NVIDIA Releases Nemotron-Cascade 2: Open 30B MoE with 3B Operating Parameters, Brings Better Thinking and Powerful Agentic Capabilities

NVIDIA has announced the release of Nemotron-Cascade 2open weight 30B Mixed-Expert (MoE) model with 3B activated parameters. The model focuses on increasing ‘intellectual density,’ bringing advanced imaging capabilities to a fraction of the parameter scales used by frontier models. Nemotron-Cascade 2 is the second LLM with open access Gold Medal level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals.
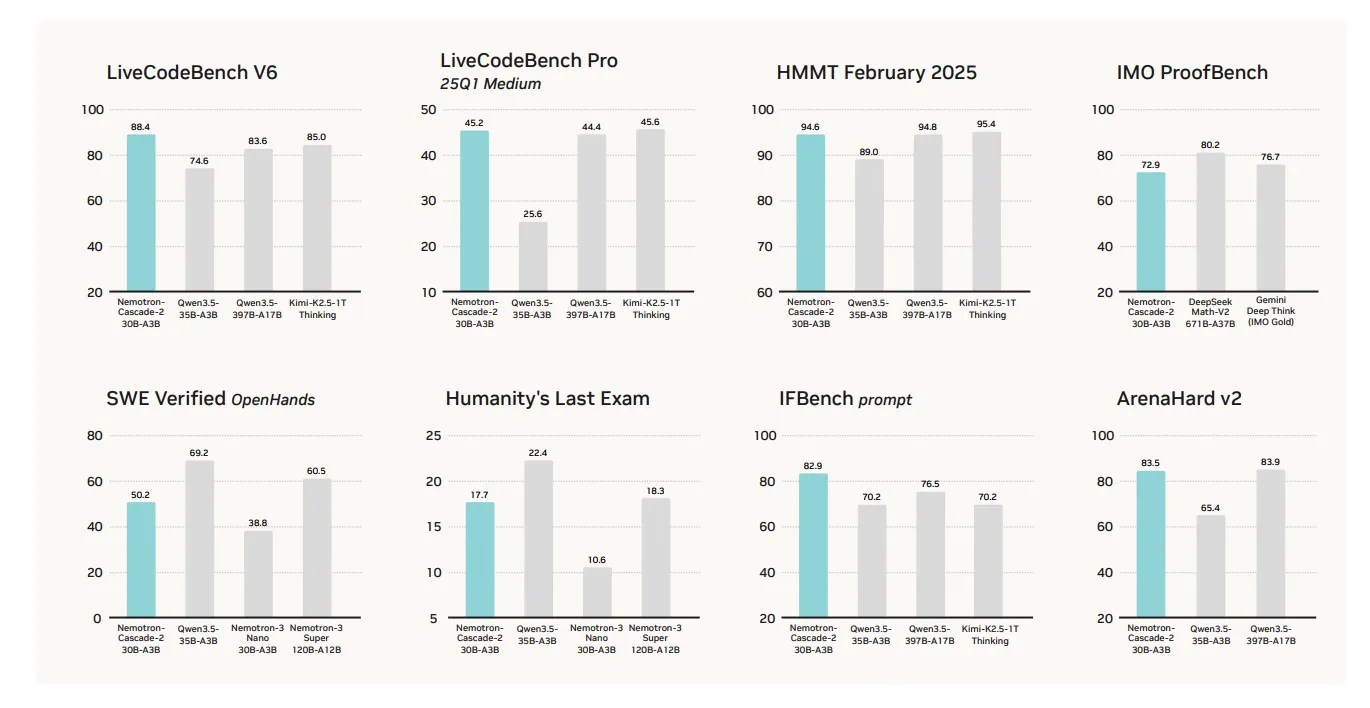
Target Performance and Strategic Trade-offs
The main value proposition of the Nemotron-Cascade 2 is its exceptional performance in mathematical reasoning, coding, alignment, and following instructions. Although it achieves high-quality results in these important domains that require consideration, it is certainly not a ‘total victory’ in all benchmarks.
The performance of the model is very good in several target categories compared to the newly released one Qwen3.5-35B-A3B (February 2026) and larger Nemotron-3-Super-120B-A12B:
- Mathematical Reasons: Works Over Qwen3.5-35B-A3B is on AIME 2025 (92.4 vs. 91.9) and HMMT Feb 25 (94.6 vs. 89.0).
- Coding: Leading the way LiveCodeBench v6 (87.2 vs. 74.6) and IOI 2025 (439.28 vs. 348.6+).
