
Most search agents try to handle multiple tasks at once. They create new questions, remember what they’ve already tested, gather evidence, and decide what’s relevant as the search progresses. That can make the whole process messy, expensive, and difficult to manage.
Harness-1 takes a simpler approach. Developed by researchers from UIUC, UC Berkeley, and Chroma, it separates the task of finding search terms from the task of tracking search progress. The result is a compact recovery agent that feels easy to think about and performs more than its size might suggest.
In this article, we take a closer look Wires-1 and why its approach to recovery agents is important.
Why Are Search Agents Plateau?
Many recovery agents are trained end to end. The model generates questions, reads the passages, decides what is important, and stores all that context in the developing script. The policy reads everything, search strategy, evidence tracking, replication, and those stop situations as well.
The problem is learning to strengthen and trying to improve all of this at the same time. Semantic search decisions such as if I should search for “date of incorporation” or “year of acquisition” conflict with low-level bookkeeping. Have I seen this episode before? RL ends up developing both, and frankly, they don’t share the same learning process. So, there is less waste.
Researchers call this core design flaw. Their maintenance is clean, remove the country managers from the model and install the harness.
What Does a Harness Really Do?
A noble harness brings great success. The harness drives the model like a state machine. It maintains these four persistent structures throughout the passage:
- The candidate pool contains all compressed documents, extracted from all candidate searches.
- The selected set is the final result with up to 30 documents associated with priority flags (
very_high,high,fair,low). - A full-text store contains all returned data, stored without machine information.
- An evidence graph is a collection of automatically extracted entities, their bridge documents, and singleton traces.
The proof graph part of this structure is very clever. The regex extractor scans each piece of returned data for proper nouns, years, and dates. Bridge documents that contain two or more entities that are often found together are marked as very important. Singletons mark potential tracking searches. At each stage of the game, the harness presents this information in an efficient, integrated way.
Eight-Tool Interface
Eight model-based tools apply to each turn. Always, the model outputs exactly one action.
Two-stage compression is applied to the output from the retrieval stage. The first compression stage uses Sentence-BM25 to rate all sentences and select the top 4 from each sentence. The second stage of compression is achieved by two-level deduplication: the first stage is deduplication by chunk ID, the second stage is deduplication by content fingerprint. The policy never sees raw retrieval output before the completion of two deduplication phases.
The design paid off, as the model kept its core clean. The model has only processed tokens, and all tokens are not noise.
The Cold Start Problem (And Its Solution)
The first problem in retrieval training is determining how the policy learns to create a selected data set out of nothing, which leads to randomization in the first few RL bits of the policy. Because the initial state of the policy doesn’t have any priors to filter on, we don’t know how to filter. Therefore, the policy drops everything in the selected dataset or does not select at all.
Harness-1 addresses this issue by using warm seeds. After the harness searches successfully for the first time, it automatically generates a selected data set using the top 8 reconstructed results that were marked with a correctness rating. Thus, the policy has a corrective function (correction, increasing the number of quality documents and reducing the quality of weak documents) instead of the main function (extracting all documents and creating from scratch).
This small change creates a significant amount of stability in training and shows that filtering is more easily learned through refinement than creation.
How Training Works: SFT Then RL
There are two stages in the training line that do different types of work:
Stage 1: Supervised Fine Tuning
The teacher model (GPT-5.4) works in full harness in a live environment and is trained on a large set of different questions in this session. After filtering out all the non-functional leads we are left with a total of 899 episodes that include the correct use of the interface to train the model how to call tools, structure actions, and update the selection set.
# LoRA configuration for SFT
lora_config = {
"rank": 32,
"target_modules": ["q_proj", "v_proj"],
"base_model": "gpt-oss-20b",
"epochs": 3,
"checkpoint_for_rl": 550, # step-550 initializes RL training
}Phase 2: Reinforcement Learning
In the second phase of Reinforcement Learning, the CISPO in the policy is implemented with a reward function based on terminal rewards only, and has a limit of 40 turns. The training data consisted of SEC (financial document) questions, but the policies learned through training in this phase were able to be fulfilled in all 8 observation domains. Reward activity has two major advantages:
- The first advantage is the separation of acquisition and selection. These two features are given as independent rewards when a find is found and filtered (ie, a suitable document is found and selected).
