
Google recently launched Gemini Embedding 2, its first multimodal embedding model. This is a significant step forward because it brings text, images, video, audio, and documents into one shared embedding environment. Instead of working with separate models for each type of data, developers can now use a single embedding model across multiple methods to retrieve, search, aggregate, and classify.
That change is powerful in theory, but it’s even more interesting when implemented in a real project. To test what Gemini Embedding 2 can do in practice, I built a simple image matching program that identifies which person in the query image is most similar to the stored images.
Gemini Embedded 2 Key Features
Traditional embedding programs are usually designed for text alone. If you wanted to build a system that worked on all images, audio, or documents, you often had to integrate multiple pipelines. Gemini Embedding 2 changes that by mapping different types of content into a single embedded vector.
According to Google, Gemini Embedding 2 supports:
- Text with up to 8192 input tokens
- Images, with up to 6 images per request in PNG and JPEG format
- Video up to 120 seconds in mp4 and mov
- Audio without needing to record first
- PDF documents are up to 6 pages in length
It also supports multi-modal input, such as image and text in one application. This allows the model to capture rich relationships between different types of data.
Another important feature is the flexibility of dimensionality output through Matryoshka Representation Learning. The default size is a maximum of 3072, but can be reduced to smaller sizes such as 1536 or 768. This helps developers balance quality, storage, and retrieval speed depending on the application.
Also Read: 14 Powerful Ways That Explain The Evolution Of Embedding
Building an Image Matching Program Using Gemini 2 Embedding
The project uses three folders within the dataset directory:
dataset/
nitika/
vasu/
janvi/
Each folder contains multiple photos of the same person. The goal is straightforward:
- Read all the images in the dataset
- Generate individual image embeds using Gemini Embedding 2
- Save what’s embedded in memory and save it locally
- Take a picture of the question
- Generate its embedding
- Compare all embeddings of stored images using cosine similarity
- Retrieve the top matching pictures and guess the person’s name
This is a solid example of how Gemini Embedding 2 can be used for image-based retrieval and lightweight classification.
The best part of this project is that it doesn’t require a full deep learning pipeline. No custom CNN training, no fine-tuning, and no annotation-heavy workflow. Instead, the system relies on the embedding model as a semantic feature generator.
That makes development much faster.
Since Gemini Embedding 2 is multimodal by nature, the same project design can later be extended beyond graphics. For example:
- Matching a spoken audio clip to a person’s profile
- Searches for a PDF that matches the image
- Returns the video part of the text query
- Comparing mixed images and text descriptions in a single embedding
In this sense, the current project is an easy entry point into the broader structure of multimodal recovery.
Gemini Embedding 2 API Use
Google provides the Gemini Embedding 2 model with Gemini API and Vertex AI. The embedding call is made with embed_content way.
A multimodal example from Google looks like this:
from google import genai
from google.genai import types
client = genai.Client()
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
],
)
print(result.embeddings) For my project, I only needed the graphical part of this workflow. Instead of sending text, image, and audio together, I used one image per request and generated an embed for it.
Project Implementation
The project starts by loading the Gemini API key from the .env file and creating the client:
from dotenv import load_dotenv
import os
from google import genai
load_dotenv()
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
client = genai.Client(api_key=GEMINI_API_KEY) I then explained the helper functions for image validation, MIME type detection, normalization, cosine matching, and image display.
The main embedding function reads the image bytes and sends them to Gemini Embedding 2:
def embed_image(image_path):
image_path = Path(image_path)
mime_type = guess_mime_type(image_path)
with open(image_path, "rb") as f:
image_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type=mime_type,
)
],
config=types.EmbedContentConfig(
output_dimensionality=3072
)
)
emb = np.array(result.embeddings[0].values, dtype=np.float32)
return normalize(emb) This function is the backbone of all pipelines. It converts each image into a 3072-dimensional vector representation.
Building a Database for Embedding a Data Set
The next step is to go to the dataset folder, read all the individual images, and embed them one by one.
Each embedded image is stored as a dictionary containing:
- a person’s label
- file path
- the embedding vector
To avoid recalculating the embed every time, I cached it in a local pickle file:
def build_embeddings_db(dataset, cache_file="image_embeddings_cache.pkl", force_rebuild=False):
cache_path = Path(cache_file)
if cache_path.exists() and not force_rebuild:
with open(cache_path, "rb") as f:
embeddings_db = pickle.load(f)
return embeddings_db
embeddings_db = []
for item in dataset:
emb = embed_image(item["path"])
embeddings_db.append({
"label": item["label"],
"path": item["path"],
"embedding": emb
})
with open(cache_path, "wb") as f:
pickle.dump(embeddings_db, f)
return embeddings_dbThis makes the notebook more efficient because the embedding is generated only once unless the data set changes.