- Alignment and following instructions: The scores are very high ArenaHard v2 (83.5 vs. 65.4+) and IFBench (82.9 vs. 70.2).
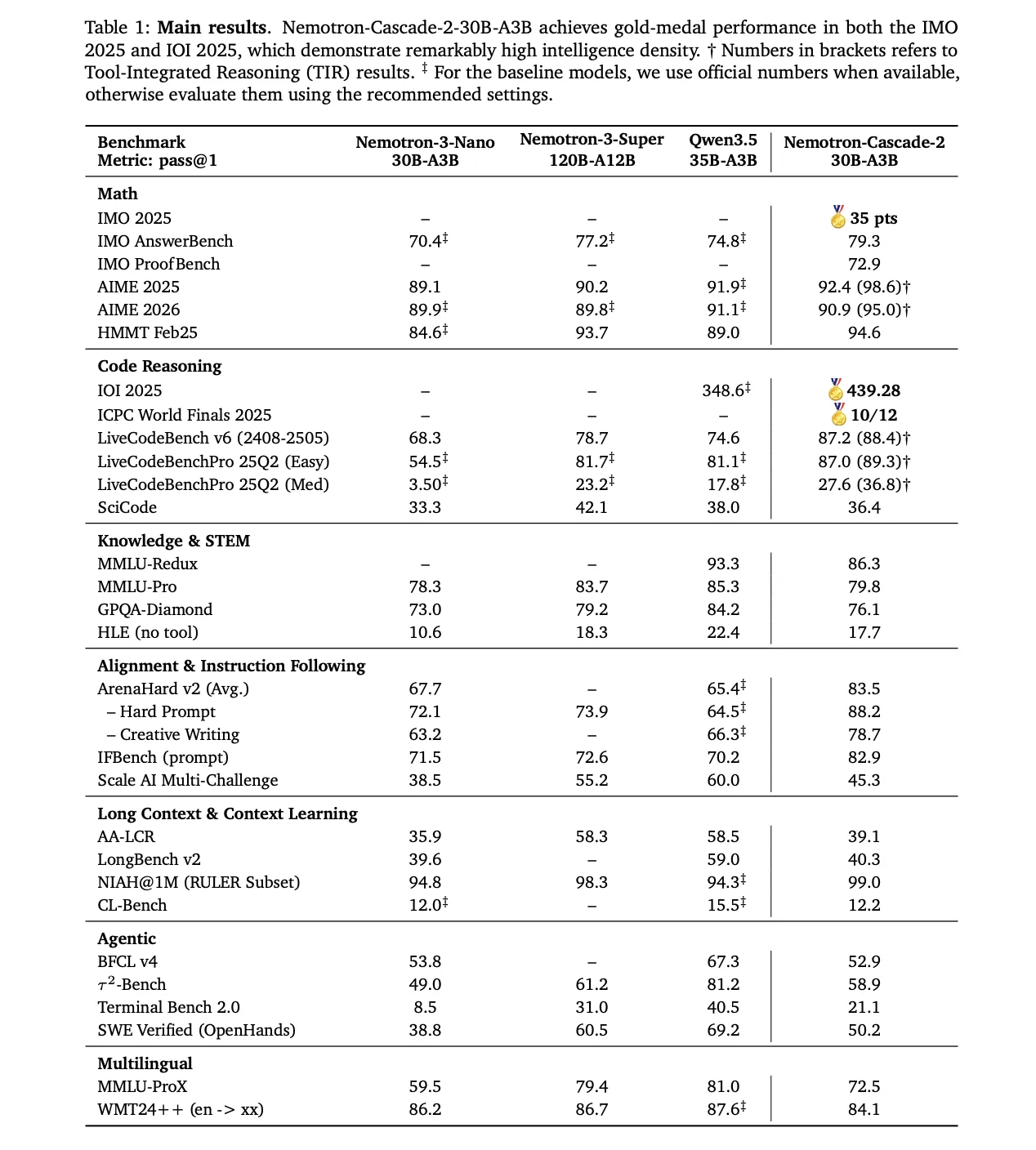
Technical Architecture: Cascade RL and Multi-domain On-Policy Distillation (The MOPD)
The reasoning abilities of this model range from its post-training pipeline, from Nemotron-3-Nano-30B-A3B-Base model.
1. Supervised Fine-Tuning (SFT)
During the SFT, the NVIDIA research team used a carefully selected data set in which the samples were stacked in a sequence of up to. 256K tokens. The dataset included:
- 1.9M Python logic methods and 1.3M Python tool calling samples for competitive coding.
