Alibaba Qwen Team Releases Qwen3.5 Omni: A Native Multimodal Model for Text, Audio, Video, and Real-Time Interaction

The landscape of large multimodal linguistic models (MLLMs) has shifted from experimental ‘wrappers’—where separate visual or audio encoders are sewn onto a text-based core—to native, end-to-end ‘omnimodal’ architectures. Alibaba Qwen’s latest team, Qwen3.5-Omnirepresents a milestone in this evolution. Designed as a direct competitor to flagship models such as the Gemini 3.1 Pro, the Qwen3.5-Omni series presents an integrated framework capable of processing text, images, audio, and video simultaneously within a single computing pipeline.
The technical significance of Qwen3.5-Omni lies in it Thought-Speaker properties and its use Mix of Professional Attention (MoE) in all ways. This approach allows the model to handle large context windows and real-time interactions without the typical latency penalties associated with cascaded systems.
Model Tiers
The series is offered in three sizes to balance performance and cost:
- Additional: Complex reasoning and high precision.
- Flash: Optimized for high interoperability and low latency.
- Light: A small exception is efficiency-oriented activities.
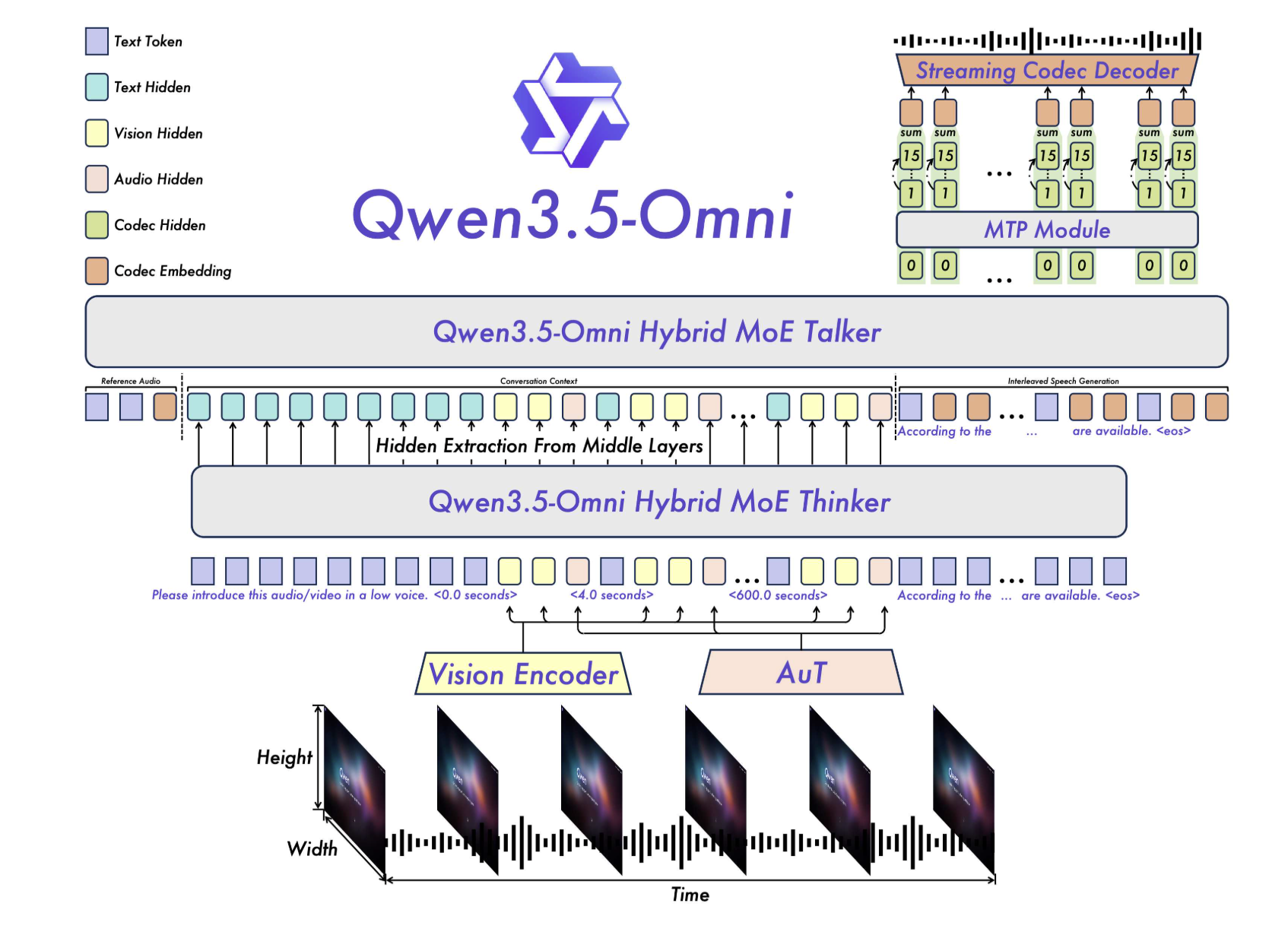
The Thinker-Talker Architecture: An Integrated Framework for MoE
At the core of Qwen3.5-Omni is a dual but tightly integrated architecture consisting of two main components: A thinker as well as The speaker.
