Zipu AI Introduces GLM-OCR: A 0.9B Multimodal OCR Model for Document Analysis and Key Information Extraction (KIE)
")
Why Document OCR Is Still a Difficult Engineering Problem? What does it take to make OCR useful for real documents instead of pure demo images? And can the integrated multimodal model handle analysis, tables, formulas, and systematic output without turning the input into a resource fire?
That’s a target problem GLM-OCRpresented by researchers from Zhipu AI and Tsinghua University. The research team presents GLM-OCR as a 0.9B parametric multimodal model to get an understanding of the document. It includes a 0.4B CogViT virtual encodera lightweight cross-modal connector, and a 0.5B GLM language video. The stated goal is to balance the quality of document recognition with lower latency and lower computational cost than large multimodal systems.
Traditional OCR systems are often good at plain text, but struggle when documents contain complex structures, tables, formulas, code blocks, symbols, and structured fields. Recent large-scale multimodal language models improve document understanding, but the research team argues that their size and standard automatic decoding make them expensive for edge use and large-scale production. GLM-OCR is positioned as a small system built for these deployment constraints rather than as a general-purpose visual language model adapted to OCR as an afterthought.
Compact Architecture Built for OCR Workloads
An important technical point of this study is the use of Multi-Token Prediction (MTP). Conventional automatic decoding predicts one token at a time, which is not suitable for OCR-style tasks where the output is often arbitrary and localized. GLM-OCR instead predicts multiple tokens per step. The model is trained to predict 10 tokens per step and build 5.2 tokens for each recording step on average during the cut-off timeto agree about 50% performance improvement. To keep memory manageable, the implementation uses a parameter sharing scheme across all draft models.
A Two-Stage Layout Analyzes Instead of Reading a Flat Page
At the system level, GLM-OCR uses ia two-stage pipeline. The first phase is implemented PP-DocLayout-V3 through structural analysis, which finds structured regions on a page. The second stage is playing corresponding regional level observations over those lands acquired. This is important because the model doesn’t just read the entire page from left to right like a standard vision language model would. It first divides the page into logically defined regions, which improves efficiency and makes the system more robust for documents with complex layouts.
Document Parsing and KIE Use Different Extraction Methods
The structure also separates two related functions of the document. Because edit the documentThe pipeline uses structural detection and circuit processing to produce uniform structured output Markdown again JSON. Because Key Information Extraction (KIE)the research team describes a different method: the full image of the document is given to the model by the task notification, and the model produces it directly JSON which contains the extracted fields. That distinction is important because GLM-OCR was not presented as a single page-to-text model. It is a systematic production system with different work methods depending on the job.
A four-stage Training Pipeline with job-specific rewards
The training recipe is divided into 4 sections. Stage 1 trains a vision encoder on pairs of text and underlying or retrieval data. Section 2.1 perform multimodal pretraining on image text, document segmentation, localization, and VQA data. Section 2.2 adds the MTP objective. Stage 3 it is aimed at optimizing OCR-specific tasks including text recognition, formula typing, table structure detection, and KIE. Section 4 uses to reinforce learning using GRPO. Reward design is task-specific: Standard editing range text recognition, CDM score to recognize the formula, TEDS score table recognition, and field level F1 of KIE, and structure penalties such as repetition penalties, incorrect structure penalties, and JSON validation limits.
Benchmark Results Show Solid Performance, With Important Caveats
In public benchmarks, GLM-OCR reports strong results across several document operations. It scores 94.6 to OmniDocBench v1.5, 94.0 to OCRBench (Text), 96.5 to UniMERNet, 85.2 to PubTabNetagain 86.0 to TEDS_TEST. For KIE, it is reporting 93.7 to Nanonets-KIE again 86.1 to Handwritten-KIE. The research team notes that the results of Gemini-3-Pro again GPT-5.2-2025-12-11 they are shown for reference only and are not included in the ranking of the best scores, which are important details when making claims about exemplary leadership.
