Google AI Introduces Gemini 2 Embedding: A Multimodal Embedding Model That Lets You Deliver Text, Images, Video, Audio, and Documents to the Embedding Space.

Google has expanded its Gemini model family with the release of Embedding Gemini 2. This second-generation model is text-only gemini-embedding-001 and is specifically designed to address the high storage and retrieval challenges faced by AI developers who are building productivity. Retrieval-Augmented Generation (RAG) plans. I Embedding Gemini 2 The release marks a significant technological shift in the way embedding models are designed, moving from process-specific paths to an integrated, heterogeneous architecture.
Native multimodality and multimodal input
The main architectural development in Gemini Embedding 2 is its mapping capabilities five different media types—Text, Image, Video, Audio, and PDF– in a single, high-dimensional space. This eliminates the need for complex pipelines that previously required separate models for different data types, such as CLIP for images and BERT-based models for text.
The model supports left inputwhich allows developers to combine various methods in a single embedded application. This is especially important in situations where the text alone does not provide enough context. The technical limitations of this installation are defined as:
- Text: Up to 8,192 tokens per request.
- Photos: Up to 6 images (PNG, JPEG, WebP, HEIC/HEIF).
- Video: Up to 120 seconds of video (MP4, MOV, etc.).
- Sound: Up to 80 seconds of native audio (MP3, WAV, etc.) without requiring a separate transcription step.
- Documents: Up to 6 pages of PDF files.
By processing this input naturally, Gemini Embedding 2 captures the semantic relationship between the visual frame in the video and the spoken dialogue in the audio track, expressing them as a single vector that can be compared to text queries using standard distance metrics such as Cosine similarity.
Efficiency with Matryoshka Representation Learning (MRL)
Storage and computational cost are often the main constraints in large-scale vector searches. To mitigate this, Gemini Embedding 2 is implemented Matryoshka Representation Learning (MRL).
Standard embedding models distribute semantic information equally across dimensions. When a developer shrinks a 3,072 vector to 768 dimensions, accuracy often degrades because information is lost. In contrast, Gemini Embedding 2 is trained to pack the most important semantic information into the primitive vector dimension.
The model automatically states that 3,072 in sizebut The Google team has developed three specific categories of productivity applications:
- 3,072: High accuracy for complex legal, medical, or technical datasets.
- 1,536: Balance performance and storage efficiency.
- 768: Optimized for low latency retrieval and memory reduction.
