Poetiq’s Meta-System Automatically Builds Model-Agnostic Harness Enhanced All LLM Tested in LiveCodeBench Pro Without Fine-Tuning

Poetiq has recently published very interesting results showing that its Meta-System has reached a new state of the art in LiveCodeBench Pro (LCB Pro), a competitive coding benchmark, by automatically building and optimizing its logic harness – without fine-tuning any base model or accessing internal models.
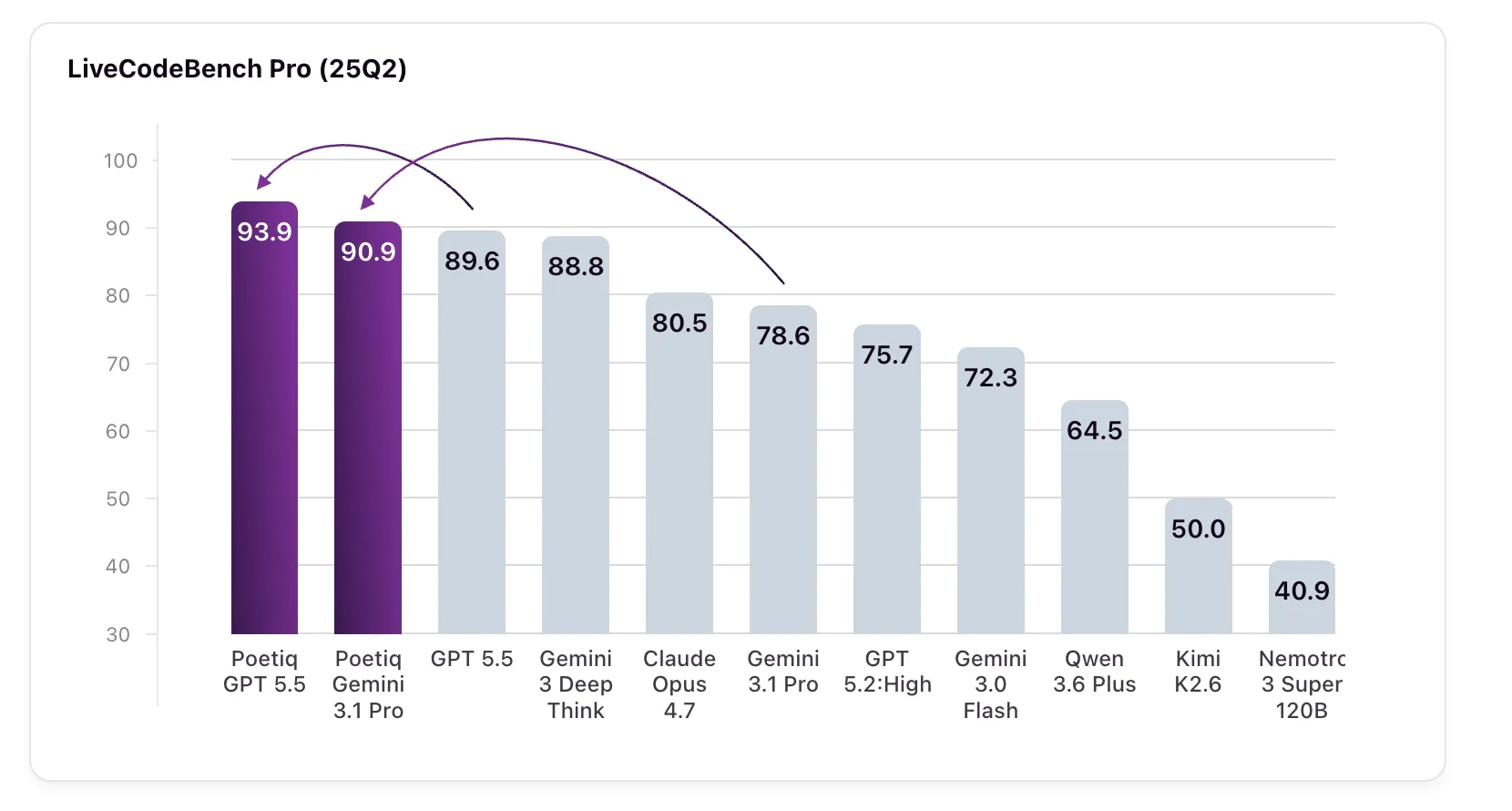
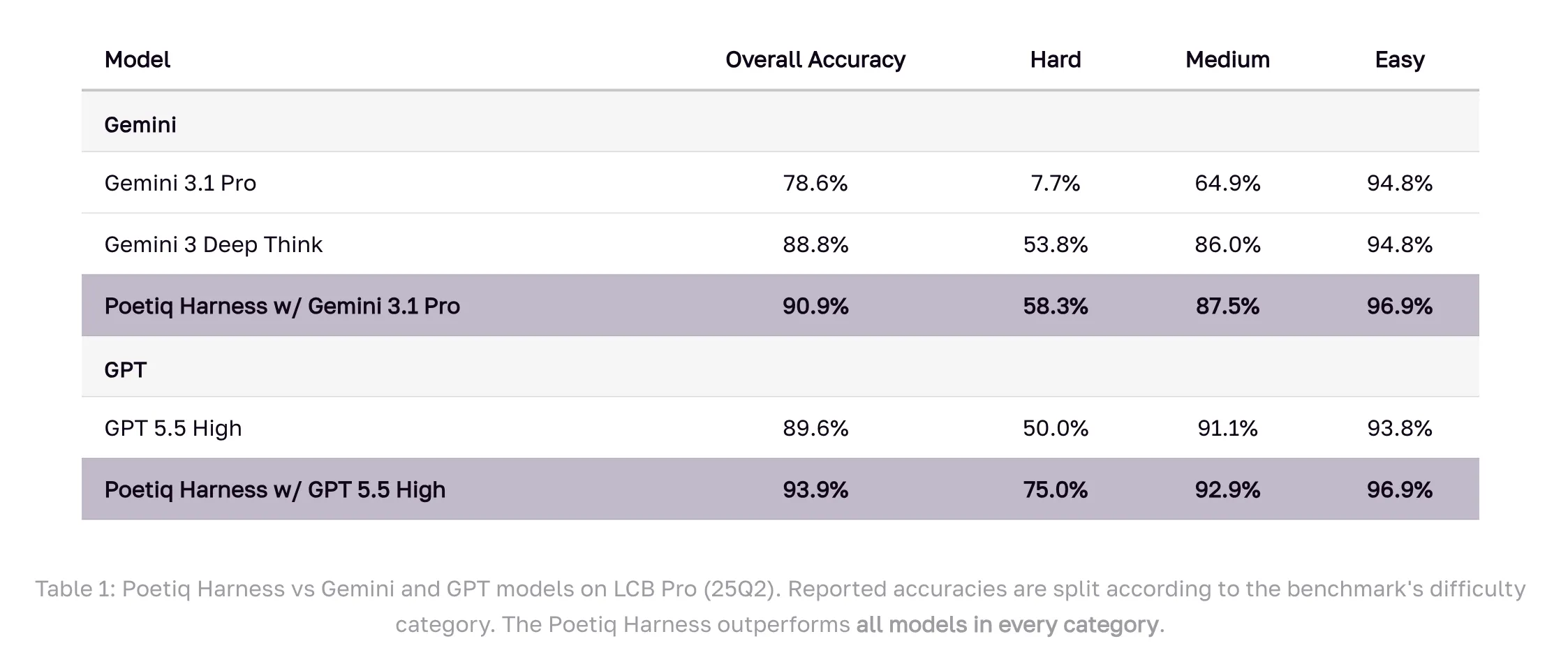
Result: GPT 5.5 High with Poetiq’s harness scores 93.9% on LCB Pro (25Q2), up from its baseline of 89.6%. Gemini 3.1 Pro, a specially configured harness model, jumps from 78.6% to 90.9% — surpassing Google’s Gemini 3 Deep Think (88.8%), a model that is not even accessible through an API for external verification.
What is LiveCodeBench Pro?
Before getting into the mechanics, it helps to understand why benchmarking is important. LiveCodeBench Pro (LCB) is designed to test AI coding ability in a way that resists two common failure modes in benchmarks: data contamination and overfitting.
LCB Pro abstracts problems from major programming competitions and reserves the ground truth code for the community. Instead, solutions are validated against a comprehensive evaluation framework. Correct output alone is not enough – solutions must also satisfy certain memory and runtime constraints. The benchmark is also subject to continuous updates, which differentiates it from most general benchmarks that become outdated.
