Meta Superintelligence Lab Releases Muse Spark: A Multimodal Reasoning Model for Thought Compression and Parallel Agents

Meta Superintelligence Labs recently made a significant step by unveiling the ‘Muse Spark’ – the first model in the Muse family. Muse Spark is a native multi-modal reasoning model that supports tooling, visual chain of reasoning, and multi-agent orchestration.
What ‘Natively Multimodal’ Really Means
When Meta describes Muse Spark as ‘traditional multimodal,’ it means that the model was trained from the ground up to process and use textual input and visual input simultaneously — not an input module tied to the language model afterwards. Muse Spark was built from the ground up to integrate virtual knowledge across domains and tools, achieving robust performance in virtual STEM questions, business recognition, and localization.
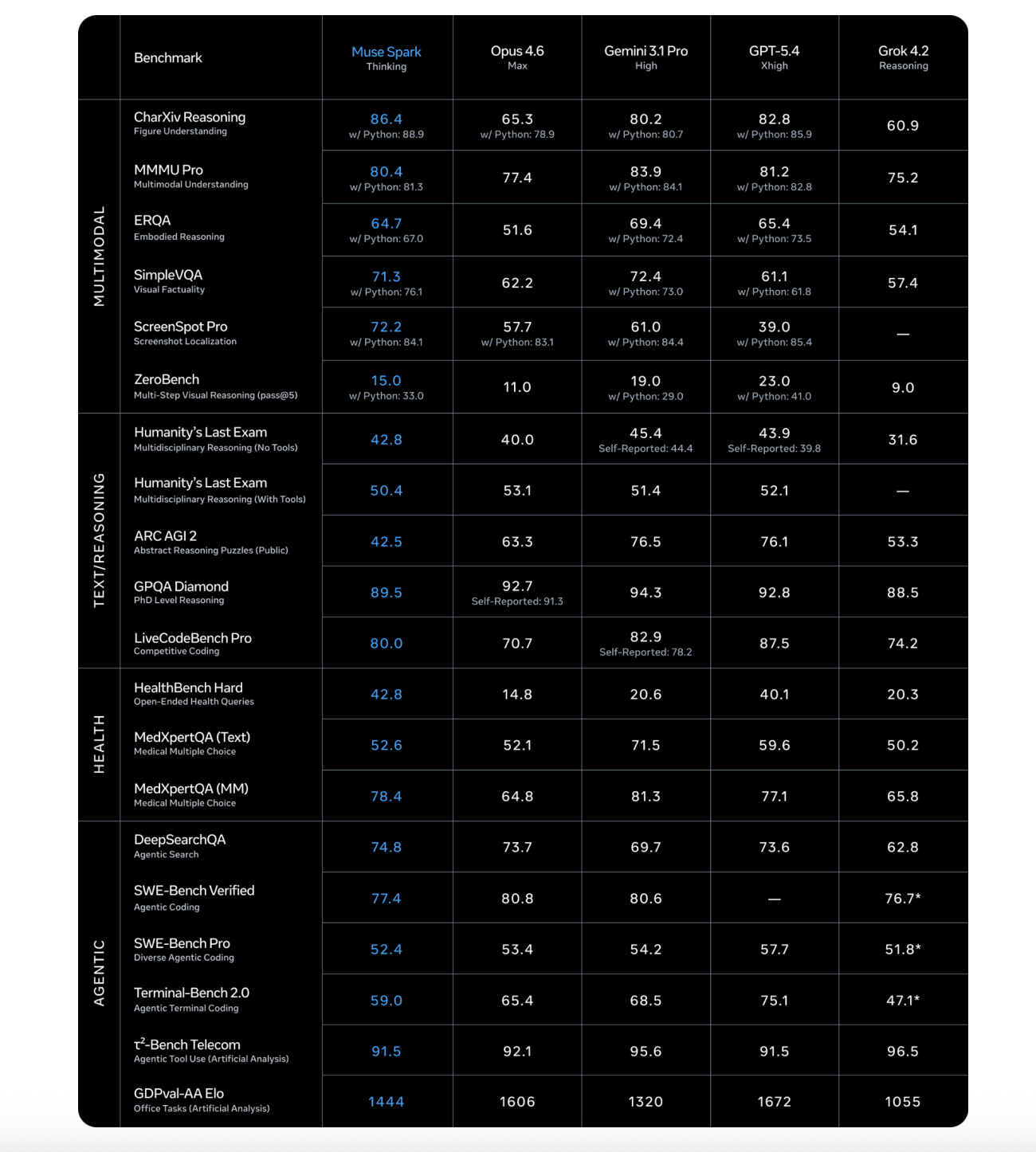
This architectural choice has real consequences for works involving language and perception. In the ScreenSpot Pro benchmark — which tests screenshot localization, which requires a model to identify certain UI elements in images — Muse Spark scores 72.2 (84.1 with Python tools), compared to Claude Opus 4.6 Max’s 57.7 (83.1 with Python) and GPT-5.39 Xhigh (Python 5.4 Xhigh).