In previous iterations, multimodal models often relied on pre-trained external encoders (such as Whisper for audio). Qwen3.5-Omni goes beyond this by using native Audio Transformer (AuT) encoder. This coder was previously trained in more than that 100 million hours of audio and visual data, providing the model with a ground-based understanding of temporal and acoustic nuances that original text models lack.
Mix of Professional Attention (MoE)
Both the Thinker and the Speaker benefit Hybrid-Attention MoE. In a typical MoE setup, only a small set of parameters (‘experts’) are valid for any given token, allowing for high parameter computation with low computational cost. By using this in a mixed attention machine, Qwen3.5-Omni can effectively measure the importance of different methods (eg, focusing more on visual tokens during a video analysis task) while maintaining the required output for streaming services.
This structure supports 256k long content inputs, allowing the model to import and think more:
- It’s over 10 hours of continuous sound.
- It’s over 400 seconds of 720p audio and visual content (sample at 1 FPS).
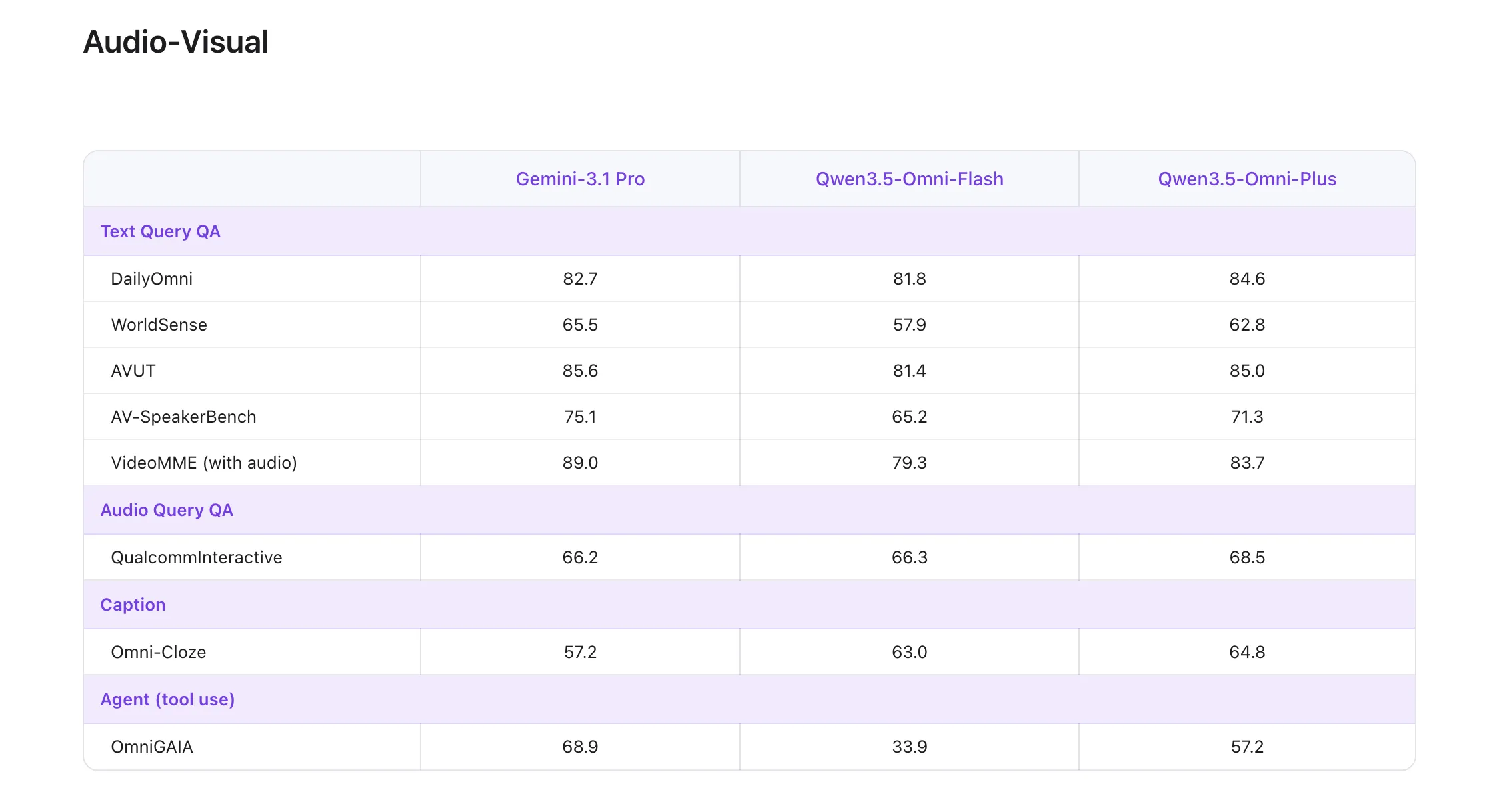
Rating Performance: The Milestone of ‘215 SOTA’
One of the most highlighted technical claims about the flagship Qwen3.5-Omni-Plus model its performance on the world leaderboard. The model has been achieved State-of-the-Art (SOTA) results on 215 audio-visual comprehension, reasoning, and interaction subtasks..
This 215 SOTA win is not only an average of extensive testing but specific technical benchmarks including:
- 3 audio and visual benchmarks again 5 standard audio benchmarks.
- 8 ASR (Automatic Speech Recognition) benchmarks.
- 156 language-specific speech-to-text (S2TT) functions.
- 43 language-specific ASR functions.
According to their official technical reports, Qwen3.5-Omni-Plus passes Gemini 3.1 Pro in general understanding of sound, thinking, recognition, and interpretation. In terms of audio and visual understanding, it reaches the level of Google’s flagship, while maintaining the main text and visual performance of the standard Qwen3.5 series.
Technology Solutions for Real-Time Interaction
Building a model that can ‘talk’ and ‘hear’ in real time requires solving some engineering challenges related to broadcast stability and conversation flow.
ARIA: Dynamic Break Rate Alignment