- The second benefit is the added bonus of the versatility of the tools being used. This bonus is more important than you might think.
Without the diversity bonus, the agent gets stuck in a loop. The agent repeatedly issues the same search query in slightly different forms, fills the selection set with many similar items, and the experience stops (selected memory 0.53). The agent learns to use grep_corpus, verifyagain read_document In addition to search_corpus where the diversity bonus is added, and as a result, the agent’s recall score increases to 0.60 from this single change.
# Simplified reward structure
def compute_reward(episode):
discovery_score = count_newly_found_relevant_docs(episode)
selection_score = curated_recall(episode.final_curated_set)
diversity_bonus = tool_diversity_score(episode.action_sequence)
# Terminal reward only - no intermediate shaping
return selection_score + 0.3 * discovery_score + 0.2 * diversity_bonusHands Open: Running Harness-1 in place
Let’s try it.
- This repo is currently in use
uvfor dependency management and vLLM deployment. You will need to have enough GPU VRAM to run the 20B model. For example, one A100 (80GB) will work fine. Alternatively, two A100s (40GB) will work very well using tensor parallelism if you have them. - Remove the storage area and install it
git clone
cd harness-1
# If you haven't installed uv, do it now
pip install uv
# Pull all dependencies including vLLM
uv sync --extra vllmNote that pulling vLLM and its CUDA dependencies is done with --extra vllm and it may take some time during the first download of the package. If you do not follow this step, the indexing script will not run because of the dependency on the vLLM server.
- When you start using the app with this installed model it will download about 40GB of weight from HuggingFace and set up a compatible OpenAI local server using uvicorn. After uvicorn has started and you can open the server you should be able to use your model.
uv run python inference/vllm_local_inference.py serve
--model pat-jj/harness-1
--served-model-name harness-1If you have two GPUs, you can add --tensor-parallel-size 2 to create a split between both GPUs. Without this option, you will run out of memory problems with a single, 40GB, GPU.
- The execution of step 3 means that you can now issue a search request directly to the Harness-1 server. You should format your search request as a formal query directed at the Chroma corpus. Here’s what a small test would look like, using the BrowseComp+ benchmark format:
from openai import OpenAI
client = OpenAI(base_url=" api_key="none")
response = client.chat.completions.create(
model="harness-1",
messages=[
{
"role": "user",
"content": "Search for documents about the 2024 EU AI Act enforcement timeline.",
}
],
max_tokens=512,
temperature=0.0, # deterministic for eval runs
)
# The model emits a structured tool action - parse it
action = response.choices[0].message.content
print(action)In answering your question, you will get output that is non-narrative in nature. Output will be in the form of planned action; e.g fan_out_search(queries=["EU AI Act enforcement 2024", "AI Act timeline implementation"]). This is to be expected as Harness-1 is a small retrieval agent as opposed to a conversational model. The output of Harness-1 will then be sent to the harness, which will process the action against your corpus.
- After a full search session is completed, you can see important metrics in the log file.
