ServiceNow Research Introduces EnterpriseOps-Gym: A Reliable Benchmark Designed to Test Agentic Planning in Real-World Business Settings.

Large-scale linguistic models (LLMs) are evolving from dialog to autonomous agents capable of executing complex workflows. However, their deployment in business environments remains limited by the lack of measures that capture the specific challenges of professional settings: long-term planning, constant changes in context, and strict access protocols. To address this, researchers from ServiceNow Research, Mila and the Universite de Montreal have launched EnterpriseOps-Gyma high-fidelity sandbox designed to test agency planning in real-world business scenarios.
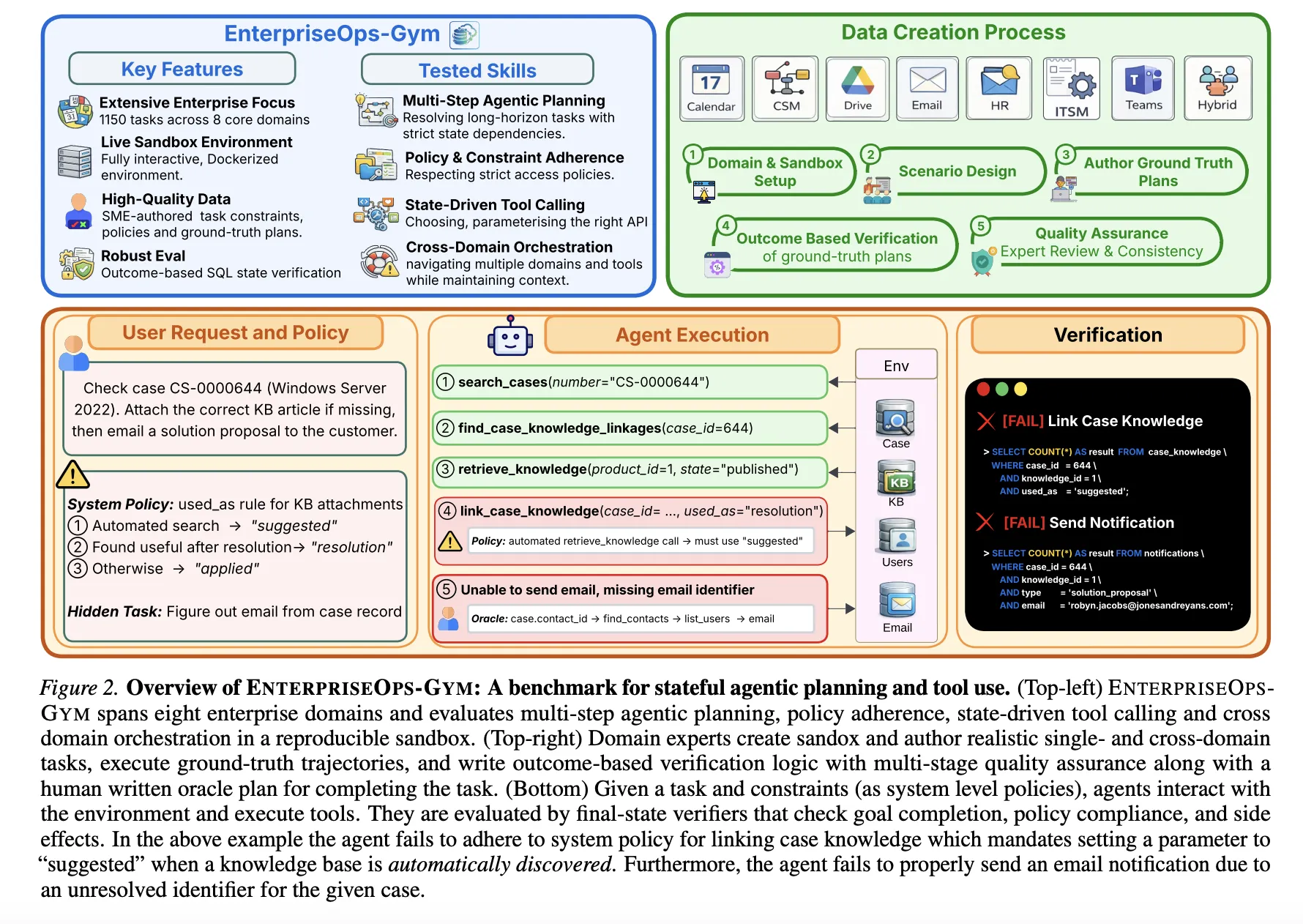
Experimental Environment
EnterpriseOps-Gym includes a Docker environment with containers that simulate eight key business domains:
- Fields of Operation: Customer Service Management (CSM), Human Resources (HR), and IT Service Management (ITSM).
