Mistral AI Releases Voxtral TTS: An Open 4B Weighted Broadcast Speech Model for Low-Latency Multilingual Voice Generation

Mistral AI released Voxtral TTSan open-source text-to-speech model that marks the company’s first major move into audio production. Following the release of its transcription models and language models, Mistral now provides the final ‘output layer’ of the audio stack, positioning itself as a direct competitor to proprietary voice APIs in the developer ecosystem.
Voxtral TTS is more than just a synthetic voice generator. A highly efficient, modular design designed for integration with real-time voice workflows. By releasing the model under a CC BY-NC licenseThe Mistral team continues its plan to enable developers to build and deploy frontier-grade capabilities without the price barriers of closed-source APIs or data privacy restrictions.
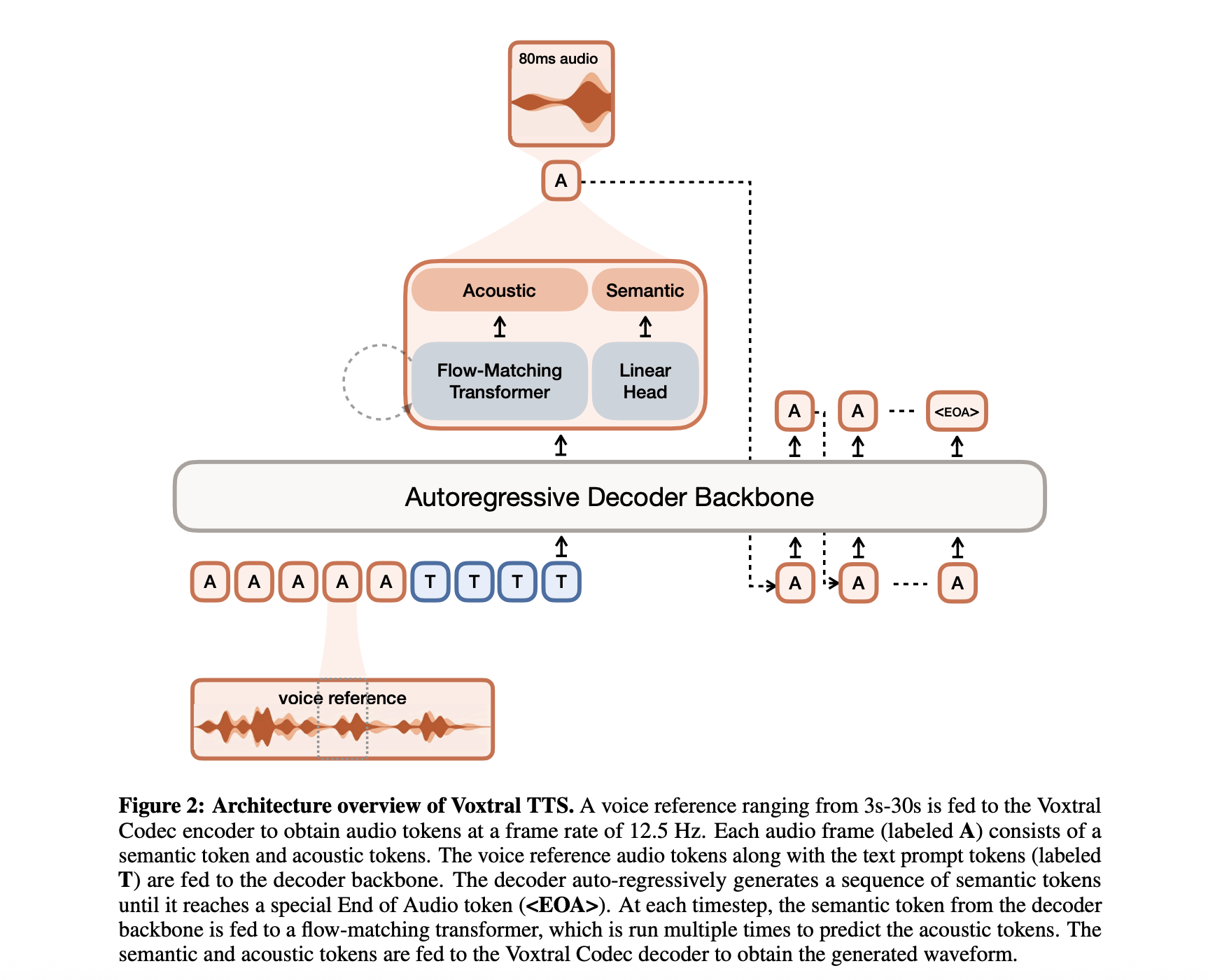
Architecture: 4B Parameter Hybrid Model
While many recent developments in text-to-speech have focused on large, resource-intensive architectures, Voxtral TTS was built with a focus on efficiency. Features of the model 4B parametersclassified as a lightweight model by modern borderline standards.