Matching Question Picture
Once the dataset embedding is ready, the next step is to test the system with a new query image.
The question image is embedded using the same function. Then its embedding is compared to all stored embeddings using cosine similarity.
def find_best_matches(query_image_path, top_k=5):
query_emb = embed_image(query_image_path)
results = []
for item in embeddings_db:
score = cosine_similarity(query_emb, item["embedding"])
results.append({
"label": item["label"],
"path": item["path"],
"score": score
})
results.sort(key=lambda x: x["score"], reverse=True)
return results[:top_k] This function returns the top matching images of the data set.
To predict the last person’s label, I used high-k voting:
def predict_person(query_image_path, top_k=5):
matches = find_best_matches(query_image_path, top_k=top_k)
labels = [m["label"] for m in matches]
predicted_label = Counter(labels).most_common(1)[0][0]
return predicted_label, matches This is more stable than relying on a single close-up image.
Project Evaluation
In the project, I tested images for questions like these:
Example 1:
query_image = "Nitika_Test_Image.jpeg"
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery image:")
show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person)
print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | score={match['score']:.4f} | path={match['path']}")
show_image(match["path"], title=f"Rank {i} | {match['label']} | score={match['score']:.4f}")
print("nBest match:")
print(matches[0])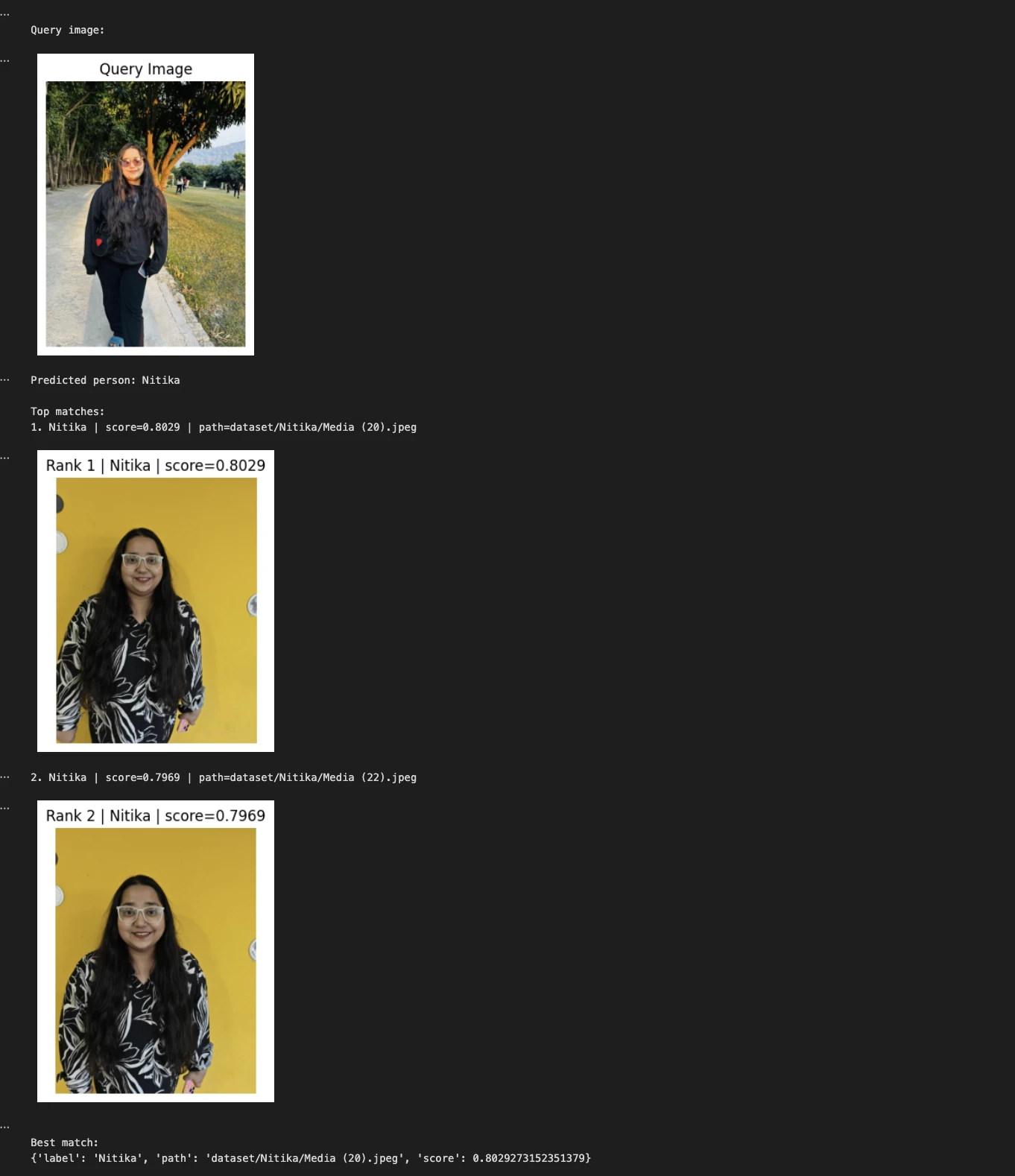
Example 2:
query_image = "/Users/janvi/Downloads/Him.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=2)
print("nQuery image:") show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person) print("nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | score={match['score']:.4f} | path={match['path']}") show_image(match["path"], title=f"Rank {i} | {match['label']} | score={match['score']:.4f}")
print("nBest match:") print(matches[0])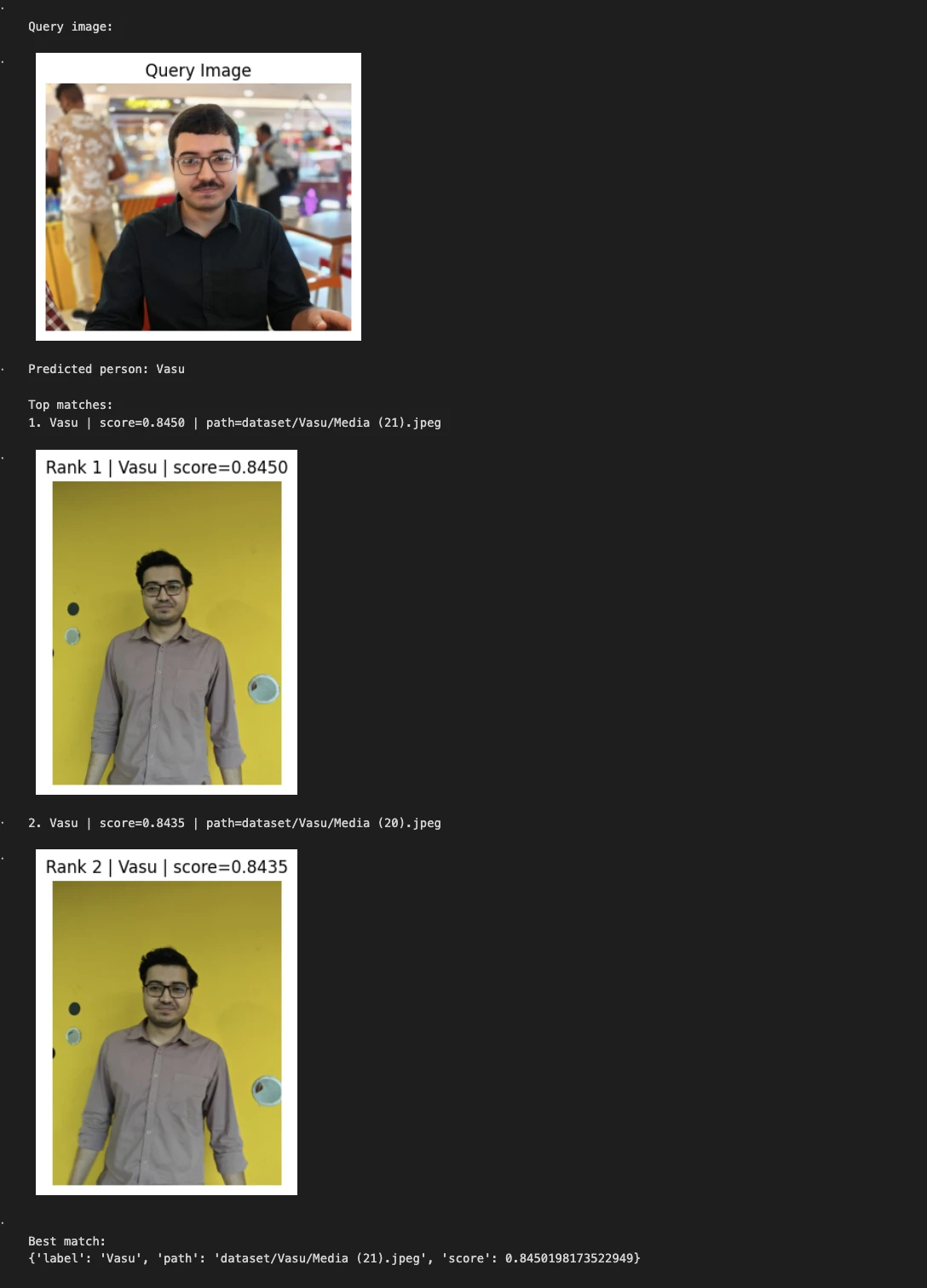