Matryoshka Representation Learning (MRL) enables the formation of ‘short listing’. The system can perform coarse, super-fast searches on millions of objects using 768-dimension sub-vectors, and perform precise rescaling of top results using a full 3,072-dimension embedding. This reduces the total computation of the first retrieval stage without sacrificing the final accuracy of the RAG pipeline.
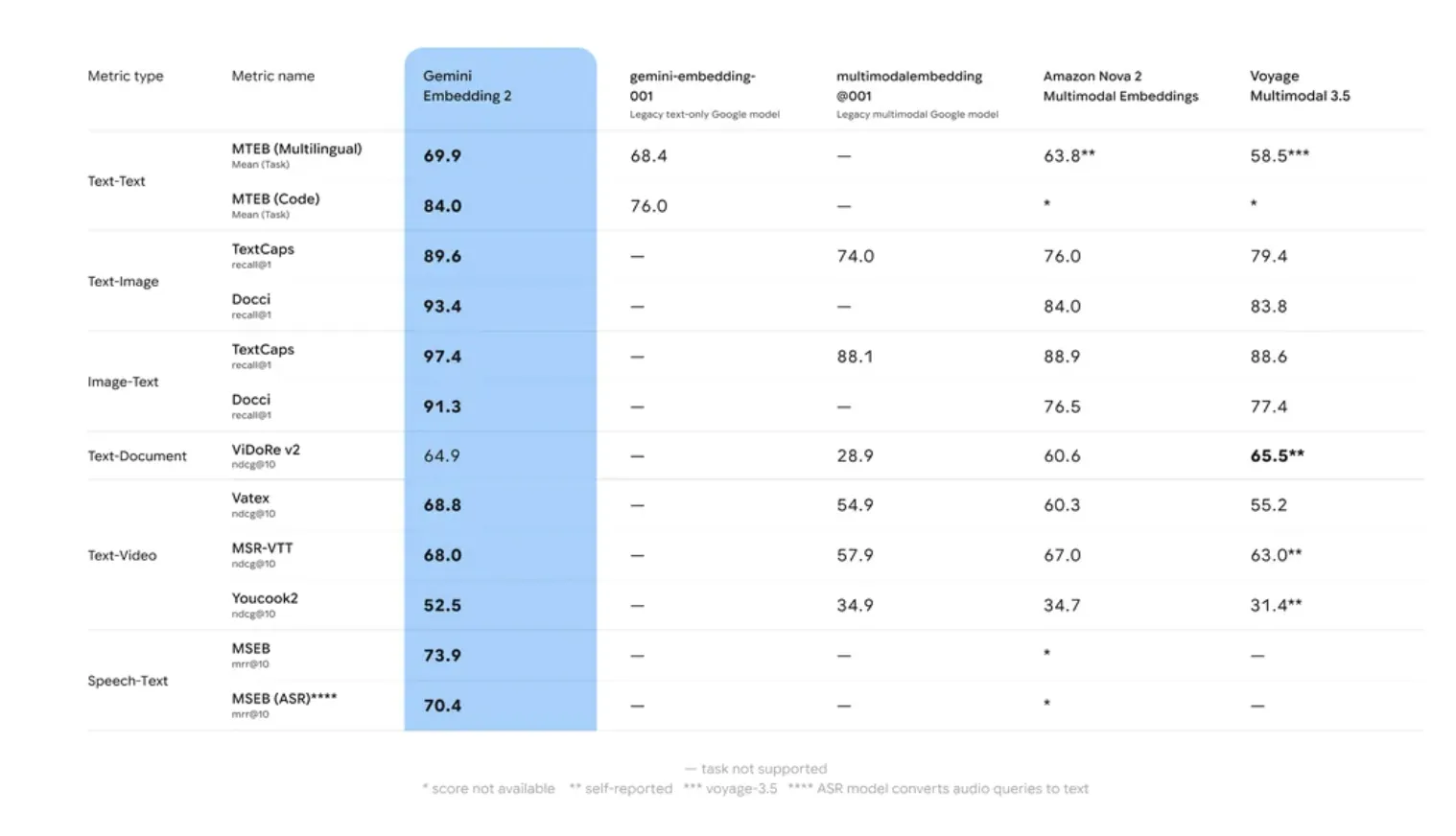
Benchmarking: MTEB and Long Content Retrieval
Internal testing of Google AI and performance of Massive Text Embedding Benchmark (MTEB) show that Gemini Embedding 2 surpasses its predecessor two specific locations: Retrieval Accuracy again Robustness to Domain Shift.
Many embedding models suffer from ‘domain drift,’ where accuracy decreases when moving from general training data (such as Wikipedia) to specialized domains (such as proprietary code bases). Gemini Embedding 2 used a multi-stage training process combining various data sets to ensure high zero-shot performance in all special operations.
Model 8,192-tokens window Key specifications of RAG. It allows the embedding of larger ‘chunks’ of text, which preserves the context needed to resolve references and distance dependencies within the document. This reduces the likelihood of ‘content fragmentation,’ a common problem where a returned component lacks the information needed for LLM to generate a coherent response.
Key Takeaways
- Native Multimodality: Gemini Embedding 2 supports five different media types—Text, Image, Video, Audio, and PDF-within the integral vector space. This allows left input (eg, an image combined with a text caption) that should be processed as a single embedding without separate model pipelines.
- Matryoshka Representation Learning (MRL): The model is designed to store the most important semantic information in the first dimension of the vector. While it happened that 3,072 in sizesupports effective termination to 1,536 or 768 measurements with little loss in accuracy, reducing storage costs and increasing retrieval speed.
- Context and Extended Performance: The model includes i 8,192-token input windowwhich allows for larger text ‘episodes’ in RAG pipes. It shows a significant improvement in performance in Massive Text Embedding Benchmark (MTEB)especially in restoring accuracy and handling specialized domains such as code or technical documentation.
- Job-Specific Development: Developers can use
task_typeparameters (likeRETRIEVAL_QUERY,RETRIEVAL_DOCUMENTorCLASSIFICATION) to provide advice to the model. This improves the properties of vector statistics for a specific function, improving the “hit rate” in semantic search.
Check it out Technical detailsin public preview via Gemini API again Vertex AI. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



