Zyphra Introduces Tensor and Sequence Parallelism (TSP): A Hardware-Aware Training and Inference Strategy That Delivers 2.6x Throughput Over Match TP+SP Baselines
: A Hardware-Aware Training and Inference Strategy That Delivers 2.6x Throughput Over Match TP+SP Baselines")
Training and rendering large scale transformer models is a memory management problem. Every GPU in the collection has a fixed amount of VRAM, and as the model numbers and core length increase, developers always have to make changes in how to distribute the work across the hardware. A a new way from Zyphrait was called Tensor and Sequence Parallelism (TSP), offers a way to rethink that trade-off – and in benchmark tests of up to 1,024 AMD MI300X GPUs, it consistently delivers lower memory per GPU than any standard parallelization programs used today, for both training and benchmarking workloads.
TSP Problem Solved
To understand why TSP is important, you must first understand the two parallel strategies that it combines.
Tensor Parallelism (TP) distributes the model weights across GPUs. If you have a weight matrix in an attention or MLP layer, each GPU in the TP group holds a small part of that matrix. This directly reduces the memory of each GPU that is occupied by parameters, gradients, and optimizer states — ‘model state’ memory. The trade-off is that TP requires a joint communication operation (usually minimize all or minimize scatter/collect pairs) every time a layer is computed. This correlation is proportional to the size of the activation, so it becomes more expensive as the length of the sequence increases.

Sequence Compatibility (SP) takes a different approach. Instead of dividing the weights, it divides the input token sequence across GPUs. Each GPU processes only a small portion of the tokens, which reduces the memory usage and the quadratic cost of computing attention. However, SP leaves the model weights fully replicated across GPUs, meaning that the model’s state memory remains exactly the same no matter how many GPUs you add to the SP group.
For multi-dimensional parallelism, engineers combine TP and SP by placing them on the orthogonal axes of the device mesh. If you want a TP degree of T and an SP degree of Σ, your graphics model uses T.Σ GPUs. This is expensive in two ways. First, it uses multiple GPUs in a parallel-model group, leaving few available for parallel data replicas. Second, if T.Σ is large enough to connect multiple nodes, some cluster communication should be slower in inter-node connections such as InfiniBand or Ethernet instead of high-bandwidth intra-node fabric, such as AMD Infinity Fabric or NVIDIA NVLink. Data Parallelism (DP), another common basis, avoids these parallel model costs entirely but replicates the entire model on all devices, making it impossible for large models or remote content alone.
What Does Wrapping Really Mean?
The main idea of TSP is parallel folding: instead of placing TP and SP in different, orthogonal mesh dimensions, it folds both on the mesh axis of a single device of size D. Every GPU in the TSP group simultaneously handles 1/D of the model weights and 1/D of the token sequence. Because they are both shared on the same D GPUs, each device’s memory is reduced by 1/D in both parameter memory and activation memory – something that no single standard parallelization scheme achieves on its own. TSP is therefore the only scheme that simultaneously reduces the memory of the weighting equation (parameters, gradients, optimizer conditions) and the activation memory with the same 1/D factor in one axis without requiring a two-dimensional T.Σ device structure.
The challenge is that if each GPU only has a weights part and a sequence part, it needs to work with other GPUs to complete the forward pass of each layer. TSP uses two separate communication schedules to handle this, one for attention and one for gated MLP.
To get attention, TSP multiplies more than letters of weight. At each step, one GPU broadcasts its weight charts (WQ, WK, WV, and WO) to all other GPUs in the group. Each GPU then applies those weights to its local sequence tokens to calculate local predictions for Q, K, and V. Since causal attention requires access to the full key/value context, the local K and V tensors are collected across the TSP group and rearranged using a zigzag partitioning scheme before FlashAttention is invoked. The division of zigzags ensures that the load of causal attention is equal at all levels, since the later tokens take care of larger initializations and can cause load imbalance.
With a gated MLP, the TSP uses a ring schedule. Each GPU starts with local gate, top, and bottom charts. These shards rotate around the TSP cluster with point-to-point send/recv operations, and each GPU accumulates partial outputs locally as shards arrive. Importantly, this eliminates all the reductions required by standard TP in MLP output – the sequence remains in place, and only the weights move. The ring is designed to bypass the weight transfer and computation of GEMM, so the communication happens in the background while the GPU is doing the computation.
