Alibaba’s Tongyi Lab Releases VimRAG: A Multimodal RAG Framework Using Memory Graph to Navigate Large Virtual Machines

Retrieval-Augmented Generation (RAG) has become a common method for embedding large-scale linguistic models in external knowledge – but when you go beyond plain text and start mixing images and videos, the whole approach starts to converge. Virtual data is token-difficult, not readily available relative to a specific query, and grows unfathomably fast during multi-step reasoning. Researchers at Tongyi Lab, Alibaba Group have launched ‘VimRAG’, a framework designed specifically to address that disruption.
Problem: linear history and compressed memory both fail with physical data
Most RAG agents today follow a Caught-Action-Observation loop – sometimes called ReAct – where the agent aggregates its full history of interactions into one growing context. Officially, at step t the history is Ht = [q, τ1, a1, o1, …, τt-1, at-1, ot-1]. For tasks involving videos or visually rich documents, this is quickly not possible: information density is a critical consideration |Ocriticism|/|Ht| it falls to zero as the steps of reasoning increase.
A natural response is memory-based compression, where the agent compresses past observations into a compact state mt. This keeps the density stable at |Ocriticism|/|mt| ≈ C, but introduces Markovian blindness — the agent loses track of what it has already queried, leading to repeated searches in multiple hop instances. In a pilot study comparing ReAct, iterative summarization, and graph-based memory using Qwen3VL-30B-A3B-Instruct in a video corpus, summarization-based agents suffered from visual blindness in the same way as ReAct, while graph-based memory significantly reduced unwanted search actions.
A second pilot study tested four cross-modality memory strategies. Front captions (text → text) use only 0.9k tokens but only reach 14.5% for image tasks and 17.2% for video tasks. Saving green virtual tokens uses 15.8k tokens and achieves 45.6% and 30.4% – noise over signal. The context-aware caption compresses the text and improves to 52.8% and 39.5%, but loses the finer details needed for validation. Ending by selecting only the most important idea tokens – Semantically Related Visual Memory – uses 2.7k tokens and reaches 58.2% and 43.7%, the best trade. A third study evaluating credit allocation found that in positive trajectories (reward = 1), about 80% of the steps contain noise that can incorrectly detect a positive gradient signal under the standard RL based on the result, and that removing unnecessary steps from the wrong trajectories completely restored performance. These three results are directly encouraging Three main components of VimRAG.
