Microsoft Releases Phi-4-Reasoning-Vision-15B: A Multimodal Compact Model for Math, Science, and GUI Understanding

Microsoft has released it Phi-4-consultation-opinion-15Ba 15 billion parameter multimodal reasoning model with open weights designed for graphic and text tasks that require both comprehension and selective thinking. It is an integrated model designed to measure the quality of the inference, to calculate the efficiency, and the requirements of the training data, with some power scientific reasoning and mathematics again understanding user interactions.

What is the model built on?
Phi-4-reasoning-vision-15B includes i Phi-4-Consultation language backbone with SigLIP-2 a vision encoder uses a mid-fusion architecture. In this setup, the vision encoder first converts the images into visual tokens, and then those tokens are presented to the embedding of the language model and processed by the pre-trained language model. This design works as a practical trade-off: it maintains robust parallelism while keeping training and instructional costs manageable compared to heavier early integration designs.
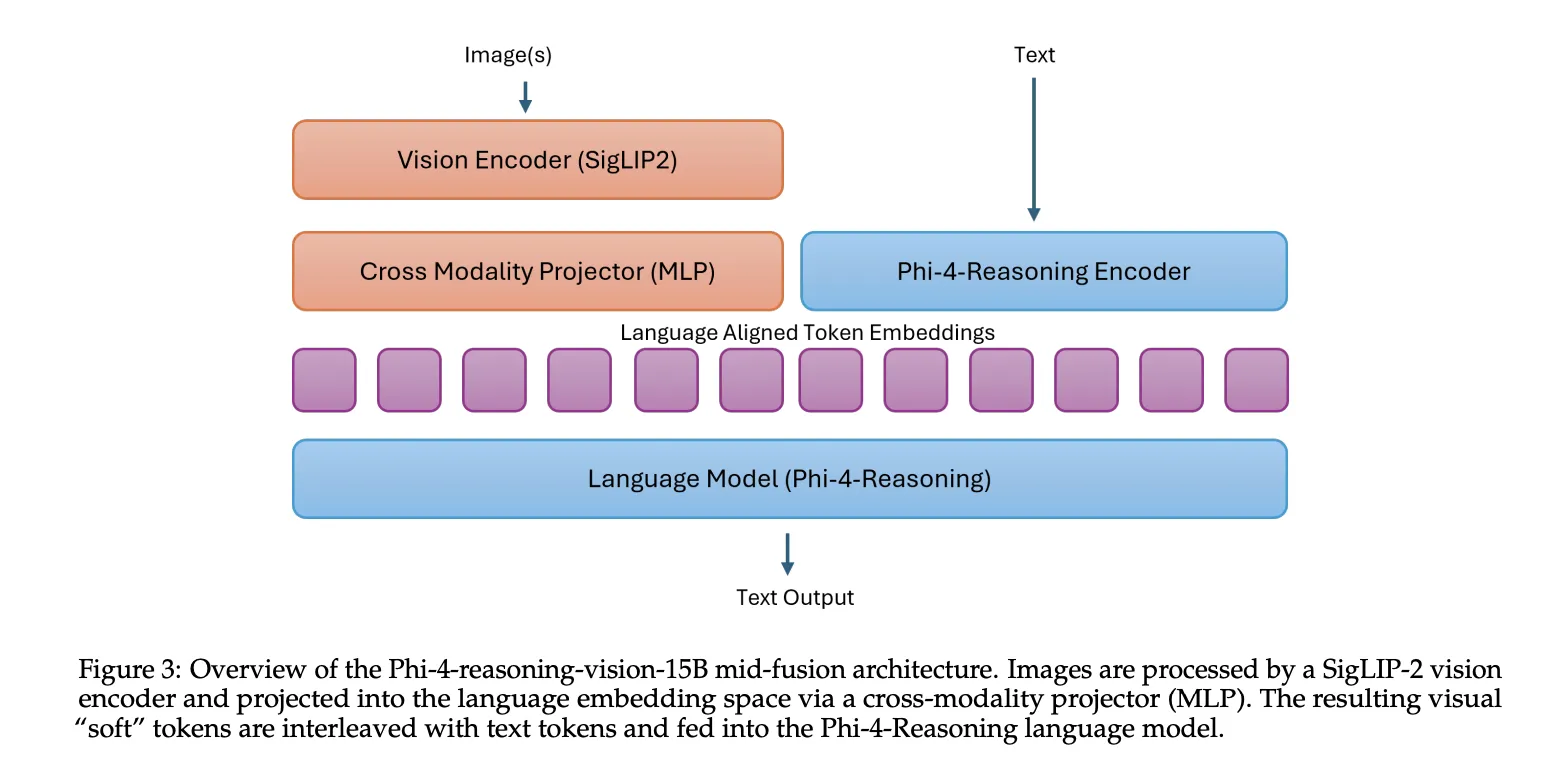
Why Microsoft took the smaller model route?