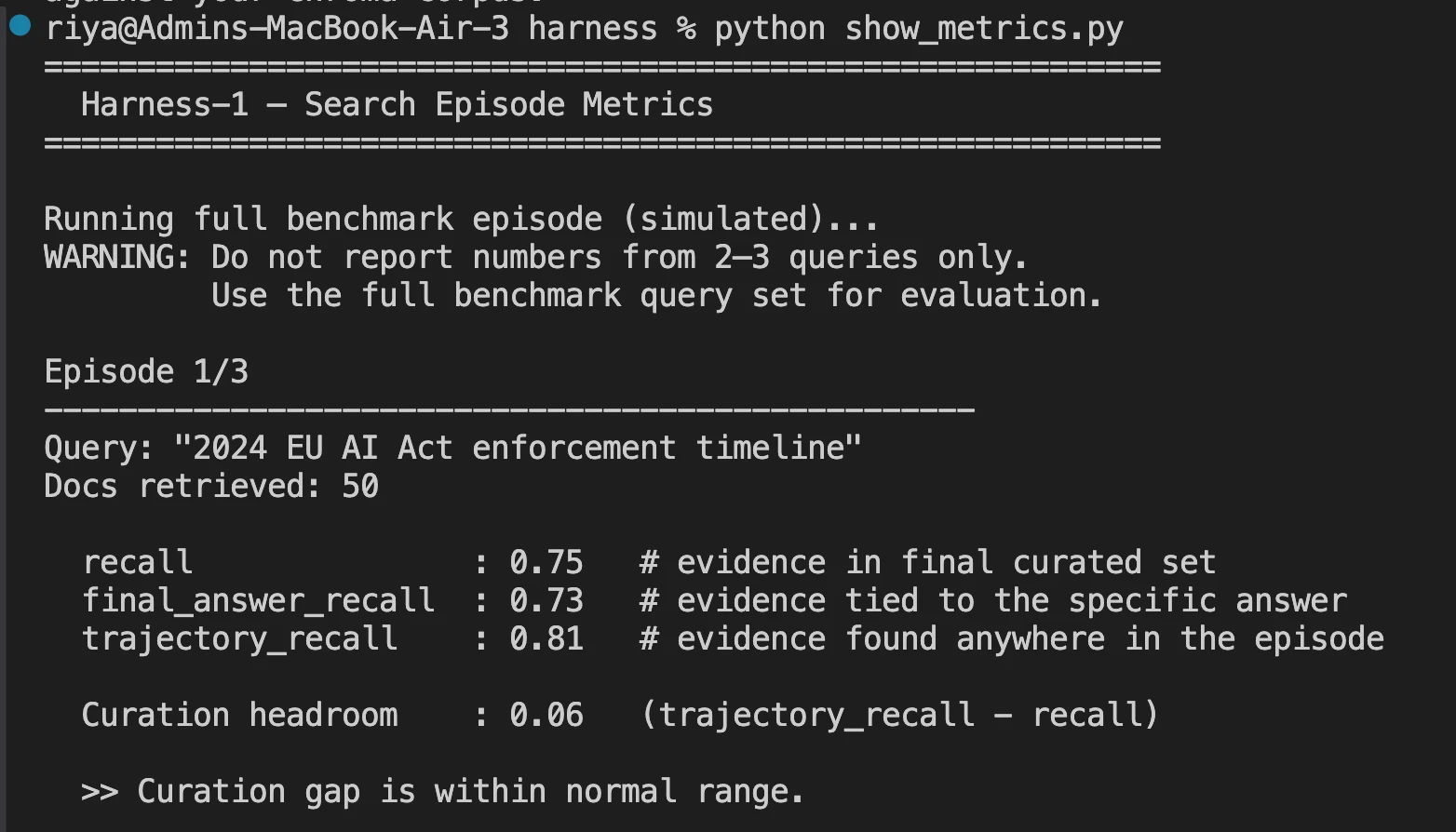
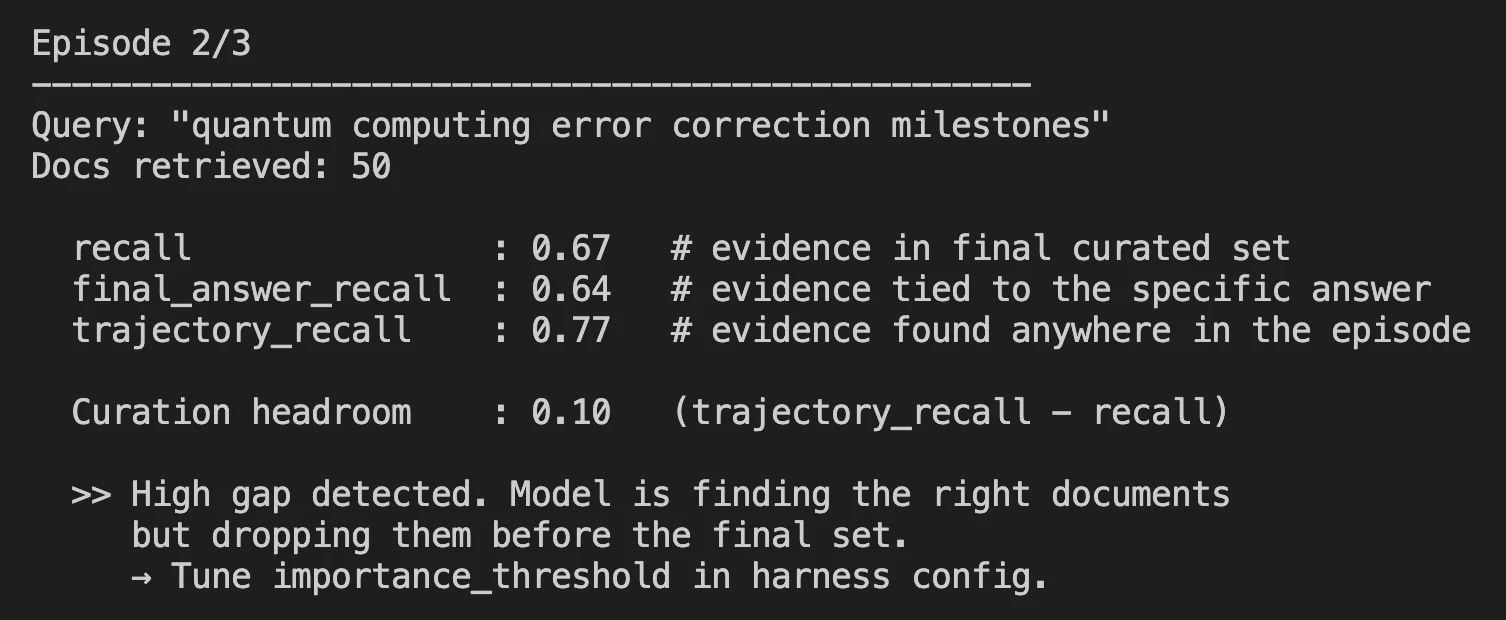
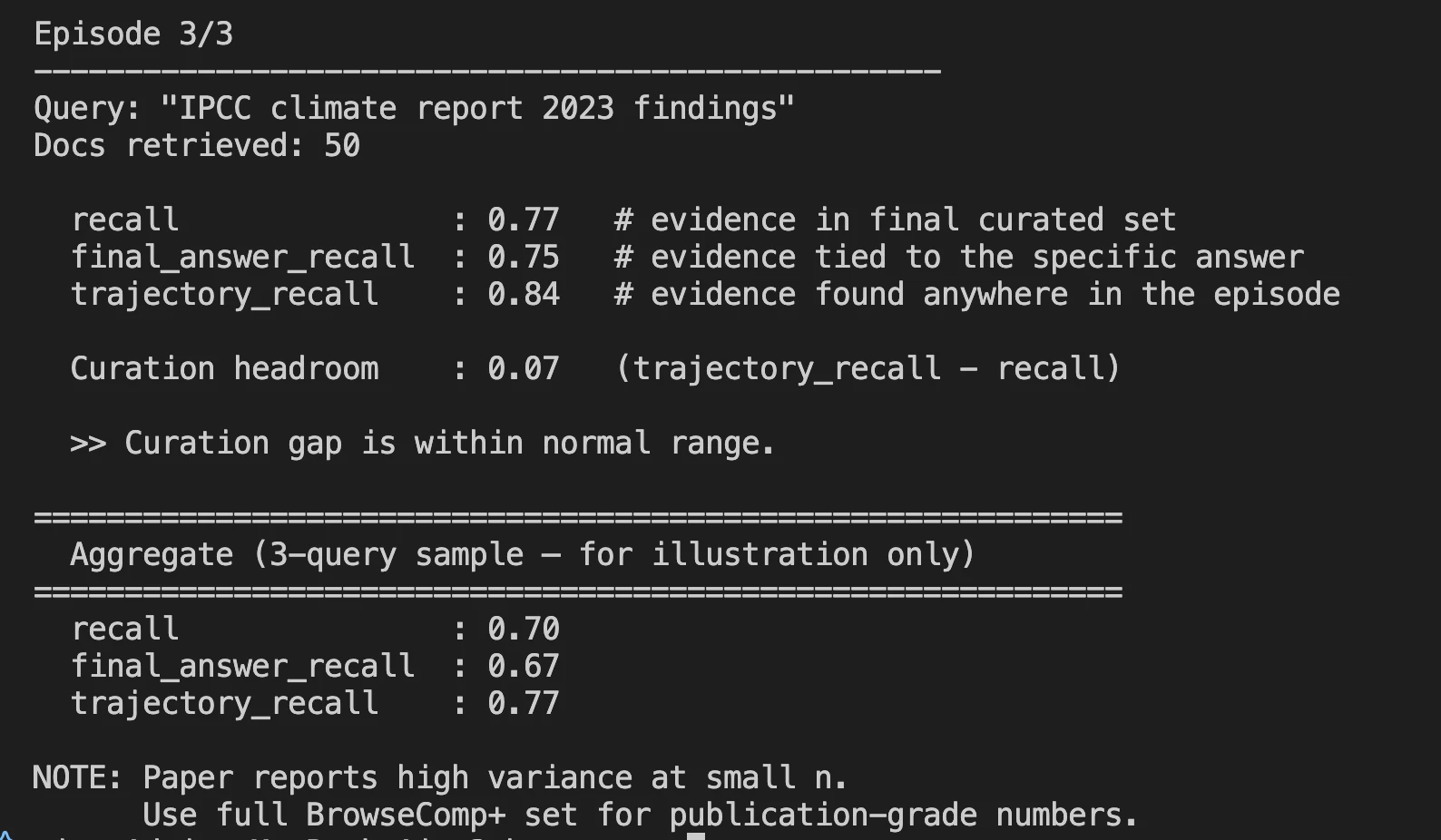
Measurement Results: Where It Stands
Harness-1 was tested against eight different benchmarks, including web search, SEC filings, patents, and multi-hop query answering (QA).
Curated Recall is the main metric used to measure the performance of Harness-1, that is, what percentage of all relevant documents created by Harness-1 in the last output of 30 documents in total, made it into the output.
| Model | The size | Selective Recall | Trajectory Recall |
|---|---|---|---|
| Wires-1 | 20B is open | 0.730 | 0.807 |
| Tongyi DeepResearch | 30B is open | 0.616 | 0.673 |
| Context-1 | 20B is open | 0.603 | 0.756 |
| Search for R1 | 32B is open | 0.289 | 0.289 |
| Opus-4.6 | border | 0.764 | 0.794 |
| GPT-5.4 | border | 0.709 | 0.752 |
| Sonnet-4.6 | border | 0.688 | 0.725 |
| For me K2.5 | border | 0.647 | 0.794 |
What Does Harness-1 Not Do?
