Google Drops Gemini 3.1 Flash-Lite: A Cost-Effective Powerhouse with Adjustable Memory Levels Designed for High AI Productivity

Google has released it Gemini 3.1 Flash-Litethe most cost-effective entry in the Gemini 3 model series. Designed for ‘intelligence in scale,’ this model is optimized for high-volume operations where low latency and token cost are key engineering constraints. It is currently available in Public Preview with Gemini API (Google AI Studio) and Vertex AI.
Key Feature: Flexible ‘Thinking Levels’
A significant architectural update in the 3.1 series is the introduction of the Levels of Thinking. This feature allows developers to programmatically adjust the inference depth of the model based on a specific application problem.
By choosing between Small, Low, Medium, or High logic levels, you can develop a trade-off between latency and logical accuracy.
- Small/Low: Ideal for high-speed, low-latency tasks such as segmentation, basic sentiment analysis, or simple data extraction.
- Medium/High: It uses Deep Think Mini logical to handle complex instructions to follow, multi-step reasoning, and generation of structured data.
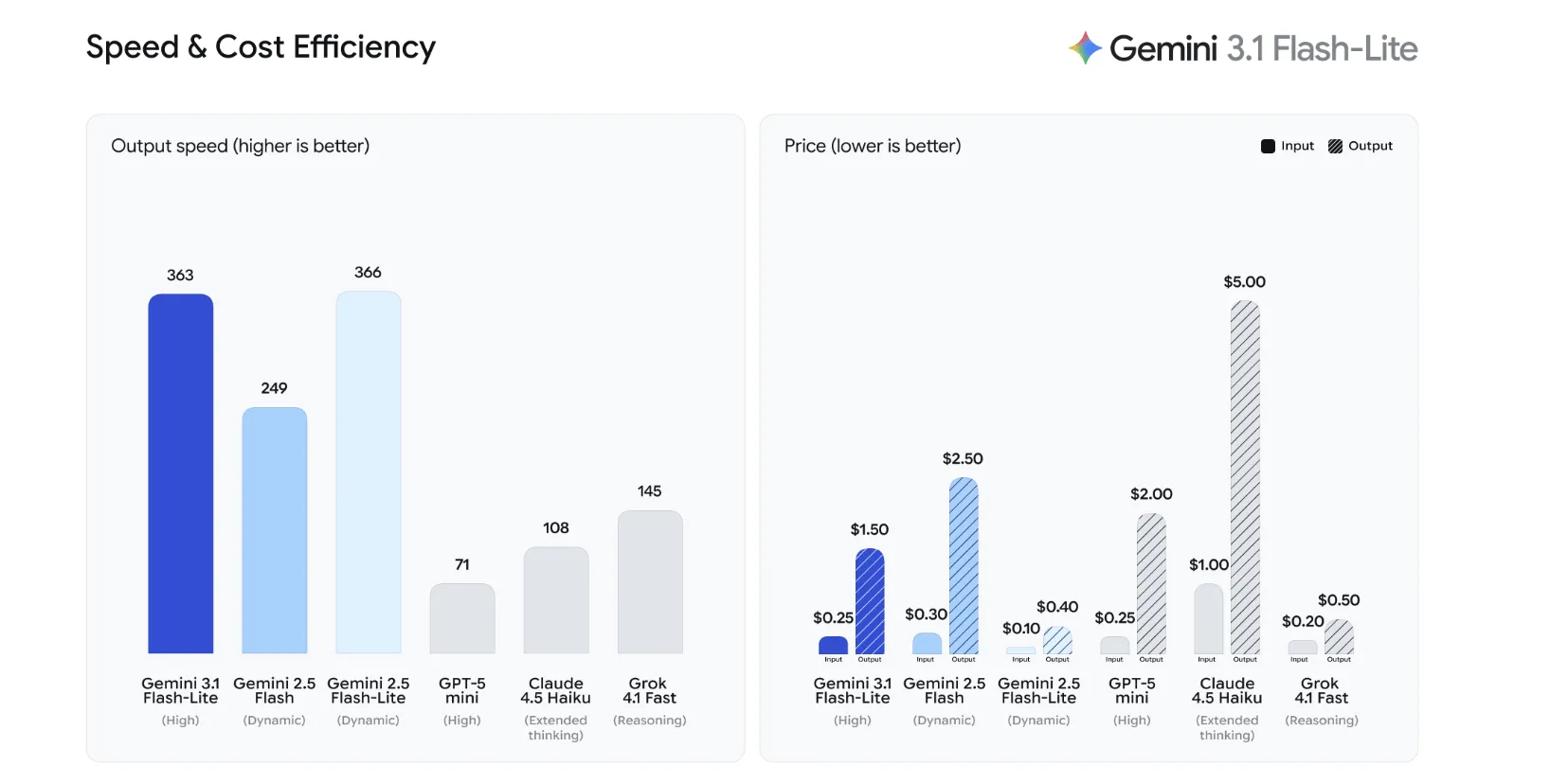
Performance and efficiency benchmarks
Gemini 3.1 Flash-Lite is designed to fill the void Gemini 2.5 Flash with a production load that needs to be handled quickly without sacrificing output quality. The model achieves a 2.5x faster Time to First Token (TTFT). and a 45% increase in overall output speed compared to the previous one.