This parameter calculation is distributed in a hybrid architecture designed to solve the general trade-off between generation speed and natural noise. The program consists of three main parts:
- Transformer Decoder Backbone: A 3.4B parameter module based on the Ministral architecture that handles text comprehension and predicts semantic representations of speech.
- Flow-Matching Acoustic Transformer: The 390M parameter module converts those semantic representations into detailed acoustic features.
- Neural Audio Codec: A 300M parameter decoder that maps acoustic properties back to the most faithful sound form.
By separating the ‘meaning’ of the speech (semantic) from the ‘structure’ of the voice (acoustic), Voxtral TTS maintains long-range coherence while delivering the fine-tuned nuances required for life-like performance.
Performance: 70ms Latency and High Performance
In the context of production-grade AI, latency is a defining limitation. Mistral has developed Voxtral TTS for low-level streaming guidance, making it ideal for real-time chat and translation agents.
The model achieves a 70ms model delay with a 10 second normal voice sample and 500 character input. This speed is important for reducing perceived latency in voice-first applications, where even slow pauses can disrupt the flow of human-machine interactions.
In addition, the model has a high level Real-Time Factor (RTF) of about 9.7x. This means that the system can synthesize sound ten times faster than it says. For developers, this evolution translates to lower computing costs and the ability to handle more expensive workloads on conventional hardware.
Global Access: 9 Languages and Dialect Accuracy
Voxtral TTS is written in many languages, it supports 9 languages out of the gate: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic.
The training objective of the model goes beyond simple phonetic translation. Mistral emphasized the model’s ability to capture different dialectsrecognizes the subtle changes in cadence and prosody that distinguish regional speakers. This technical precision makes the model a useful tool for global applications—from international customer support to local content creation—where a generic, ‘flat’ expression often fails to pass human scrutiny.
Adaptive Voice Adaptation
One of the most prominent features of AI devs is the ease of modeling adapting to the voice. Voxtral TTS supports zero-shot and small voice cloning, allowing it to adapt to a new voice using less 3 seconds of audio reference.
This capability allows for the creation of consistent brand expressions or personalized user experiences without the need for extensive fine-tuning. Because the model uses a robust representation, it can apply the features of the reference voice (timbre, tone, and pitch) to any generated text while maintaining the correct prosody of the target language.
Benchmarks: A Challenge to Proprietary Giants
Mistral’s evaluation focused on how the Voxtral TTS stacks up against current industry leaders in artificial intelligence, in particular. ElevenLabs. In a preference test conducted by native speakers, Voxtral TTS He showed significant advantages in nature and expressiveness.
- vs. ElevenLabs Flash v2.5: The Voxtral TTS has achieved a 68.4% win rate in a multilingual speech synthesis test.
- vs. ElevenLabs v3: The model received an equal or higher score speaker uniformitywhich proves that the open-weighted model can effectively match the reliability of the leading expressions of the identity.
These benchmarks suggest that in most business use cases, the performance gap between open source tools and more expensive APIs is effectively closed.

Distribution and Integration
Voxtral TTS is designed to work as part of an assembly Audio Intelligence stack. It traditionally combines with Voxtral Transcribecreating an end-to-end (S2S) pipeline.
For AI developers building on on-premise or private cloud infrastructure, the model footprint is a huge advantage. Mistral’s team has confirmed that the model is working well enough for normal operation smartphone and laptop hardware has been measured. This ‘edge readiness’ enables a new class of private, offline applications, from secure corporate assistants to device access tools.
| Clarification | Metric |
| Model Size | 4B Parameters |
| Delay (10s voice / 500 characters) | 70 ms |
| Real-Time Factor (RTF) | ~9.7x |
| Supported Languages | 9 |
| Audio Reference Required | 3 – 30 seconds |
| License | CC BY-NC |
Key Takeaways
- The 4B Parameter Model that works best: The Voxtral TTS is an open weight model with 4B parameter footprint, using a hybrid architecture that combines auto-regressive semantic generation and matching acoustic information flow.
- 70ms minimum latency: Optimized for real-time applications, the model achieves a 70ms model delay with a standard 10 second voice sample (500 character input) and impressive Real-Time Factor (RTF) of about 9.7x.
- Superior Multilingual Performance: The model supports 9 languages (English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi and Arabic) and do very well ElevenLabs Flash v2.5 with 68.4% win rate in a human preference test for speech synthesis in multiple languages.
- Quick voice practice: Developers can achieve reliable voice integration with less 3 seconds of audio referencewhich allows for adaptation in situations where the identity of the speaker is preserved in different languages.
- Full Audio Stack Integration: Designed as the ‘output layer’ of an integrated audio intelligence pipeline, it connects natively Voxtral Transcribe to create a low-latency, end-to-end speech-to-speech workflow.
Check it out Paper, Model Weight again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