A common failure mode in voice transmission is ‘speech instability.’ Because text tokens and speech tokens have different encoding functions, the model may misread numbers or stutter when trying to match its text logic with the audio output.
To deal with this, the Alibaba Qwen team has developed ARIA (Adaptive Interval Alignment). This process dynamically aligns text and speech units during production. By adjusting the pause rate based on the amount of information being processed, ARIA improves the naturalness and robustness of speech synthesis without increasing latency.
Semantic interference and opportunism
For AI engineers who build voice assistants, managing distractions is especially difficult. Qwen3.5-Omni introduces native recognition of the intention to turn. This allows the model to distinguish between ‘backchanneling’ (meaningless background noise or the listener’s response such as ‘uh-huh’) and real semantic interference that the user intends to take down. This capability is baked directly into the model’s API, allowing for human-like, bidirectional conversations.
Evolving Powers: Coding Audio-Visual Vibe
Perhaps the most unique feature identified during the multimodal measurement of the Qwen3.5-Omni is Audio-Visual Vibe Coding. Unlike traditional code generation that relies on text input, Qwen3.5-Omni can perform coding tasks based directly on audio and visual instructions.
For example, a developer can record a video of the software’s UI, describe the bug verbally while pointing out specific features, and the model can directly generate a fix. This finding suggests that the model developed a different mode mapping between the visual UI categories, the verbal intention, and the logic of the symbolic code.
Key Takeaways
- Qwen3.5-Omni uses native Thought-Speaker a multimodal architecture for integrated text, audio, and video processing.
- The model supports 256k context, 10+ hours of audioagain 400+ seconds of 720p video of 1FPS.
- Alibaba reports speech recognition in 113 languages/dialects again speech production in 36 languages/dialects.
- The main features of the system include semantic disorder, recognition of the intention to turn, TMRoPEagain ARIA through real-time interaction.
Check it out Technical details, Qwenchat, online demo on HF again Offline demo on HF. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



