Cohere AI Releases Cohere Transcribe: SOTA Automatic Speech Recognition (ASR) Model Powering Enterprise Speech Intelligence
 Model Powering Enterprise Speech Intelligence")
In the case of enterprise AI, the bridge between unstructured audio and physical text is often a bottleneck of proprietary APIs and complex pipelines. Today, Cohere—a company generally known for its text generation and embedding models—has officially entered the Automatic Speech Recognition (ASR) market with the release of its latest model ‘.Cohere Transcribe‘.
Architecture: Why the Conformer Matters
To understand the Cohere Transcribe model, one must look beyond the ‘Transformer’ label. While the model is encoder-decoder structuredirectly uses a a large Conformer encoder combined with a A lightweight Transformer decoder.
A Conformer is a hybrid architecture that combines the power of Convolutional Neural Networks (CNNs) and Transformers. In ASR, local features (such as specific phonemes or rapid changes in sound) are often better handled by CNNs, while global context (the meaning of a sentence) is the domain of Transformers. By combining these layers, Cohere’s model is designed to capture both fine-grained acoustic details and long-range language dependence.
The model was trained using generalized supervised cross-entropyan old but strong training objective that focuses on minimizing the difference between the predicted text and the ground truth transcript.
Working
While other world models aim for 100+ languages with varying degrees of accuracy, Cohere has chosen a ‘quality over quantity’ approach. The model supports officially 14 languages: English, German, French, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Chinese, Japanese, and Korean.