A third example:
query_image = "/Users/janvi/Downloads/Nerd.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=5)
print("nQuery image:")
show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person)
print("nTop matches:")
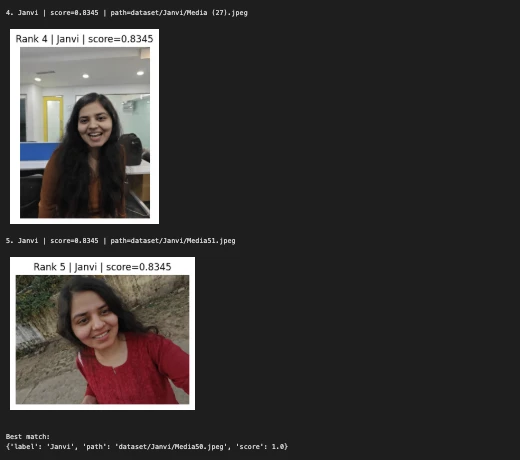
for i, match in enumerate(matches, 1):
print(f"{i}. {match['label']} | score={match['score']:.4f} | path={match['path']}")
show_image(match["path"], title=f"Rank {i} | {match['label']} | score={match['score']:.4f}")
print("nBest match:")
print(matches[0])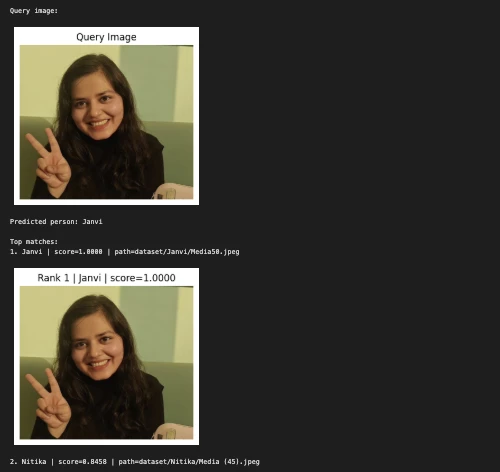
The notebook then displays:
- picture of the question
- the label of the predicted person
- similar top images from the dataset
- cosine-like scores for each game
This makes the system easier to visually test and helps ensure that embedding-based retrieval is working properly.
My Experience Using Gemini 2 Embedded
This project may be simple, but it clearly shows the practical value of Gemini Embedding 2.
First, it shows that embedding can be directly applied to image retrieval without training a separate classification model.
Second, it shows how a shared embedding space can simplify real-world applications. Although this version only uses images, the same structure can later be extended to text, audio, video, and document retrieval.
Third, it highlights how modern multimodal embedding reduces the need for complex pre-processing pipelines. Instead of manually extracting features or building a model from scratch, developers can use the embedding model as a general-purpose semantic backbone.
The Power of This Method
There are several reasons that this approach works well for prototypes:
- Very little training on top
- Simple implementation in the notebook
- Easy to expand
- Quick check
- Human readable results with high performance visualization
- It works naturally with similar searches
It is especially useful for small image matching tasks where you want a clean proof of concept.
Limitations