Three Axes of Scale: Pretraining, RL, and Test-Time Reasoning
The most interesting technical aspect of the Muse Spark announcement is the clear Meta framework three axes of measurement – the levers they pull to improve the model’s capabilities in a predictable and measurable way. To support further scaling of all three, Meta is making strategic investments across the stack – from research and model training to infrastructure, including the Hyperion data center.
Self-training this is where the model learns its basic world knowledge, reasoning, and coding skills. Over the past nine months, Meta has rebuilt its pre-training stack with improvements in model design, optimization, and datasets. The advantage is the performance advantages: The Meta can achieve the same capabilities with a better calculation of the dimensions than its previous model, the Llama 4 Maverick. For devs, an ‘order of magnitude’ means around 10x computing efficiency – a huge improvement that makes future large scale models financially viable and operational.
Reinforcement Learning (RL) is the second axis. After pre-training, RL is used to increase the skills by training the model on output-based feedback instead of just predicting tokens. Think of it this way: pre-training teaches the model facts and patterns; RL teaches you to find the right answers. Even though large RL tends to be unstable, the new Meta stack delivers smooth, predictable gains. The research team reports log-linear growth at pass@1 and pass@16 on the training data, which means the model is consistently improving as the RL computer scales. pass@1 means that the model gets the answer on its first try; pass@16 means at least one success in every 16 attempts – a measure of diversity of thought.
Consultation Time Test is the third axis. This refers to the calculation of the model that is used during prediction – the time when it actually generates the user’s response. Muse Spark is trained to ‘think’ before it reacts, a process Meta’s research team calls test-time thinking. Delivering more intelligence per token, RL training increases accuracy under penalty during reasoning. This reveals what the research team calls suppression of thought: after the first time when the model evolves with long-term thinking, the length penalty causes thought compression – Muse Spark compresses its thinking to solve problems by using very few tokens. After compression, the model then expands its solutions again to achieve robust performance.
Mode of Inference: Multi-Agent Orchestration at Inference
Perhaps the most interesting aspect of the plot is the mode of reflection. The research team describes it as a novel multi-time testing scaffold that combines solution generation, iterative self-improvement, and integration. In plain words: instead of a single model producing a single answer, multiple agents work in parallel, each producing solutions that are then refined and combined into a final result.
While standard test time scaling has a single agent that thinks for a long time, Muse Spark’s time-scaling with multi-agent thinking enables higher performance and similar latency. This is an important trade-off for developers: latency scales with the depth of a single thread of thought, but parallel agents can add capacity without proportionally increasing latency.