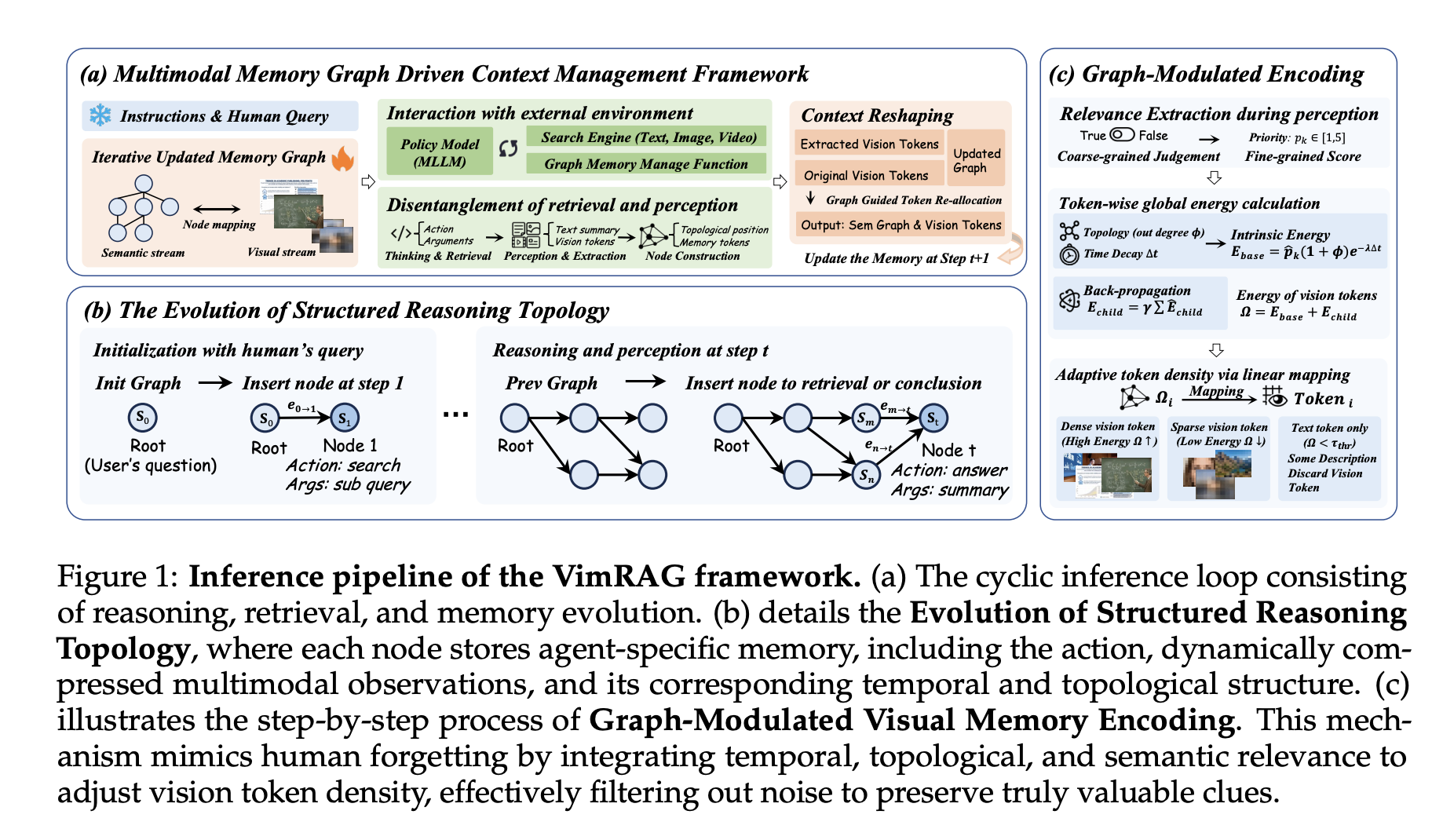
Three-part construction of VimRAG
- I the first part the Multimodal Memory Graph. Rather than a flat history or compressed summary, the reasoning process is modeled as a strongly directed acyclic grapht(VtEt) Each area vi consists of a tuple (pi,qisimi): the parent node indexes encoding the local dependency structure, a small decomposed query associated with the search action, a short text summary, and a multimodal episodic memory bank of visual tokens from retrieved or independent documents. At each step the policy samples come from three types of actions: aret (experimental retrieval, revealing a new area and making a small question), amem (many kinds of perception and the amount of memory, splitting the raw perception into a summary of st and virtual tokens mt using a coarse-to-fine binary saliency mask u {0,1} and a fine semantic output p ∈ [1,5]), and ai (terminal conjecture, made when the graph contains sufficient evidence). Watching videos, amem uses Qwen3-VL’s temporal support capabilities to extract keyframes aligned with timestamps before filling the space.
- I the second part is a Graph-Modulated Visual Memory encoding, which treats token assignment as a block resource allocation problem. For each visible object mI, kthe internal energy is calculated as Eint(mI, k) = p̂I, k · (1 + deg+G(vi)) · exp(−λ(T − ti)), combining semantic importance, node out-degree structural validity, and temporal decomposition to reduce old evidence. The final strength adds the reciprocating reinforcement from the following nodes: it maintains the first basic nodes that support the assumption of high value of the river. Token budgets are distributed proportionally to the power scores in the global top-K selection, and the total budget of the S resource.totality = 5 × 256 × 32 × 32. Dynamic allocation is allowed only at the time of decision; average training of pixel values in the memory bank.
- I one third Graph-Guided Policy Optimization (GGPO). For good samples (reward = 1), the gradient mask is applied to the dead-end nodes and not to the critical path from the root to the response point, to prevent the positive reinforcement of unwanted returns. For negative samples (reward = 0), steps where the retrieval results contain relevant information are excluded from the evaluation of the negative policy gradient. A binary pruning mask is defined as . Ablation ensures that this produces faster assimilation and more stable reward curves than baseline GSPO without castration.
