Mistral AI Introduces Voxtral Transcribe 2: Pairing a Diarization Cluster and Enabling Real-Time ASR for Multilingual Production Workloads at Scale

Automatic speech recognition (ASR) is becoming the foundation for building AI products, from conferencing tools to voice agents. The new Mistral Voxtral Transcribe 2 the family addresses this space with 2 models that break cleanly into bulk and real-time use cases, while focusing on cost, latency, and shipping barriers.
Releases include:
- Voxtral Mini Transcribe V2 collection writing with diarization.
- Voxtral Realtime (Voxtral Mini 4B Realtime 2602) with low-spread transcription, released as open weights.
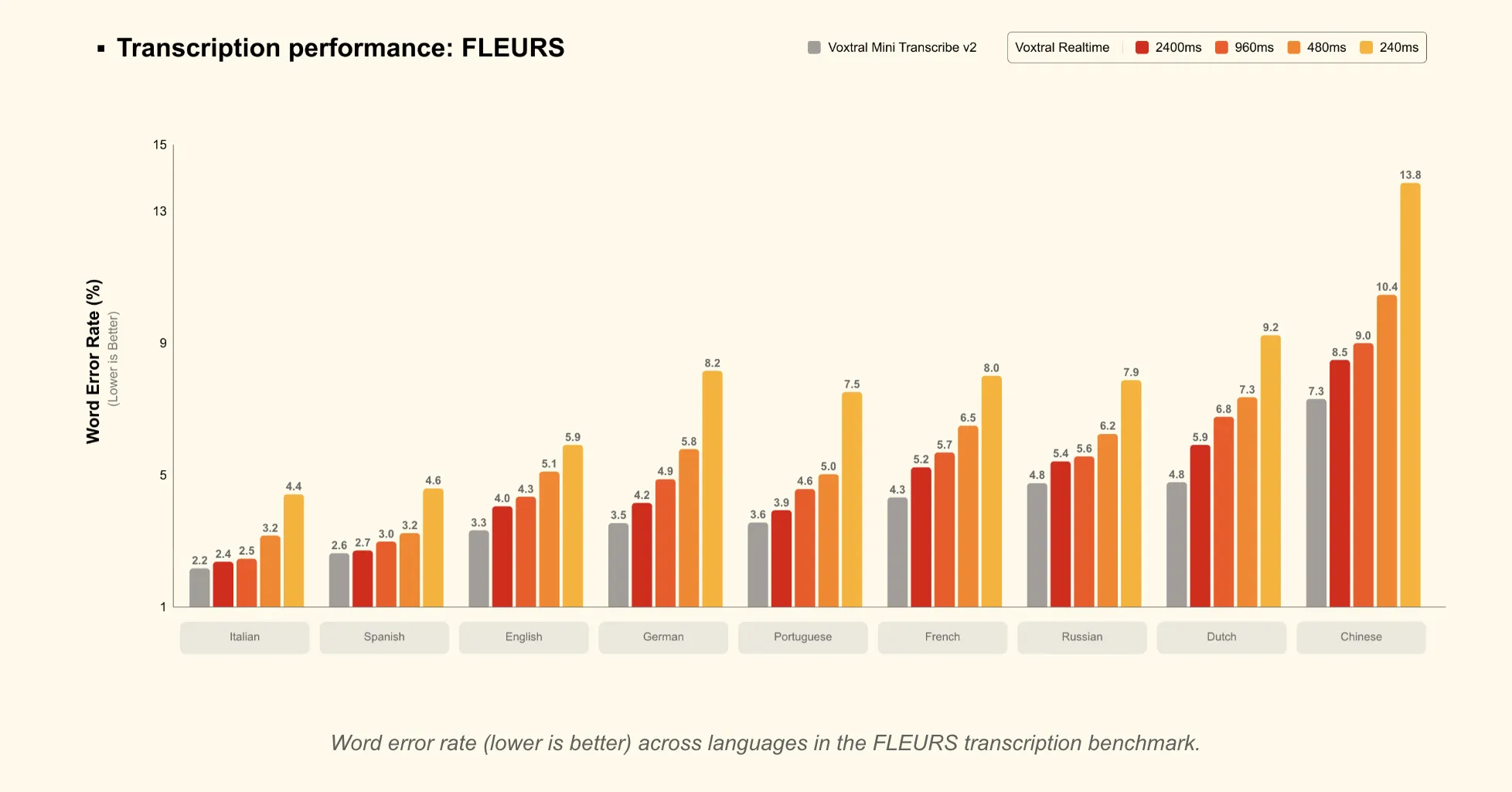
Both models are designed 13 languages: English, Chinese, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian, and Dutch.
Model family: collection and distribution, with clear roles
Mistral positions Voxtral Transcribe 2 as ‘next-generation speech-to-text model’ state-of-the-art transcription quality, dialing, and ultra-low latency.
- Voxtral Mini Transcribe V2 is batch model. It is optimized for transcription and dialing quality across all domains and languages and is featured as an efficient model for inputting audio into the Mistral API.
- Voxtral Realtime is broadcast model. It is built with dedicated transmission structures and is released as an open weight model underneath Apache 2.0 on Hugging Face, which has a recommended runtime of vLLM.