- 816K samples for mathematical natural language proofs.
- A special Software Engineering (SWE) mix. which includes 125K agent and 389K agentless samples.
2. Cascade Reinforcement Learning
Following the SFT, the model went away Cascade RLsequential, domain-wise training. This prevents catastrophic forgetting by allowing hyperparameters to be optimized for certain domains without degrading others.. The pipeline includes instruction-following stages (IF-RL), multi-domain RL, RLHF, long-context RL, and special Code and SWE RL.
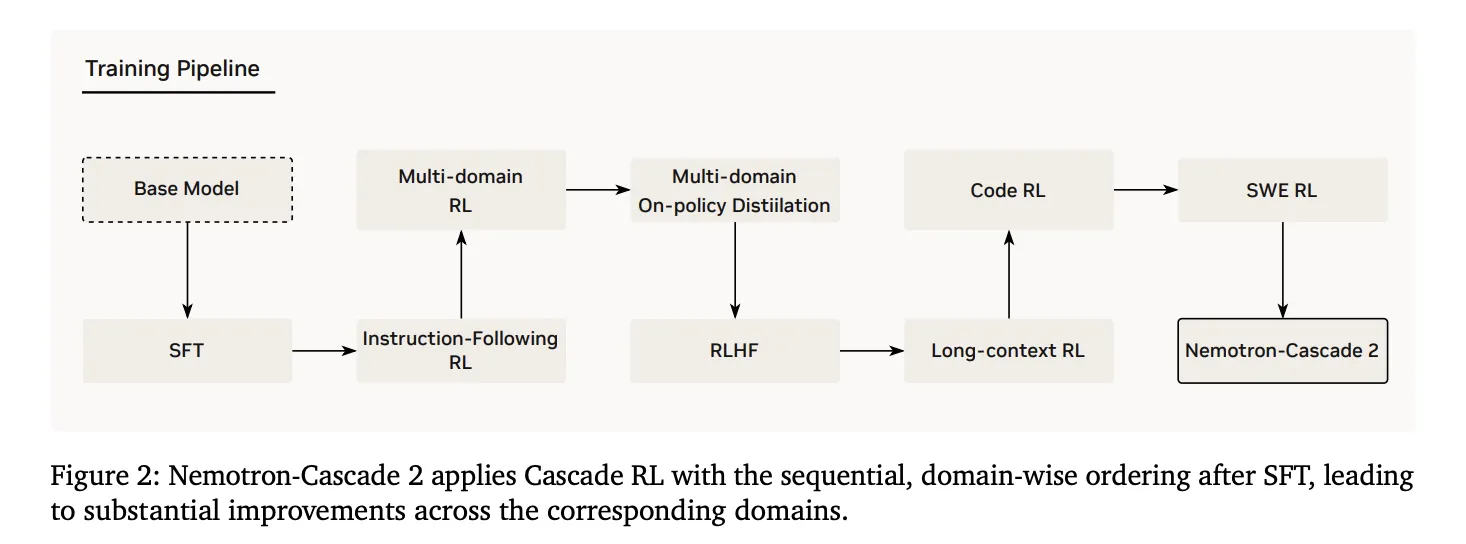
3. Multi-Domain On-Policy Distillation (MOPD)
A key innovation in Nemotron-Cascade 2 is the integration of The MOPD during the Cascade RL process. MOPD integration uses high-performance ‘teacher’ intermediate models—already derived from parallel SFT implementations—to provide the advantage of a dense level of token blinding. This benefit is mathematically defined as:
$$a_{t}^{MOPD}=log~pi^{domain_{t}}(y_{t}|s_{t})-log~pi^{train}(y_{t}|s_{t})$$
The research team found that MOPD performs better in sampling than sequence-level reward algorithms such as Group Relative Policy Optimization (GRPO). For example, Mr AIME25MOPD achieved teacher-level performance (92.0) within 30 measures, while GRPO only scored 91.0 after matching those measures.
Aspects of Inference and Agentic Interaction
Nemotron-Cascade 2 supports two main modes of operation with its dialog template:
- Thinking mode: It started with one
- Mindless Mode: It is activated by empty configuration
For agent functions, the model uses a formal tool calling protocol within the system information. The available tools are listed inside
Focusing on ‘intelligence density,’ Nemotron-Cascade 2 shows that special reasoning abilities once thought to be domain-specific for frontier-scale models (600B+ parameters) can be realized at 30B scale through domain-specific reinforcement learning.
Check it out Paper again Model in HF. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