Results and availability
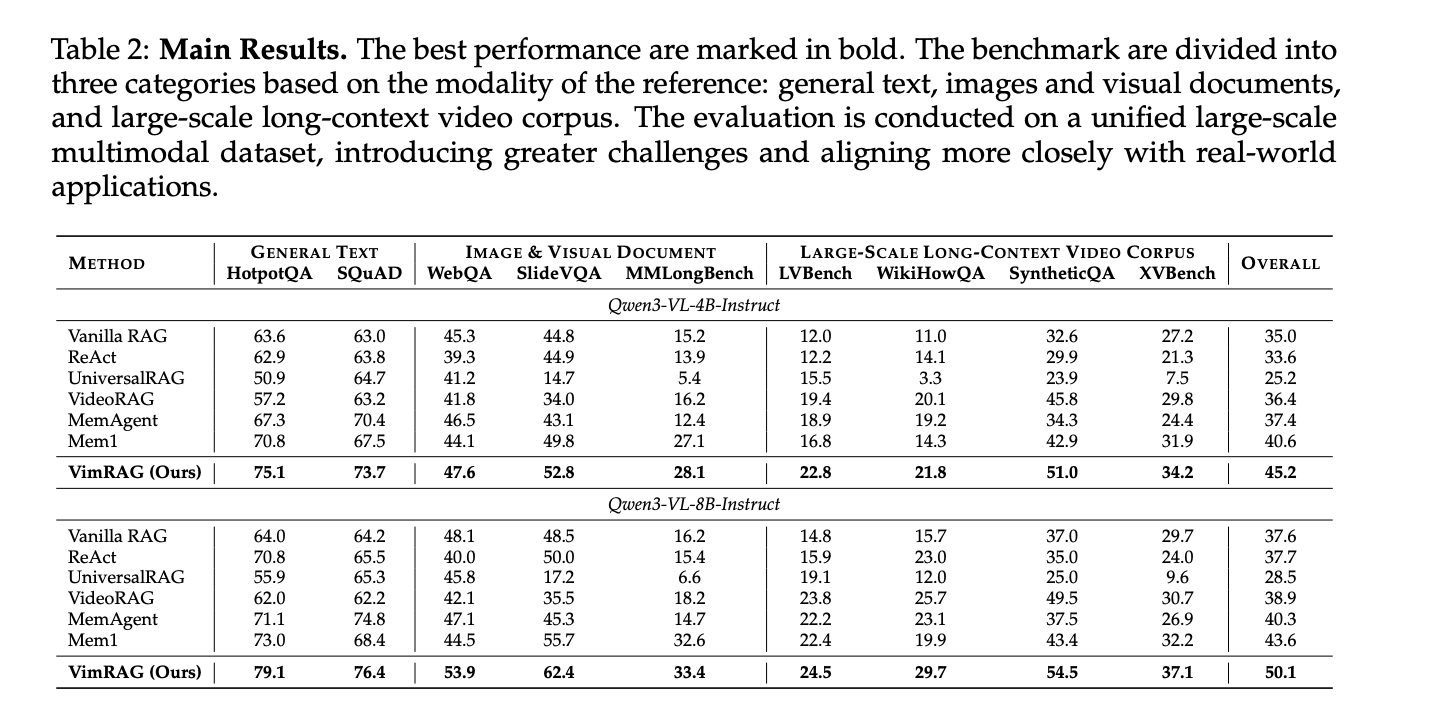
VimRAG was tested on all nine benchmarks – HotpotQA, SQuAD, WebQA, SlideVQA, MMLongBench, LVBench, WikiHowQA, SyntheticQA, and XVBench, a new video benchmark created by the HowTo100M research team to address the lack of understanding of video measurement. All nine datasets were combined into one combined corpus of approximately 200k cross-modal objects, making the analysis complex and representative of real-world conditions. The GVE-7B served as an embedding model that supports text-to-text, image, and video retrieval.
For Qwen3-VL-8B-Instruct, VimRAG gets a total score of 50.1 compared to 43.6 for Mem1, the previous best baseline. In Qwen3-VL-4B-Instruct, VimRAG scored 45.2 compared to Mem1’s 40.6. In SlideVQA with 8B core, VimRAG reaches 62.4 compared to 55.7; in SyntheticQA, 54.5 versus 43.4. Besides introducing a dedicated detection step, VimRAG also reduces the total path length compared to ReAct and Mem1, because structured memory prevents repeated reads and invalid searches that cause linear paths to accumulate a heavy tail of token consumption.
Key Takeaways
- VimRAG replaces the direct interaction history with a directed acyclic graph (Multimodal Memory Graph) which tracks the agent’s mental state at every step, preventing repetitive queries and situational blindness that plagued conventional ReAct and abstraction-based RAG agents when handling large volumes of physical data.
- Graph-Modulated Virtual Coding solves the virtual token budgeting problem by assigning high-resolution tokens to the most important returned evidence based on semantic relatedness, topological location in the graph, and temporal decomposition – rather than treating all returned images and video frames at the same resolution.
- Graph-Guided Policy Optimization (GGPO) corrects a fundamental flaw in the way RAG agent models are trained – Standard outcome-based rewards unfairly penalize good recovery steps in a failed route and unfairly reward redundant steps for successful ones. GGPO uses graph structure to hide those misleading gradients at the step level.
- An experimental study using four cross-modality memory strategies showed that selectively storing relevant visual tokens (Semantically-Related Visual Memory) achieves the best trade-off between accuracy and efficiency.it achieves 58.2% for image tasks and 43.7% for video tasks with only 2.7k average tokens – outperforming both raw virtual storage and text-only compression methods.
- VimRAG passes all benchmarks in all nine benchmarks on a combined corpus of nearly 200k text, image, and video objectsobtained 50.1 overall for Qwen3-VL-8B-Yala compared to 43.6 for the previous best Mem1 basis, while also reducing the total length of the inference trajectory despite adding a multimodal vision step.
Check it out Paper, Repo again Model weights. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