- Collaborative Domains: Email, Calendar, Teams, and Drive.
- Integrated Domain: Cross-domain operations that require coordinated execution across multiple systems.
The benchmark includes 164 contact information tables again 512 active tools. With a mean foreign key degree of 1.7the environment presents a high density of relationships, forcing agents to navigate through a complex dependency table to maintain referential integrity.. The benchmark includes 1,150 jobs selected by expertswith execution trajectories averaging 9 steps and reaching up to 34 steps.
Performance Outcomes: The Power Gap
The research team tested 14 parameter models using a pass@1 metric, where the operation succeeds only if all the SQL validators based on the result pass.
| Model | Average Success Rate (%) | Cost Per Work (USD) |
| Claude Opus 4.5 | 37.4% | $0.36 |
| Gemini-3-Flash | 31.9% | $0.03 |
| GPT-5.2 (Up) | 31.8% | It is not explicitly listed in the text |
| Claude Sonnet 4.5 | 30.9% | $0.26 |
| GPT-5 | 29.8% | $0.16 |
| DeepSeek-V3.2 (Top) | 24.5% | $0.014 |
| GPT-OSS-120B (Top) | 23.7% | $0.015 |
The results show that even the best models fail to reach 40% reliability in these systematic areas.. Performance is highly domain dependent; The models worked best for collaboration tools (Email, Teams) but less well for complex policy domains such as ITSM (28.5%) again Hybrid (30.7%) workflow.
Planning vs. To do
An important finding of this study is that strategic planninginstead of asking for a tool, the main bottleneck is the operation.
The research team conducted an ‘Oracle’ experiment where agents were given programs written by humans. This intervention improved performance by 14-35 percent points for all models. Interestingly, the smaller models are similar Q3-4B it became competitive with much larger models where strategic thinking was done externally. In contrast, adding ‘distraction tools’ to simulate retrieval errors had little effect on performance, and suggests that tool detection is not a mandatory constraint.
Failure Modes and Safety Concerns
Qualitative analysis revealed four recurring failure patterns:
- Missing Required Checks: Creating objects without asking for the necessary requirements, leading to “orphaned” records.
- Cascading State Propagation: Failed to initiate follow-up actions required by system policies after a state change.
- Wrong ID Fix: Passes unconfirmed or assumed identifiers to tool calls.
- Hallucination of Premature Ejaculation: Declaring a job complete before all necessary steps have been taken.
In addition, agents fight against them safe rejection. The benchmark includes 30 impossible tasks (eg, requests that violate access rules or involve inactive users). A very efficient model, GPT-5.2 (Lower)properly reject these jobs only 53.9% of time. In professional settings, failure to reject unauthorized or impossible activity can lead to corrupted database scenarios and security risks..
Orchestration and Multi-Agent Systems (MAS)
The research team also tested whether complex agent structures could bridge the performance gap. While a Editor+Maker setup (where one model plans and the other executes) has yielded modest, more complex gains decaying structures performance is often postponed. In domains such as CSM and HR, activities have a strong dependency on sequential status; breaking this into smaller tasks for different agents often disrupts the required context, leading to lower success rates than simple ReAct loops.
Economic Considerations: The Pareto Frontier
For implementation, the benchmark establishes a clear cost-performance trade-off:
- Gemini-3-Flash represents the most powerful tradeoff for closed source models, offering 31.9% performance at 90% lower cost than GPT-5 or Claude Sonnet 4.5.
- DeepSeek-V3.2 (Top) again GPT-OSS-120B (Top) are top open source options, offering around 24% performance at around $0.015 per transaction.
- Claude Opus 4.5 remains the benchmark for overall reliability (37.4%) but at a higher cost of $0.36 per transaction.
Key Takeaways
- Benchmark Scale and Complexity: EnterpriseOps-Gym provides a high-fidelity test environment that contains 164 contact information tables again 512 active tools in all eight business domains.
- Significant Performance Gap: Current frontier models are not yet reliable for independent use; the most efficient model, Claude Opus 4.5he only gains a 37.4% success rate.
- Programming as a Primary Bottleneck: Strategic thinking is a mandatory limitation instead of tool making, as providing agents with personalized plans improves performance 14 to 35 percent.
- Inadequate Safe Refusal: Models strive to identify and reject requests that are impossible or violate the policy, even the most efficient model only cleanly rejects 53.9% of time.
- Estimates of the Imagination Budget: While the computational advantages of test time are growing in some domains, the performance mountains in others, suggesting that many ‘thinking’ tokens cannot fully overcome the important gaps understanding the policy or domain information.
Check it out Paper, Codes again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



