Moonshot AI Release 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔 Recovering Residual Mixing for Better-Wittering Attention

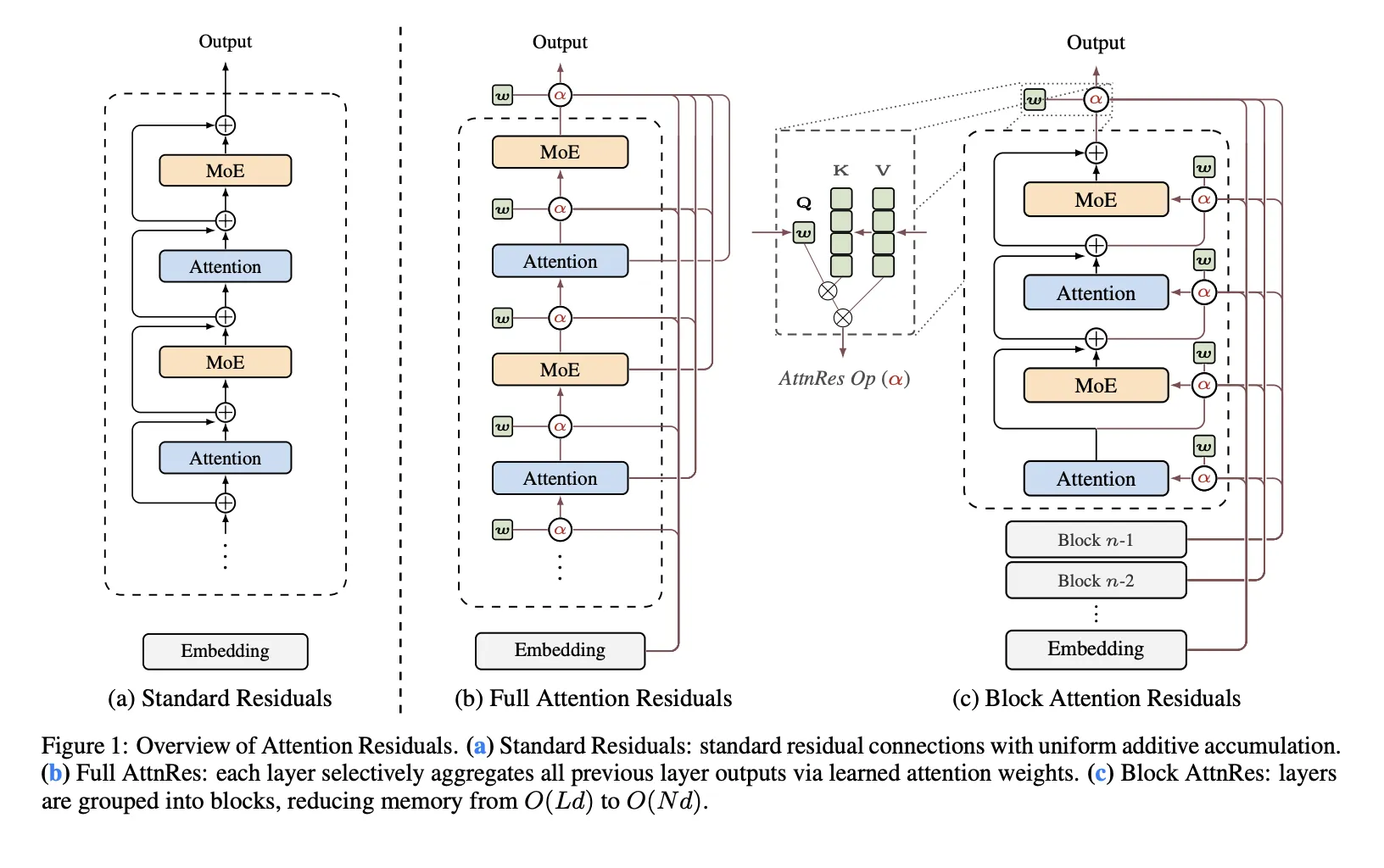
Residual connections are one of the least-questioned aspects of modern Transformer design. In PreNorm architectures, each layer adds the output back to the active hidden state, which keeps the optimization stable and allows deep models to train themselves. Moonshot AI researchers argue that this general approach also presents a structural problem: all the effects of the previous layer are accumulated with constant unit weights, which causes the size of the hidden state to increase with depth and gradually weakens the contribution of any one layer.
