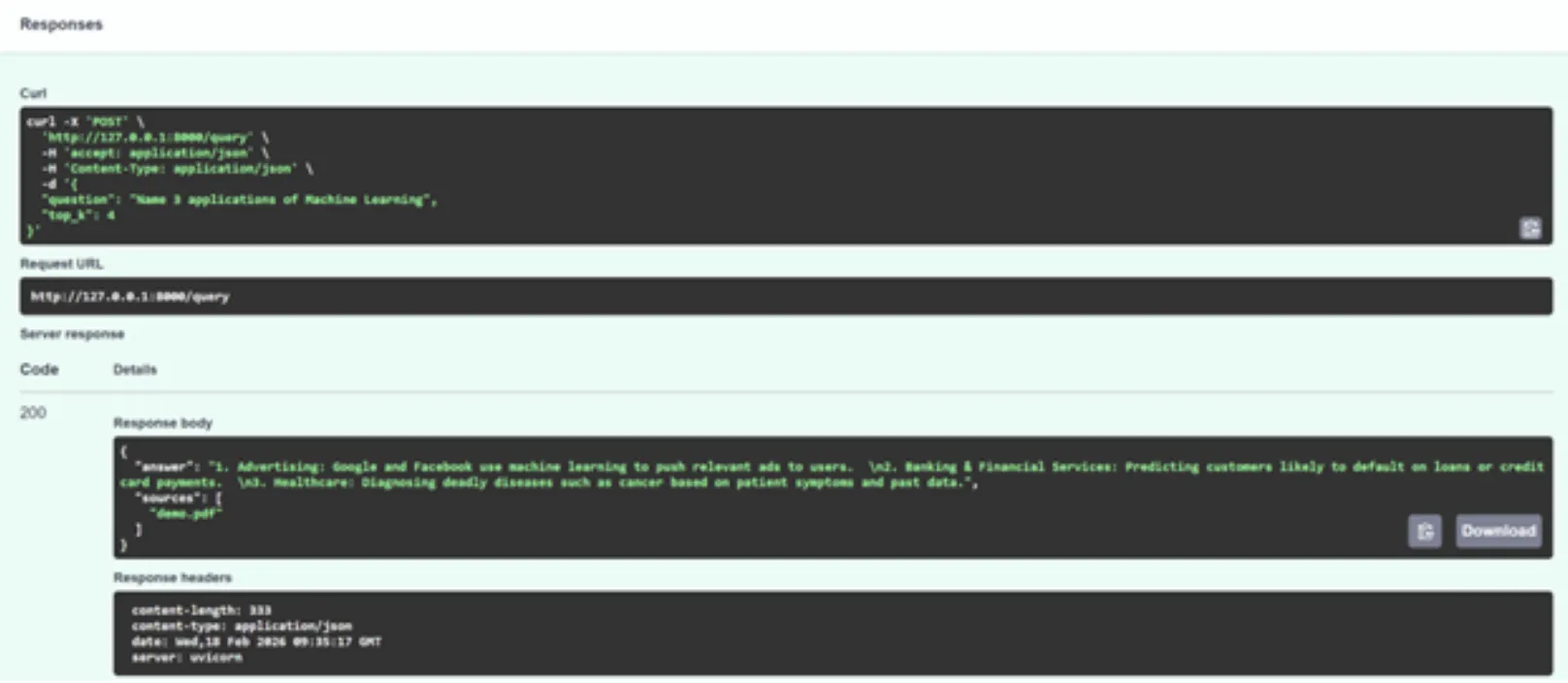
As expected, the answer seems to have a lot to do with the content in the PDF. You can further play with the top-k parameter and test it with different queries.

Understanding HTTP Status Codes
HTTP status codes notify the client if the request was successful or if something went wrong.
Status code categories:
Success
*The request has been successfully received and processed.
In our project:
- /health returns 200 OK when the server is running.
- /ingest and /query return 200 OK if successful.
Client Errors
*The error was caused by a client submission.

In our project:
- If you upload an unexpected file type (not a PDF or txt file), the API returns a 400 status code.
- If the query is empty in /query, the API returns a 400 status code.
- FastAPI returns a 422 status code if the request body does not match the expected Pydantic model we defined.
Server Errors
*They indicate that something has gone wrong on the server side.

In our project:
- If the import or query code fails due to a FAISS error or an OpenAI error the API returns a 500 status code.
Also read:
The conclusion
We successfully implemented and learned how to build and run a RAG system using FastAPI. Here we have created an API that imports PDF/.txt files, retrieves relevant information, and generates relevant responses. The deployment component makes GenAI systems or traditional ML systems more accessible to real-world applications. We can further improve our RAG by developing an integration strategy and integrating different methods to retrieve our queries.
Frequently Asked Questions
-reload makes the FastAPI server automatically restart whenever the code changes, showing the updates without restarting the server.
We use POST because queries include structured data as JSON objects. These can be large and complex. These are not the same as GET requests used for simple retrieval.
MMR (Maximum Marginal Merit) balances relevance and diversity when selecting document fragments, ensuring that the returned results are useful without being confusing.
Increasing top_k retrieves more LLM bits, which can lead to potential noise in the generated responses due to the presence of irrelevant content.
![]()
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. He is currently working as a Data Science Trainer, specializing in Data Science. He has a strong interest in Deep learning and Generative AI, eager to explore advanced techniques for solving complex problems and creating impactful solutions.
Sign in to continue reading and enjoy content curated by experts.