Memory and output results
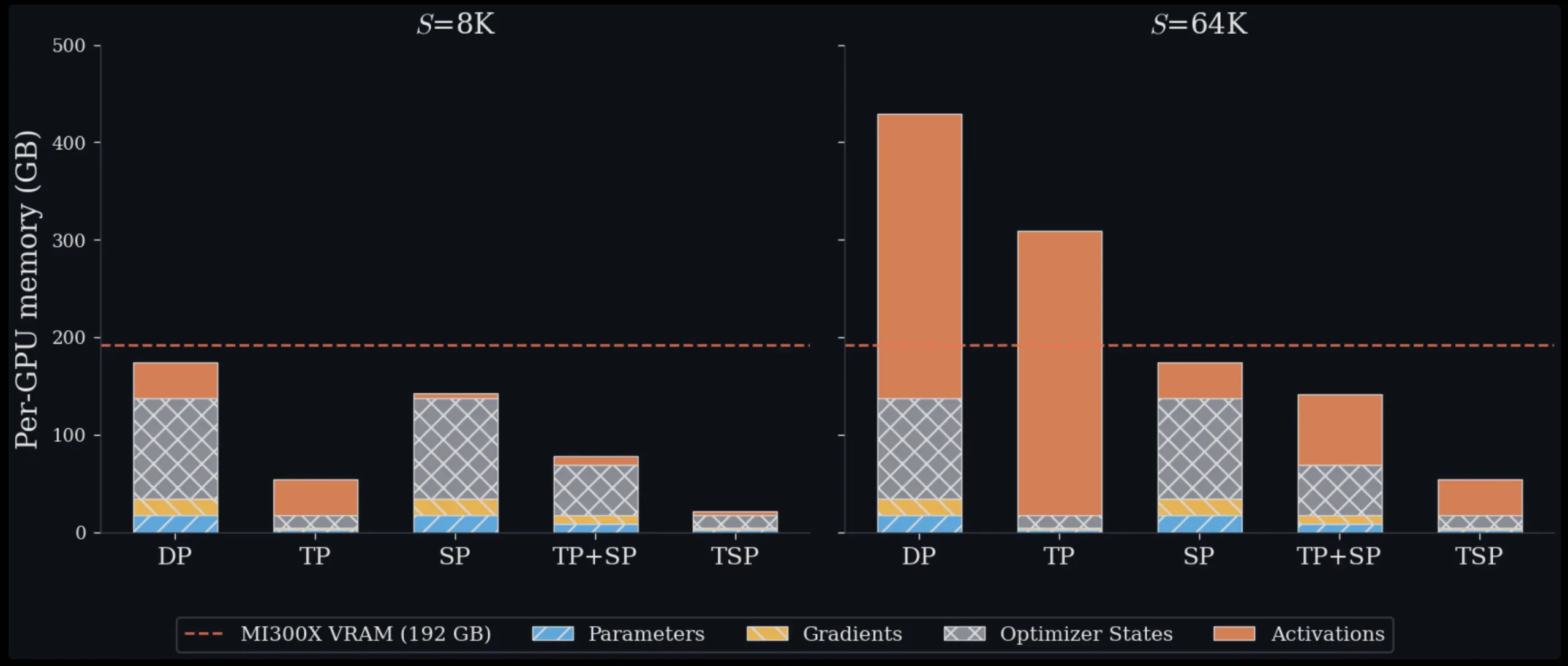
Tested on a single 8-GPU MI300X environment for all sequence lengths from 16K to 128K tokens, TSP achieves the highest memory minimum in all areas. At 16K tokens, TSP and TP are almost equal, 31.0 GB versus 31.5 GB per GPU, because model state memory dominates in the short case. At 128K tokens, the picture changes significantly: TSP uses 38.8 GB per GPU, compared to 70.0 GB for TP and 85.0 GB and 140.0 GB for the two separate TP+SP components in one environment. Theoretical calculations throughout this study are based on the 7B dense decoder reference model only (hidden dimensions h=4096, 32 layers, 32 query heads, 32 KV heads, FFN expansion factor F=4, bf16 accuracy), which provides a reproducible basis for system comparison.
The result results on 128 full nodes (1,024 MI300X GPUs) show TSP performs consistently as well as the same TP+SP baseline. With a folded rate of D=8 and a sequence length of 128K tokens, TSP achieves 173 million tokens per second compared to 66.30 million tokens per second for the TP+SP benchmark (about 2.6x speed). The benefit increases with higher parallelism degree and longer sequence length.

Effective Trade-offs to Understand
TSP increases communication volume compared to TP alone. It adds a mass motion term each layer on top of the same K/V combination set used by SP. However, the research team shows that if the cluster size B and sequence length S satisfy BS > 8h (where h is the embedding size of the model), the forward communication volume of TSP is competitive with TPs. This condition is met with long context training and hypothetical situations.
An important understanding that the Zyphra team emphasizes is that communication capacity and communication costs are not the same. Whether the increased communication volume translates into reduced wall-clocking depends on whether the clusters are delayed by latency or bandwidth-constrained, and how much of that traffic can be buried with matrix replication. Their weighting pipelines are routed behind the outstanding GEMM functions so that weighted communication consumes bandwidth without adding to critical time.
TSP is not designed to replace TP, SP, or TP+SP in all settings. It is intended as an additional axis in the design space of multi-dimensional similarity. It combines orthogonally with pipeline similarity, expert similarity, and data similarity. This means that groups can apply TSP to existing parallel configurations wherever standard architecture would force groups of identical models across slow links between nodes.
Key Takeaways
- Zyphra’s Tensor and Sequence Parallelism (TSP) wraps tensor and sequence parallelism into a single device mesh axis, so each GPU simultaneously handles 1/D of model weights and 1/D of token sequences, reducing memory overhead for both training and rendering.
- TSP is the only parallelization scheme that reduces both weight-related memory (parameters, gradients, optimizer conditions) and activation memory with the same 1/D factor in one axis, without requiring a two-dimensional T.Σ device net.
- Efficiency results on a single node of the 8-GPU MI300X show TSP using 38.8 GB per GPU with a sequence length of 128K, compared to 70.0 GB for TP and 85.0–140.0 GB for the TP+SP configuration.
- At large scale (1,024 MI300X GPUs, 128K core, D=8), TSP achieves 173 million tokens per second compared to 66.30 million tokens per second on a simulated TP+SP basis (about 2.6x output gain).
- TSP combines orthogonally with pipe, expert, and data compatibility and is better suited than long context, delayed memory training and targeting load when eliminating weight and activating repetition outweighs additional communication volume.
Check it out Paper again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



