Mistral AI Releases Small Mistral 4: A 119B-Parameter MoE Model Including Discipline, Logic, and Multiple Workloads

Mistral AI released Lesser Mistral 4a new model in the Mistral Small family designed to combine several previously separate capabilities into a single deployment target. The Mistral team describes the Small 4 as its first model for integrating related roles The Lesser Mistral for the following instructions, Magistrate thinking, Pixtral understanding is multimodal, and Devstral by agent code. The result is a single model that can serve as a general assistant, conceptual model, and multimodal system without requiring model changes throughout the workflow.
Architecture: 128 Experts, Sparse Performance
Architecturally, the Mistral Small 4 is a MoE model with 128 experts again 4 active technicians per token. The model has 119B total parameterswith 6B parameters are valid for each tokenor 8B including embedding and output layers.
Long Context and Multimodal Support
The model supports a 256k content windowwhich is a logical leap for practical engineering use cases. Long context capacity is important as a marketing number and more so as operational simplicity: it reduces the need for dynamic configuration, retrieval orchestration, and context pruning for tasks such as long document analysis, codebase testing, multi-file reasoning, and agent workflows. Mistral sets the model for general conversation, coding, agent functions, and complex reasoningwith text and image input again text output. That puts Small 4 in the most important category of general-purpose models that are expected to handle both heavy and virtual-based business functions under a single API environment.
Configurable Reasoning During Inference
A more important product decision than raw parameter calculation is the presentation of adjustable thinking effort. A minimum of 4 displays each request reasoning_effort a parameter that allows developers to trade latency to gain deeper test-time considerations. In the official text, reasoning_effort="none" is defined as producing quick responses in a conversational style that is equivalent to Little Mistral 3.2while reasoning_effort="high" it’s meant to be deliberate, step-by-step action compared to before Magistrate models. This changes the usage pattern. Instead of routing between a single instantiated model and a single logic model, dev teams can maintain a single model in a service and vary the behavior at request time. That’s cleaner from a systems perspective and easier to manage in products where only a small set of queries require expensive logic.
Performance claims and performance status