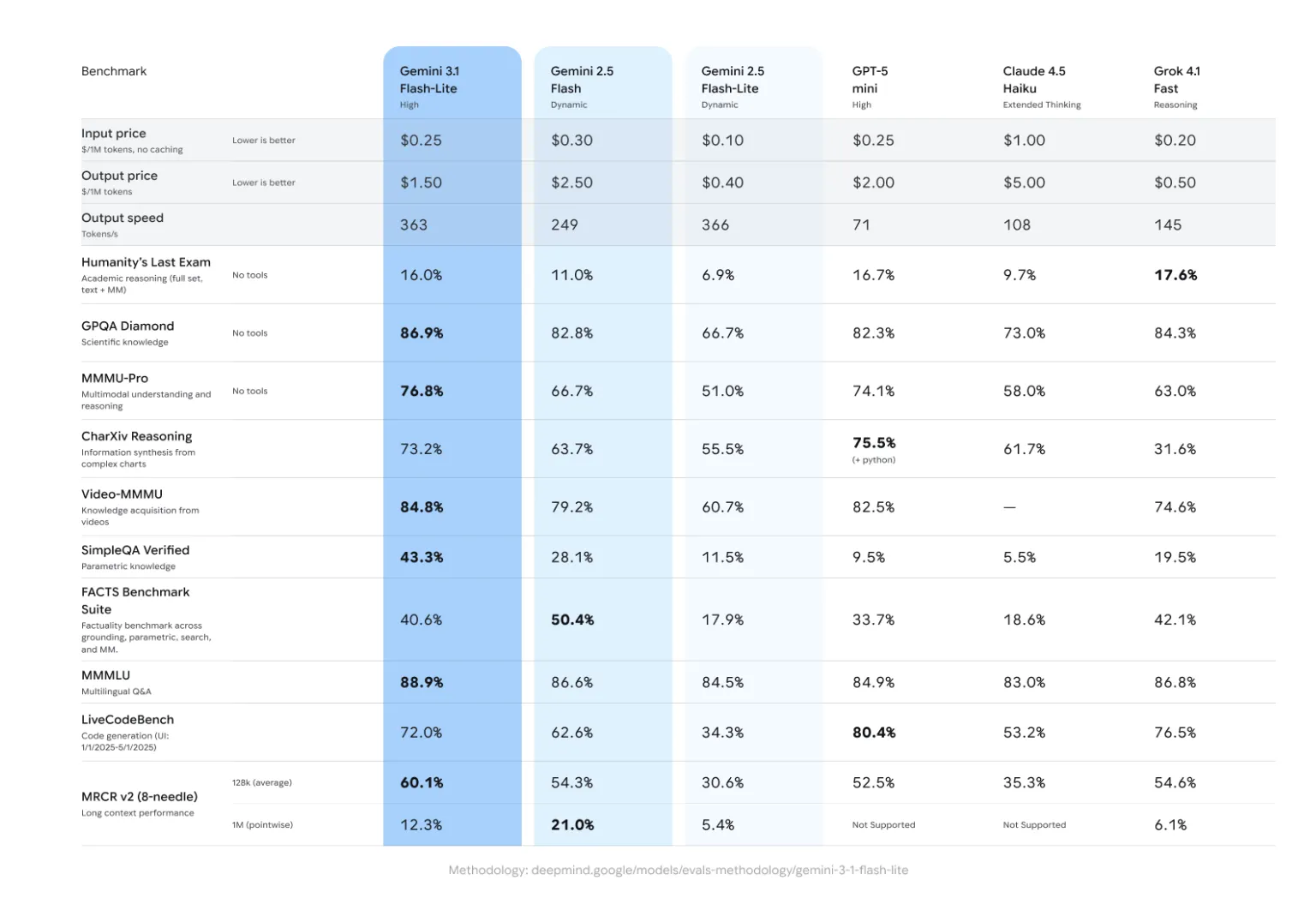
You have GPQA Diamond benchmark—a measure of professional-level thinking—Gemini 3.1 Flash-Lite scores 86.9%matching or exceeding the quality of the larger models in the previous generation while operating at a much lower computational cost.
Comparison table: Gemini 3.1 Flash-Lite vs. Gemini 2.5 Flash
| Metric | Gemini 2.5 Flash | Gemini 3.1 Flash-Lite |
| Installation Fee (1M tokens each) | At the top | $0.25 |
| Withdrawal Fee (for 1M tokens) | At the top | $1.50 |
| TTFT speed | The foundation | 2.5x Faster |
| Output | The foundation | 45% Faster |
| Consulting (GPQA Diamond) | Competition | 86.9% |
Use Cases of Manufacturing Technologies
The Flash-Lite 3.1 model is specifically designed for workloads involving complex architectures and long sequence logic:
- UI and dashboard implementation: The model is configured to generate the hierarchical code (HTML/CSS, React components) and the structured JSON required to render complex data visualizations.
- System Simulation: It maintains logical consistency over long periods of time, making it suitable for creating environmental simulations or workflows that require government tracking.
- Processing of Transaction Data: Due to its low input cost ($0.25/1M tokens), it serves as an efficient engine for extracting information from large models like the Gemini 3.1 Ultra to smaller, domain-specific datasets.
Key Takeaways
- Highest price-to-performance ratio: The Gemini 3.1 Flash-Lite is the most economical model in the Gemini 3 series, priced $0.25 per 1M input token again $1.50 for 1M output tokens. It outperforms Gemini 2.5 Flash by a 2.5x faster Time to First Token (TTFT). again 45% higher output speed.
- Introduction of ‘levels of thinking’: The new architecture feature allows developers to systematically change between Small, Low, Medium, and High mental toughness. This provides granular control to balance latency versus processing depth depending on the complexity of the task.
- High Consulting Benchmark: Despite its ‘Lite’ name, the model maintains a high-class mentality, scoring points 86.9% in GPQA Diamond benchmark. This makes it ideal for professional-level imaging tasks that previously required large, expensive models.
- Designed for Scheduled Workloads: The model is specifically designed for ‘intelligence at scale,’ leading to production complex UI/dashboardsto create system simulationand maintaining logical consistency throughout the code generation of long sequences.
- Seamless API Integration: Currently available at Community Previewthe model uses the
gemini-3.1-flash-lite-previewendpoint with Gemini API and Vertex AI. It supports multimodal input (text, image, video) while maintaining quality 128k content window.
Check out the public preview via Gemini API (Google AI Studio) again Vertex AI. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