Important details: speaker dialing is provided by the Voxtral Mini Transcribe V2not with Voxtral Realtime. Realtime focuses on fast, accurate streaming recording.
Voxtral Realtime: 4B-parameter ASR streaming with adjustable delay
Voxtral Mini 4B Realtime 2602 it’s a A 4B multi-parameter model for real-time speech recognition. It is among the first open mass models to achieve accuracy comparable to offline systems with a delay of less than 500 ms.
Architecture:
- ≈3.4B-parameter language model.
- ≈0.6B-parameter audio encoder.
- The audio coder is trained from scratch with causal attention.
- Both encoder and LM use attention to the sliding windowwhich allows for effective “endless” streaming.
Latency versus accuracy can be clearly adjusted:
- The transcription delay can be set from 80 ms to 2.4 s by using a
transcription_delay_msparameter. - Mistral describes the delay as “sets down to sub-200 ms” with live applications.
- In 480 ms latencyreal-time models is the leading offline open source transcription models and real-time APIs for benchmarks such as FLEURS and long-form English.
- In 2.4 s delayReal time games Voxtral Mini Transcribe V2 in FLEURS, suitable for subtitling tasks where slightly higher latency is acceptable.
From a shipping perspective:
- The model is released in BF16 and designed for use on the device or on the edge.
- It can work in real time on a One GPU with ≥16 GB memoryaccording to the vLLM provisioning instructions on the model card.
The main control knob is the delay setting:
- Low latency (≈80–200 ms) for interactive agents where feedback dominates.
- Around 480 ms as a recommended “sweet spot” between latency and accuracy.
- High latency (up to 2.4 seconds) if you need to be as close as possible to the bulk model.
Voxtral Mini Transcribe V2: batch ASR with diary and context bias
Voxtral Mini Transcribe V2 it is a closed mass audio input model prepared only for writing. It is exposed in the Mistral API as voxtral-mini-2602 of $0.003 per minute.
On benchmarks and pricing:
- Around 4% word error rate (WER) in the FLEURS transcription benchmark, which averages over the top 10 languages.
- “The best price performance of any transcription API” at $0.003/min.
- It works very well GPT-4o mini Transcribe, Gemini 2.5 Flash, Universal Assemblyagain Deepgram Nova with precision in their comparisons.
- It processes sound ≈3× faster than ElevenLabs’ Scribe v2 while matching the quality to one-fifth of the cost.
Business-oriented features focus on this model:
- Speaker dial
- Outputs speaker labels with accurate start and end times.
- Designed for meetings, interviews, and multi-company calls.
- In overlapping speech, the model usually outputs a single speaker label.
- Content bias
- Accept it until it comes 100 words or phrases written bias towards certain words or domain terms.
- Prepared for English, by test support in other languages.
- Name-level timestamps
- Start and end timestamps for each subtitle, alignment, and searchable audio workflow.
- Sound intensity
- Maintains accuracy in noisy environments such as factory floors, call centers, and field recordings.
- Remote audio support
- It carries until 3 hours of sound in one application.
Language coverage shows Real Time: 13 languages, Mistral notes that non-English performance “far exceeds competitors” in their analysis.
APIs, tools, and usage options
The assembly methods are straightforward and differ slightly between the two models:
- Voxtral Mini Transcribe V2
- Works with Mistral audio transcription API (
/v1/audio/transcriptions) as an active write-only service. - price of $0.003/min. (Mistral AI)
- Available at Mistral Studio’s audio playground and to This Chat interactive testing.
- Works with Mistral audio transcription API (
- Voxtral Realtime
- Available through the Mistral API at $0.006/min.
- Released as open weights in a huggable face (
mistralai/Voxtral-Mini-4B-Realtime-2602) under Apache 2.0, with official vLLM Realtime support.
The audio playback platform in Mistral Studio allows users to:
- Upload up to 10 audio files (.mp3, .wav, .m4a, .flac, .ogg) are available 1 GB each one.
- Change the dial, select the timestamp granularity, and configure the context bias terms.
Key Takeaways
- The family of two models has clear roles: Voxtral Mini Transcribe V2 targets bulk transcription and diary making, while Voxtral Realtime targets low ASR streaming, both in 13 languages.
- Real-time model- 4B parameters with adjustable delay: Voxtral Realtime uses a 4B architecture (≈3.4B LM + ≈0.6B encoder) with sliding window and causal attention, and supports adjustable recording delay from 80 ms to 2.4 s.
- The latency vs accuracy trade-off is obvious: At about 480 ms latency, Voxtral Realtime achieves an accuracy comparable to robust offline and real-time systems, and at 2.4 s it matches the Voxtral Mini Transcribe V2 in FLEURS.
- The cluster model adds dialing and business features: Voxtral Mini Transcribe V2 provides dialing, context biasing up to 100 sentences, word-level timestamps, audio compression, and supports up to 3 hours of audio per request for $0.003/min.
- Deployment- closed batch API, open real-time weights: Mini Transcribe V2 is offered with Mistral’s audio transcription API and platform, while Voxtral Realtime is priced at $0.006/min and is available as Apache 2.0 open source with official vLLM Realtime support.
Check it out Technical details and model weights. Also, feel free to follow us Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.


 from Scratch Using RLax JAX Haiku and Optax to Train a CartPole Reinforcement Learning Agent")