The benchmark focuses on C++ challenges and emphasizes creative coding, testing the model’s capacity to solve complex problems and high-quality, functional process methodology. This sets it apart from datasets like SWWEBench that test tool usage or debugging workflows. The problems are divided by difficulty – Easy, Medium, and Hard – based on the level of competition people solve.
Poetiq’s Strategic Framing: Three Phases of the LLM Project
This is Poetiq’s third publicly reported benchmark, and the choice of LCB Pro was deliberate. The research team organizes the LLM performance into three different categories of tasks: Reasoning Challenges (ARC-AGI is their trademark here), Retrieval Challenges (the Final Personality Test, or HLE), and Coding Challenges – which, like most commercial AI applications today, mix reasoning and retrieval with the generation of a special procedural concept.
Their coding initiative had three specific goals, namely: first, to prove that a smart harness can increase efficiency without proper configuration or special model access; second, ensure the Meta-System’s capacity for iterative self-improvement in automatically creating that harness; and third, show that the resulting harness is model-agnostic and can be applied to any model without modification. According to their results, all three are satisfied.
What Is A Horse, And Why Is It Important?
In this context, a harness refers to an infrastructure that is wrapped around a language model to handle a specific task. Think of it as an orchestration layer – it controls how the model is invoked, how the results are organized, how the responses are combined across multiple calls, and how the solutions are evaluated.
Traditionally, these harnesses are built by hand by engineers. Poetiq’s claim is that their Meta-System creates and optimizes these harnesses automatically, through iterative optimization. Internally, the Meta-System works by developing better strategies for deciding what to ask, adjusting the sequence of questions, and designing new ways to combine answers. The program is constantly combining learnings from past and current operations and data sets to create new, custom task-specific harnesses – and agents and orchestrations for other types of operations.
How to make a harness?
Poetiq’s Meta-System was tasked with the LCB Pro and built the harness from scratch using only the Gemini 3.1 Pro as the base model. Meta-System calculates all three types of LCB Pro tests: accuracy, runtime, and memory constraints. The system built on insights from his previous work at ARC-AGI and HLE when designing the harness. No optimization of the underlying model is done, and no access to internal models is required – only standard API access.
Once the harness was designed and developed for the Gemini 3.1 Pro, it was then used in a wide set of other models from different suppliers and generations – both open weights and proprietary – without any additional modifications. Every model tested is advanced.
Numbers
Benchmark results at all difficulty levels should be looked at in detail. In Difficulty – the category where the gaps between models are the largest – the Gemini 3.1 Pro with Poetiq’s harness scores 58.3%, up from its baseline of 7.7%. GPT 5.5 High and harness up to 75.0% on Hard, up from 50.0%. In all light and medium categories, the harness is also superior to all basic models.
Some of the smaller model results are also noteworthy. The Gemini 3.0 Flash improves by 10 percent, from 72.3% to 82.3% — surpassing the Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.2 High, all larger and more expensive models. This reflects a pattern Poetiq saw earlier in ARC-AGI, where their optimization allowed a smaller, more economical model to outperform a larger one. Kimi K2.6 sees the biggest jump: from 50.0% to 79.9%, a score improvement of about 30 percent. Nemotron 3 Super 120B improves by 12.8%.
Accuracy numbers are reported directly on the LCB Pro leaderboard at livecodebenchpro.com (25Q2). For models not featured on the leaderboard, Poetiq performed its own testing, cross-validating its test setup by replicating the leaderboard’s accuracy on base models.
Key Takeaways
- Poetiq’s Meta-System automatically creates task-specific harnesses through iterative optimization, without model configuration or internal model access.
- GPT 5.5 High with harness reaches 93.9% in LCB Pro (25Q2), up 4.3% from its base of 89.6%; Gemini 3.1 Pro jumps by 12.3% (78.6% → 90.9%)
- The harness is model-agnostic: optimized using only the Gemini 3.1 Pro, it developed every other tested model – open weights and proprietary – without modification.
- Gemini 3.0 Flash gains 10% in harness (72.3% → 82.3%), outperforming Claude Opus 4.7, Gemini 3.1 Pro, and GPT 5.2 High even though it’s smaller and cheaper
- Kimi K2.6 shows a gain greater than ~30 percent points (50.0% → 79.9%); Nemotron 3 Super 120B improves by 12.8%
Check it out Technical details here. Also, feel free to follow us Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