At the same time, this is still a lightweight demo and not a biometric production system.
A few limitations should be noted:
- Performance depends on image quality, lighting, background, and orientation
- More photos per person usually improves fitness
- People who look alike may produce close nesting
- The current pipeline does not include a stranger’s limit
- A full set of tests will be needed for an in-depth evaluation
This is not a failure of the Gemini 2 embedding. It is a common consideration of any image matching system.
The conclusion
Gemini Embedding 2 marks a significant change in the way developers can work with multimodal data. Instead of building separate pipelines for text, image, audio, video, and documents, we now have a model designed to represent them all in a unified semantic environment.
My image matching project is a small but useful example of this idea in action. By embedding images of three well-known people and comparing the query image by cosine similarity, I was able to create a clean retrieval and hierarchical workflow with very little code.
That’s the real promise of Gemini Embedding 2. It’s not just an announcement of a new model. It is an efficient building block for multimodal systems that is easy to design, easy to scale, and very close to real-world data.
Frequently Asked Questions
A. It is Google’s multi-modal embedding model that integrates text, images, audio, video, and documents into a single shared vector space for search, retrieval, integration, and classification.
A. It embeds the images of the data set, compares the query image using cosine similarity, and predicts the person based on the closest embed.
A. It acts as a semantic feature extractor, allowing image matching without building or training a separate deep learning classification model.
![]()
Hi, I’m Janvi, a data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how to extract valuable insights from complex datasets.
Sign in to continue reading and enjoy content curated by experts.