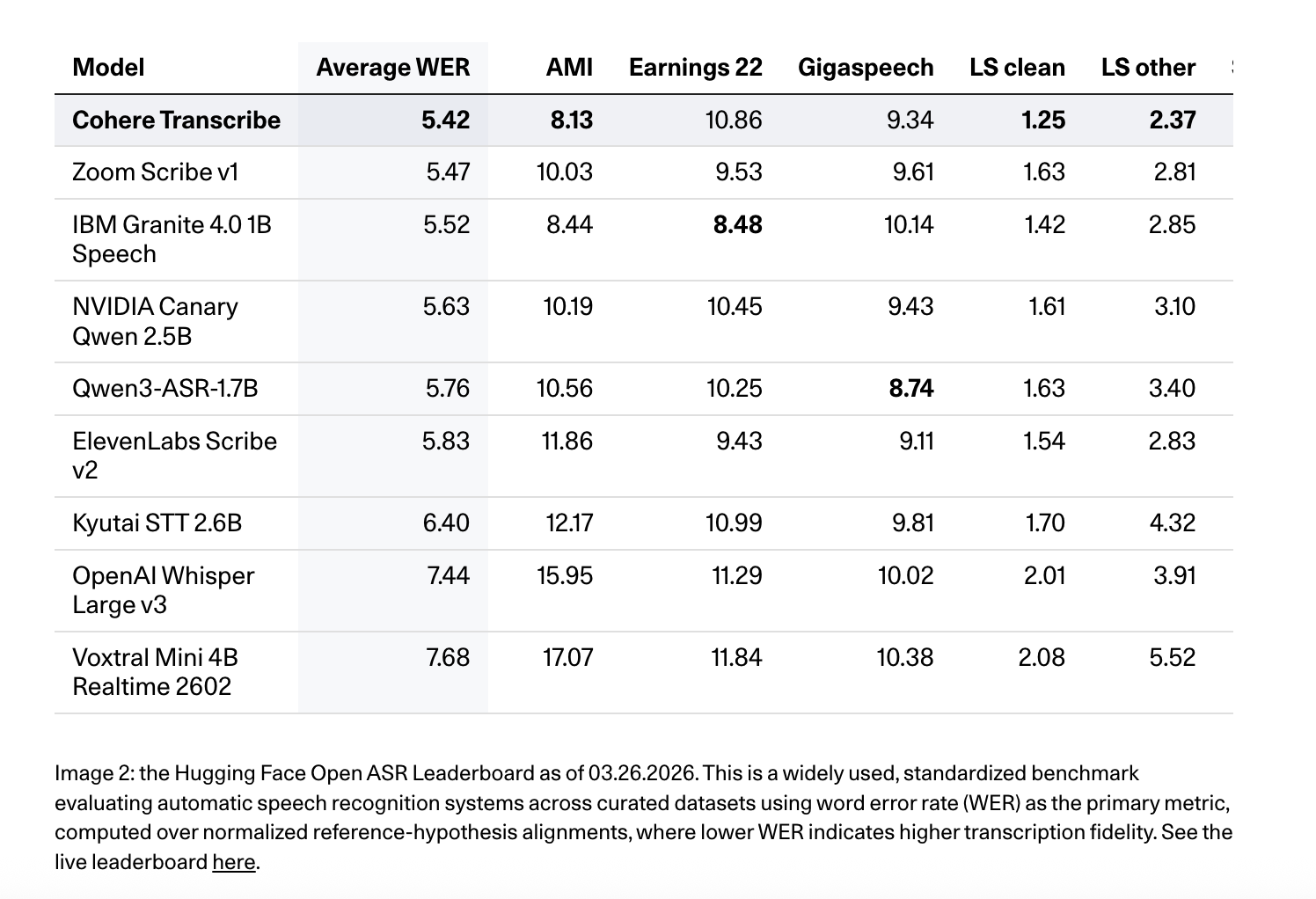
Unified positions Write as a high-precision, production-oriented ASR model. It is equal #1 in Face-hugging ASR leaderboard (March 26, 2026) by average WER of 5.42% for all benchmark sets including AMI, Earnings22, GigaSpeech, LibriSpeech pure/alternative, SPGISpeech, TED-LIUM, and VoxPopuli. It also scores 8.13 in AMI, 10.86 in Earnings22, 9.34 in GigaSpeech, 1.25 in LibriSpeech clean, 2.37 in LibriSpeech other, 3.08 in SPGISpeech, 2.49 in TED-LIUM, and 5.87 in VoxPopulimodels work best as Whisper Large v3 (7.44 average WER), ElevenLabs Script v2 (5.83)again Qwen3-ASR-1.7B (5.76) on various leaderboards.
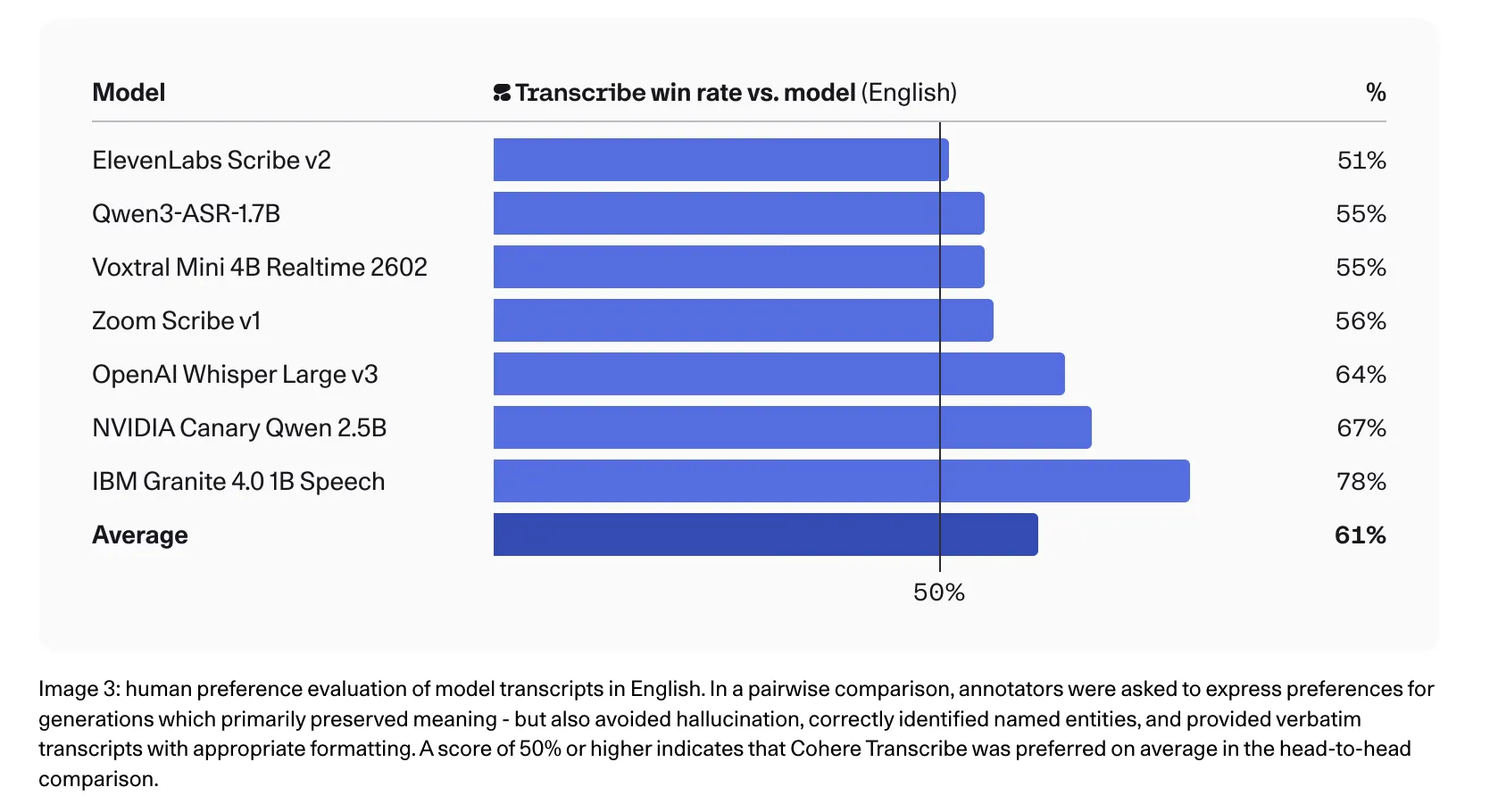
The Cohere team also reports strong results for human preference in English, where annotators prefer transcriptions to competing texts in head-to-head comparisons, including 78% against IBM Granite 4.0 1B Speech, 67% against NVIDIA Canary Qwen 2.5B, 64% against Whisper Large v3, and 56% against Zoom Scribe v1.
Long Form Audio: 35 second rule
Handling long-form audio—such as 60-minute phone calls or legal proceedings—presents a unique challenge for memory architecture. Cohere doesn’t refer to this with sliding window attention, but with durability chunking and reassembly logic.
The model is built natively for internal audio processing 35-second segments. For any file that exceeds this limit, the system automatically:
- It breaks the sound into overlapping pieces.
- It processes each component through the Conformer-Transformer pipeline.