It is a small retrieval agent, which returns a standard document set and does not do any reasoning, summarizing, or combining the response on that document set. Therefore, the response model below is not considered comprehensive.
RL training has only been performed on SEC queries, but it is promising to see transfer performance to web-based, patent and multi-hop QA queries. However, we did not consider domain customization as part of the training setup. The structure of financial documents is very different from Wikipedia’s multi-hop chains.
Additionally, the 899 SFT trajectories make up a relatively small dataset. In addition, the teacher was GPT-5.4, which is expensive. Therefore, it is still an open question how to measure the trajectory collection process.
The conclusion
The Harness-1 type shows that general AI systems stack up better than the monolithic type. As such, a 20B model, trained for light work, with a well-designed harness, ends up performing better than the borderline models. 5 times the parameters. Not only is it some architectural triumph, it feels like a recipe, really.
The weights and the harness code are public, so if you’re building anything with retrieval like RAG pipelines, research agents, document Q/A, all that stuff, this setup should be looked at carefully.
Also, there’s a reason the open heavyweight leaderboard has been heavily loaded with frontier models over the past year. Harness-1 is the most accurate point so far.
Frequently Asked Questions
IA. Harness-1 is an open 20B discovery subagent designed to improve document search and selection.
A. It separates the search from the state management, keeping the model clean and reducing the noisy return signals.
A. It does not summarize or think about the texts; returns only the standard document set.
![]()
Data Science Trainee at Analytics Vidhya
I currently work as a Data Science Trainer at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analysis, I am passionate about using AI to create impactful, innovative solutions that bridge the gap between technology and business.
📩 You can also contact me at [email protected]
Sign in to continue reading and enjoy content curated by experts.