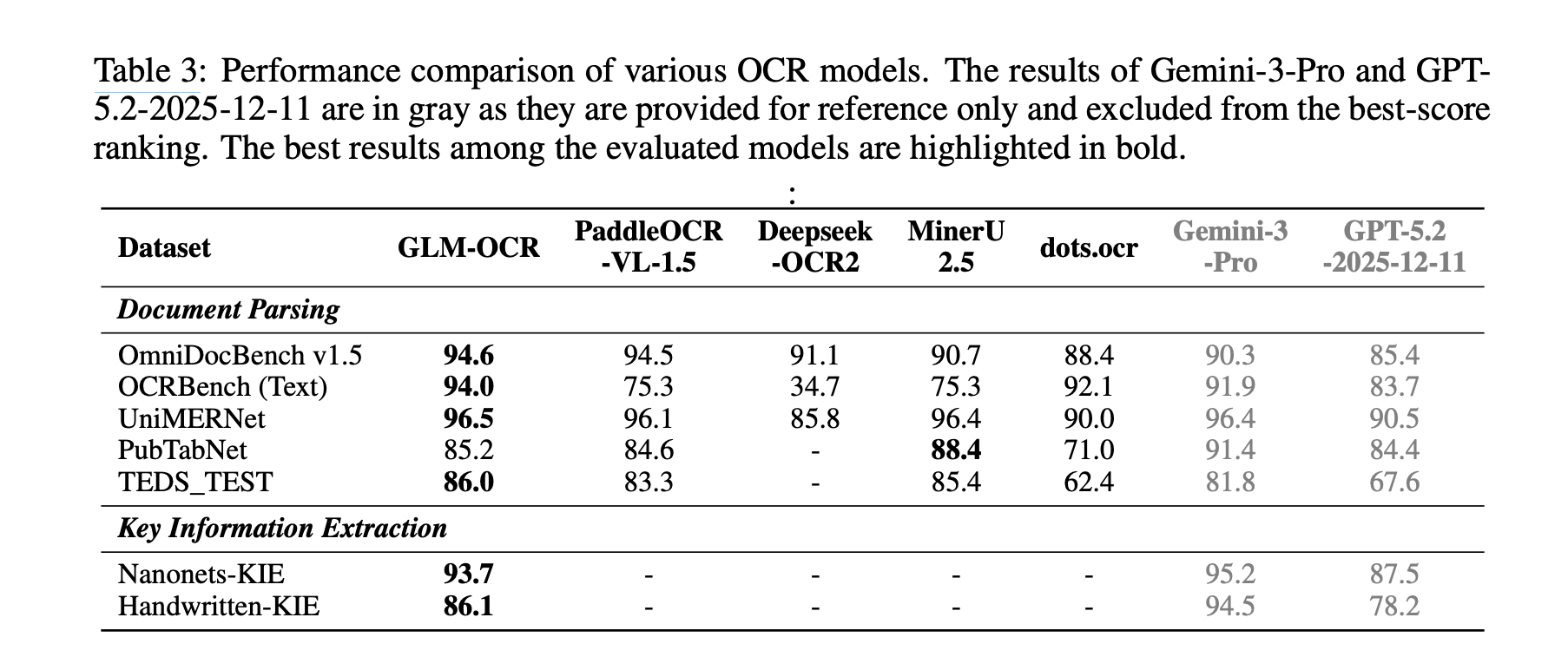
The matter of standing is strong, but it needs to be phrased carefully. GLM-OCR achieves the highest reported score among the no-reference models tested OmniDocBench v1.5, OCRBench (Text), UniMERNetagain TEDS_TEST. Opened PubTabNetHowever, it does happen not general lead; MinerU 2.5 reports 88.4 against GLM-OCR’s 85.2. For KIE, GLM-OCR outperforms the open source competitors listed in the table above, but Gemini-3-Pro high score on both Nanonets-KIE again Handwritten-KIE in the reference column. So the reserach team supports a strong competitive claim, but not a ‘best of all’ claim.
Shipping Details
The research team claims that GLM-OCR is supportive vLLM, SGlangagain Ollamaand can be properly processed LLaMA-Factory. They also report on the release of 0.67 images/s again 1.86 pages/s under the arrangement of their examination. In addition, they define a MaaS API that has its own value 0.2 RMB per million tokensfor example cost estimates for scanned images and PDFs with a simple layout. These findings suggest that GLM-OCR has been developed as a research model and a usable system.
Key Takeaways
- GLM-OCR is a 0.9B multimodal joint OCR model built with 0.4B CogViT Encoder again 0.5B GLM decoder.
- Using Multi-Token Prediction (MTP) improving recording efficiency, access 5.2 tokens per step on average and about 50% higher output..
- The model uses a two-stage pipeline: PP-DocLayout-V3 handles the structural analysis, and GLM-OCR performs the corresponding region-level visualization.
- It supports both document classification and KIE: output analysis Markdown/JSONwhile KIE produces directly JSON from the image of the complete document.
- The benchmark results are strong but not winning everywhere: GLM-OCR leads non-reference benchmarks reported, but MinerU 2.5 is up to PubTabNetagain Gemini-3-Pro it is higher than the reference KIE score only.
Check it out Paper, Repo again Model Page. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