- Regroups skipping text to ensure continuity.
This approach ensures that the model can handle a 55-minute file without exhausting GPU VRAM, as long as the developer pipeline handles the chunking orchestration correctly.
Key Takeaways
- State of the Art Accuracy: The model was launched at #1 on the Hugging Face Open ASR Leaderboard (March 26, 2026) by Word Error Rate (WER) of 5.42%. It outperforms established models such as Whisper Large v3 (7.44%) and IBM Granite 4.0 (5.52%) in all benchmarks including LibriSpeech, Earnings22, and TED-LIUM.
- Hybrid Conformer Architecture: Unlike conventional pure-Transformer models, Transcribe uses ia a large Conformer encoder paired with a lightweight Transformer decoder. This hybrid design allows the model to accurately capture both the local acoustic properties (via convolution) and the global linguistic context (via attention).
- Automated Long Form Management: To maintain memory efficiency and stability, the model uses native Chunking logic for 35 seconds. It automatically splits audio segments longer than 35 seconds into overlapping pieces and recombines them, allowing it to process extended recordings—such as 55-minute phone calls—without performance degradation.
- Technical Issues Explained: The model is a pure ASR tool as well does not include speaker dials or time stamps. It supports 14 specific languages and performs best when the target language is predefined, as it does not include automatic obvious language detection or advanced transcoding support.
Check it out Technical details again Model weight in HF. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