The research team proposes AttnRes (AttnRes) as a replacement for normal surplus accumulation. Instead of forcing all layers to consume the same residual stream mixed uniformly, AttnRes allows each layer to combine prior representations using softmax attention over depth. The input to layer (l) is the weighted sum of the token embeddings and the output of the previous layer, where the weights are calculated by depth fields rather than sequence fields. The main idea is simple: if attention improves the sequence of the model by changing the frequency constant over time, the same idea can be applied to the depth of the network dimension.
Why Common Waste Becomes a Bottleneck
The research team identified three problems with common waste collection. First, there is no access is selected: all layers receive the same integrated state although attentional layers and feedforward or MoE layers may benefit from different mixes of prior knowledge. Second, there is irreversible loss: once the information has been combined into a single residual stream, later layers cannot selectively restore certain earlier representations. Thirdly, there is product growth: deeper layers tend to produce larger results to remain influential within an ever-growing cumulative situation, which can undermine training.
This is the main framework of the research team: ordinary fossils are like multiples compressed on top of layers. AttnRes replaces that iteration constant with an explicit focus on top of the previous layer’s output.
Full AttnRes: Attention to All Previous Layers
In Complete AttnReseach layer computes attention weights over all preceding depth sources. Automatic design does not use a query with an input condition. Instead, each layer has a learned pseudo-query vector wl ∈ Rdwhile the keys and values come from the token embedding and output of the previous layer after RMSNorm. The RMSNorm step is important because it prevents the output of the high-dimensionality layer from dominating the more intelligent attention weights.
Full AttnRes is straightforward, but increases the cost. For each token, it requires O(L2 d) arithmetic memory and (O(Ld)) storage layer output. In normal training this memory often overlaps with the activation that is already necessary to use backpropagation, but under activation the recalculation and parallelization of the pipelines above becomes more important because those previous results must always be present and may need to be transferred to all stages.
Block AttnRes: A Functional Exception for Large Models
To implement the method at scale, the Moonshot AI research team presented Block AttnRes. Instead of going through all the outputs of the previous layer, the model splits the layers into N blocks. Within each block, the output is aggregated into a single block representation, and attention is only applied to those block-level representations and embedding tokens. This reduces memory and communication overhead O(Ld) to O(N).
The research team describes a cache-based pipeline communication and two-phase computation strategy that makes Block AttnRes efficient for distributed training and inference. This results in more than 4% training under parallel pipelines, while the cache reports less than 2% inference latency overhead in normal operations.
Measuring Results
The research team tested five model sizes and compared three variants of each size: baseline PreNorm, Full AttnRes, and Block AttnRes for approximately eight blocks. All types within each size group share the same parameters selected under the base, which the research team notes makes the comparison conservative. The installed scaling rules are reported as follows:
Basis: L = 1.891 x C-0.057
Block AttnRes: L = 1.870 x C-0.058
Complete AttnRes: L = 1.865 x C-0.057
The practical implication is that AttnRes achieves the lowest validation loss across the tested computing range, and Block AttnRes matches the loss of the trained baseline in approx. 1.25× more computer.
Integration in Kimi Linear
Moonshot AI also integrates AttnRes in I’m Linearits MoE structure with Total 48B parameters and 3B activated parametersand train it beforehand 1.4T tokens. According to the research paper, AttnRes reduces the dilution of PreNorm by keeping the output size integrated with depth and distributing the gradients uniformly in all layers. Another implementation detail is that all pseudo query vectors are initialized to zero so that the initial attention weights are the same for all source layers, effectively reducing AttnRes to a uniform weight ratio at the beginning of training and avoiding premature instability.
In a step-down analysis, reported benefits are consistent across all listed occupations. It reports improvement from 73.5 to 74.6 in MMLU, 36.9 to 44.4 in GPQA-Diamond, 76.3 to 78.0 in BBH, 53.5 to 57.1 in Math, 59.1 to 62.2 in HumanEval, 72.92 to 73.8 in MB. CMMLU, and 79.6 to 82.5 on C-Eval.
Key Takeaways
- Attention Residuals replace the accumulation of fixed residuals with softmax attention on top of previous layers.
- The default AttnRes design uses a pseudo-query for the specified layer, not a query with input criteria.
- Block AttnRes makes the method useful by reducing memory depth-wise and communication from O(Ld) to O(Nd).
- The Moonshot research team reports lower scaling loss than the PreNorm baseline, with Block AttnRes corresponding to the baseline computing 1.25× higher.
- In Kimi Linear, AttnRes improves results on all logic, coding, and analysis benchmarks with limited overhead.
Check it out Paper again Repo. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