Many recent models of the view language have expanded on the calculation of parameters and the use of tokens, which raises both latency and transmission costs. Phi-4-reasoning-vision-15B is designed as a small alternative that handles common multimodal workloads without relying on very large training datasets or excessive reasoning time token generation. The model was trained on it 200 billion multimodal tokensto build upon Phi-4-Consultationwhich was trained 16 billion tokensand finally to Phi-4 base model, which was trained on 400 billion unique tokens. Microsoft compares that to more than a trillion tokens which is used to train several recent multimodal models such as Qwen 2.5 VL, Qwen 3 VL, To me VLagain Gemma 3.
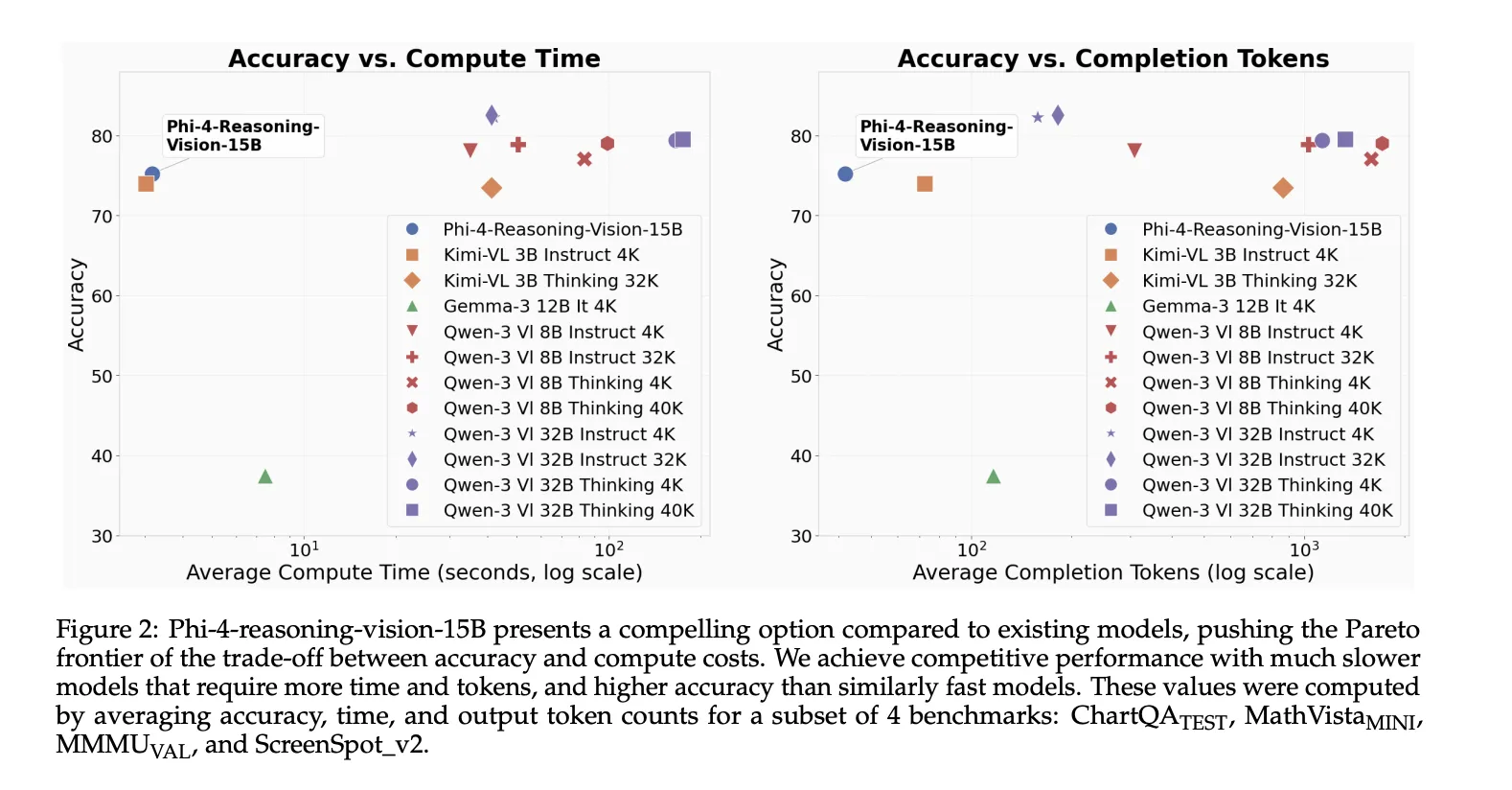
The idea of high resolution was a key design choice
The Microsoft team explains one of the most useful technical lessons in their technical report is that multimodal thinking often fails because the vision fails first. Models can miss the answer not because they lack the ability to think, but because they fail to extract the right visual details from dense images such as screenshots, documents, or communications with small interactive elements.
Phi-4-reasoning-vision-15B uses a variable resolution vision encoder with up to 3,600 visual tokensintended to support high-resolution understanding of tasks like this Basic GUI again well-refined document analysis. The Microsoft team says so high-definition, dynamic-resolution encoders provide consistent improvementsand it clearly states that intuitive understanding is a prerequisite for high-quality thinking.
Mixed thinking instead of forcing thinking everywhere
The second important design decision is the model mixed and irrational thinking strategy. Instead of forcing the thinking style of thinking on all tasks, the Microsoft team trained the model to switch between two methods. Thinking samples include
The goal of this mixed setup is to allow the model to respond directly to tasks where long-range thinking adds delay without improving accuracy, while still using systematic thinking for tasks like math and science. The Microsoft team also notes an important limitation: the border between these methods is read consistently, so the switch is not always correct. Users can override the default behavior by using transparent information with
What are the strong points?
The Microsoft team highlights 2 main application areas. The first one is scientific and mathematical reasoning in addition to visual inputincluding handwritten figures, diagrams, charts, tables, and quantitative documents. The second says agent functions for computer usewhere the model translates screen content, localizes GUI objects, and supports interaction with desktop, web, or mobile interfaces.