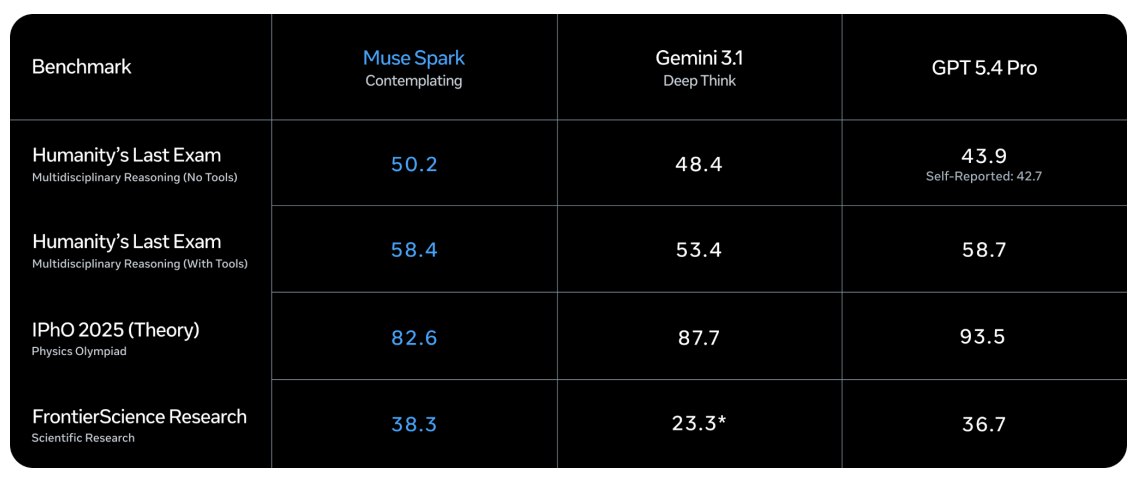
In think mode, the Muse Spark scores 58.4 on the Ultimate Human Test with Tools — a benchmark designed to test professional-level knowledge of many fields — compared to the Gemini 3.1 Deep Think’s 53.4 and the GPT-5.4 Pro’s 58.7. At FrontierScience Research, Muse Spark Contemplating scores 38.3, ahead of GPT-5.4 Pro’s 36.7 and Gemini 3.1 Deep Think’s 23.3.
Where the Muse Spark Leads – And Where It Follows
In health benchmarks, Muse Spark posts its most important results. On HealthBench Hard – a subset of the 1,000 open health questions – the Muse Spark scores 42.8, compared to the Claude Opus 4.6 Max’s 14.8, the Gemini 3.1 Pro High’s 20.6, and the GPT-5.4 Xhigh’s 40.1. This is not just luck: to improve the health thinking skills of Muse Spark, Meta’s research team has collaborated with more than 1,000 doctors to prepare training data that produces true and complete answers.
For coding benchmarks, the picture is very competitive. In SWE-Bench Verified, where models have to solve real GitHub problems using the bash tool and the file operation tool in a one-attempt setup limited to more than 15 attempts per problem, Muse Spark scores 77.4 — behind Claude Opus 4.6 Max at 80.8 and Gemini 3.1 Pro High at 80.6. In GPQA Diamond, a PhD-level imaging benchmark averaged over 4 runs to reduce variance, the Muse Spark scores 89.5, behind the Claude Opus 4.6 Max’s 92.7 and the Gemini 3.1 Pro High’s 94.3.
The sharpest gap comes from ARC AGI 2, a logic puzzle benchmark that runs on a public set of 120 data sets reported on pass@2. The Muse Spark scores 42.5 — reasonably behind the Gemini 3.1 Pro High at 76.5 and the GPT-5.4 Xhigh at 76.1. This is the current obvious weak spot in the Muse Spark profile.
Key Takeaways
- A new start for Meta, not a repeat: Muse Spark is the first model from the newly formed Meta Superintelligence Labs – built on a completely redesigned stack that is more than 10x more computationally efficient than the Llama 4 Maverick, featuring a deliberate reset at the bottom of Meta’s AI strategy.
- Life is the victory of the title benchmark: Muse Spark’s biggest decisive advantage over competitors is in health considerations — it scored 42.8 on HealthBench Hard compared to Claude Opus 4.6 Max’s 14.8 and Gemini 3.1 Pro High’s 20.6, supported by training data selected by more than 1,000 doctors.
- Inductive mode trades parallel computing for lower latency: Instead of making a single model think for a long time – which increases the response time – Muse Spark’s Contemplating mode uses multiple agents in parallel that refine and combine responses, achieving competitive performance in complex thinking tasks without disproportionately high latency.
- Abstract thinking is a very obvious weak point. In ARC AGI 2, the Muse Spark scores 42.5 compared to the Gemini 3.1 Pro High’s 76.5 and the GPT-5.4 Xhigh’s 76.1 — a huge performance gap across the benchmark table.
Check it out Technical details again Paper. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