The Mistral team also emphasizes the efficiency of the ideas. Small 4 brings a 40% reduction in end-to-end completion time in the configured delay setting as well 3x more requests per second in the enhanced output setup, both are measured against the Mistral Small 3. Mistral does not present the Small 4 as just a large conceptual model, but as a system intended to improve the economy of deployment under real deployment loads.
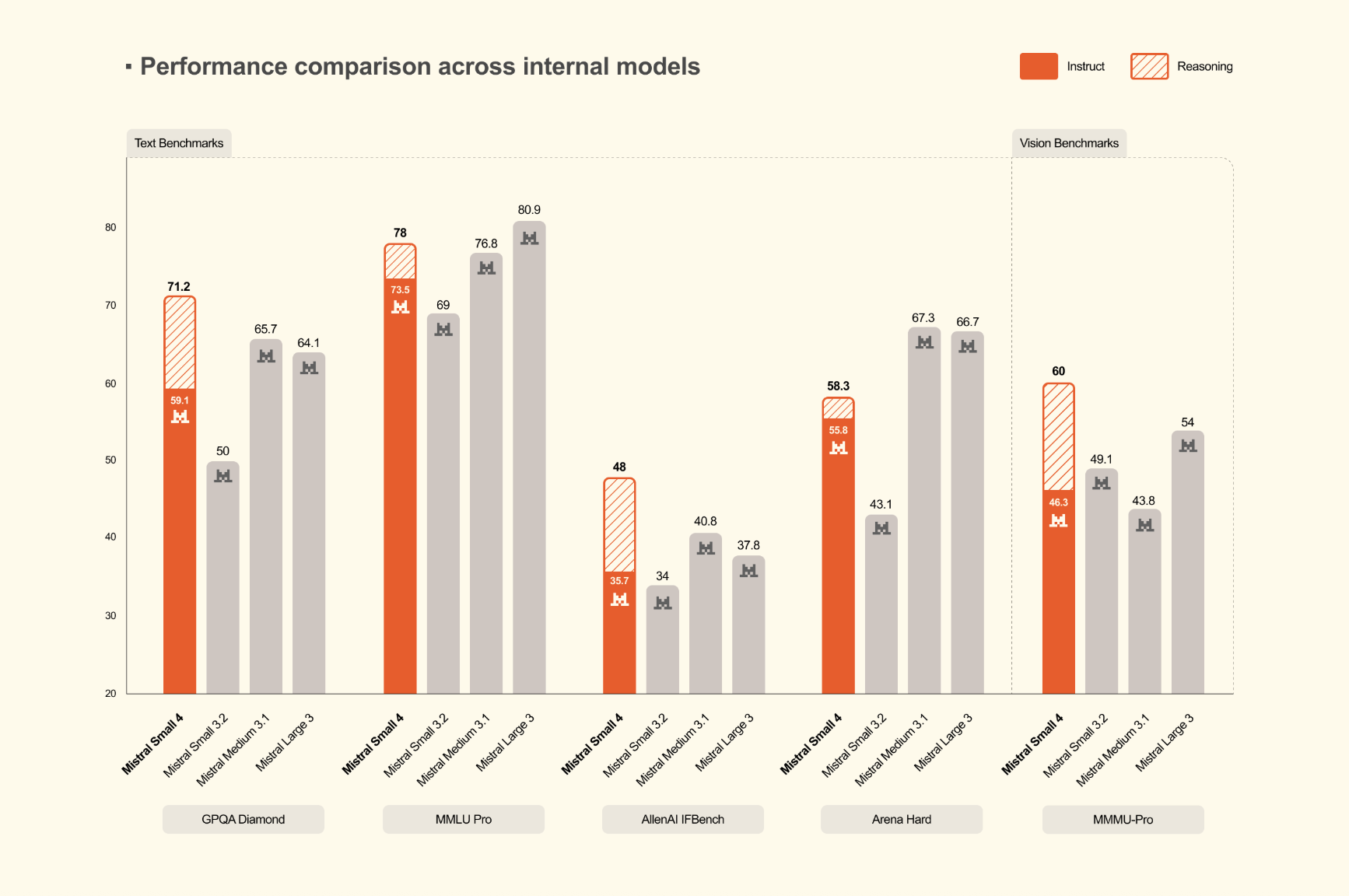
Benchmark Results and Output Success
In imaging benchmarks, the Mistral output focuses on both output quality and efficiency. The Mistral research team reports that Little Mistral 4 in thought it’s the same or it skips GPT-OSS 120B on the other side AA LCR, LiveCodeBenchagain AIME 2025while producing short output. In the numbers published by Mistral, Small 4 score 0.72 in AA LCR with 1.6K characterswhile Qwen models require 5.8K to 6.1K characters similar performance. Opened LiveCodeBenchMistral team says Small 4 outperforms GPT-OSS 120B while producing 20% less output. These are the results published by the company, but they highlight a more useful metric than the benchmark score alone: working with each token generated. For production workloads, short results can directly reduce delays, overhead costs, and upstream fragmentation.
Shipping Details
On its own, Mistral provides a specific infrastructure guide. The company calculates a minimum target amount for the distribution 4x NVIDIA HGX H100, 2x NVIDIA HGX H200or 1x NVIDIA DGX B200with a larger setting recommended for best performance. The model card on HuggingFace lists support throughout vLLM, llama.cpp, SGlangagain Transformersalthough other methods are marked work in progressagain vLLM recommended option. The Mistral team also provides a custom Docker image and notes that fixes related to tool calling and logic separation are still being upgraded. That’s useful information for developer teams because it clarifies that support is there, but some pieces are still stable in the broader open source deployment stack.
Key Takeaways
- One integrated model: Mistral Small 4 combines the power of teaching, thinking, multimodal, and coding agency in one model.
- Small MoE design: It uses 128 experts with 4 active technicians per tokentargeting efficiency better than compact models of the same size.
- Remote content support: The model supports a 256k content window and he accepts text and image input with text output.
- Consultation can be arranged: Developers can fix
reasoning_effortat the time of decision instead of taking a route between different fast and logical models. - Turn focus on using: It is removed from the bottom Apache 2.0 and supports serving by using stacks like vLLMwith many checkpoint variations in Hugging Face.
Check it out Model Card in HF again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