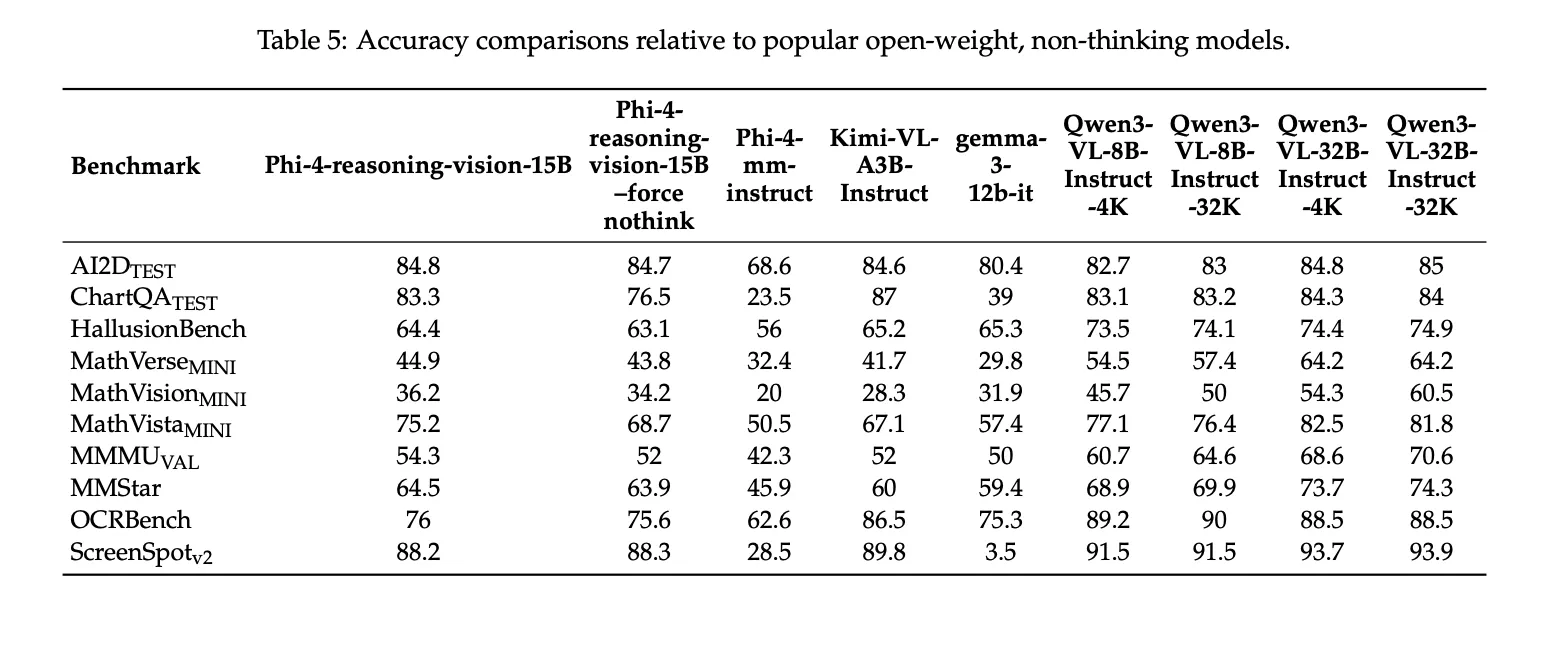
Benchmark results
The Microsoft team reports the following benchmark scores for Phi-4-reasoning-vision-15B: 84.8 on AI2DTEST, 83.3 on ChartQATEST, 44.9 in MathVerseMINI, 36.2 in MathVisionMINI, 75.2 in MathVistaMINI, 54.3 in MMMUVAL, 64.5 on MMStar, 76.0 on OCRBenchagain 88.2 on ScreenSpotv2. The technical report also notes that these results were made using Eureka ML Insights again VLMevalKitand fixed test settings, and the Microsoft team presents them as comparative results rather than leaderboard claims.
Key Takeaways
- Phi-4-reasoning-vision-15B is an open-weighted multimodal model 15B built by integration Phi-4-Consultation with SigLIP-2 vision encoder in a mid-fusion architecture.
- The Microsoft team designed a multimodal consultation modelby focusing on math, science, document understanding, and GUI basicsinstead of scaling to a very large parameter count.
- High-resolution vision is a key part of the systemwith the support of dynamic resolution encoding and up to 3,600 virtual tokenswhich comes in handy for dense screenshots, documents, and visual-heavy tasks.
- The model uses mixed and random trainingallowing it to change between
- Microsoft’s reported benchmarks show strong performance for its sizeincluding open results AI2DTEST, ChartQATEST, MathVistaMINI, OCRBench, and ScreenSpotv2which supports its position as a conceptual model that is associative but capable of visual language.
Check it out Paper, Repo again Model weights. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



