Tencent AI Open Sources Covo-Audio: 7B Speech Language Model and Suggestive Line for Real-Time Audio Conversations and Consultations

Tencent AI Lab has been released Covo-Audioparameter 7B-end-to-end Large Audio Language Model (LALM). The model is designed to integrate speech processing and language intelligence by directly processing continuous audio input and generating audio output within a single architecture.
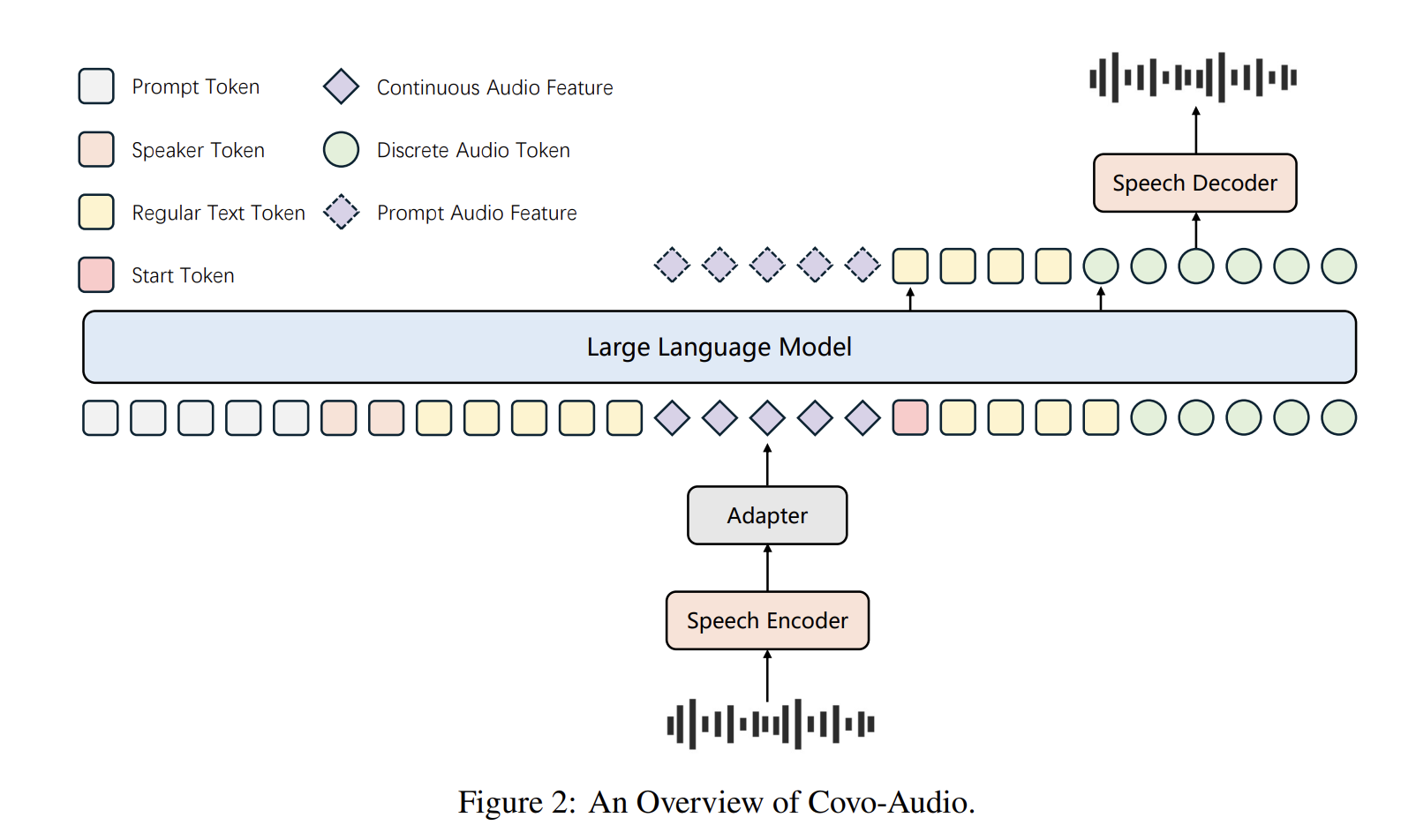
System Architecture
The Covo-Audio framework consists of four main components designed for seamless cross-modal interoperability:
- Audio encoder: The model is active gossip-big-v3 as its main contributor due to its robustness against background noise and various accents. This component works with a frame rate of 50 Hz.
- Audio adapter: To close the encoder and the LLM, a special adapter uses three downscaling modules, which combine direct and variable layers to reduce the frame rate from 50 Hz to 6.25 Hz.
- LLM Spine: The system is built upon Qwen2.5-7B-Baseadapted to process intermediate sequences of continuous acoustic features and text tokens.
- Speech Tokenizer and Decoder: A tokenizer, supported WavLM-largeuses a codebook size of 16,384 generating different audio tokens in 25 Hz. The decoder uses a Flow matching (FM) framework based and a BigVGAN high fidelity reconstruction encoder 24K waves of waves.
Hierarchical Tri-modal Interleaving
The core contribution of this work is Hierarchical Tri-modal Speech-Text Interleaving strategy. Unlike conventional methods that work only at the word or character level, this framework aligns continuous acoustic features. different speech tokens and natural language text
- Sequential Interleaving : Continuous features, text, and different tokens are arranged in a continuous series.
- Matching Matches : Continuous features are aligned with the integrated text-discrete unit.
The sequencing feature ensures structural consistency by using sentence-level breaks for proper alignment and sentence-level breaks to preserve global semantic integrity in long-form speech.. The training process involved processing a two-stage pipeline before full training 2T tokens.
Intelligence-Speaker Decoupling
In order to reduce the high cost of creating large conversational data for specific speakers, the research team proposed Intelligence Speaker Decoupling strategy. This technique separates the conversational intelligence from the voice rendering, allowing for flexible voice customization using minimal text-to-speech (TTS) data.
How to reformat high-quality TTS recordings into mock conversations with loss of hidden text. By excluding the text response component from the loss calculation, the model preserves its reasoning capabilities while inheriting the nature of the TTS speaker.. This enables personal communication without the need for a direct conversation dataset of the speaker.
Full Duplex voice interaction
Covo-Audio has evolved into Covo-Audio-Chat-FDa variant that can communicate with two streams at the same time. The audio encoder is reformatted into a streaming format, and the user and stream models are chunk-interleaved 1:4 ratio. Each episode represents 0.16s of sound.
The system manages conversational states by using certain property tokens:
- THINK TOKEN: Shows listen-only status while the model is waiting to respond.
- SHIFT token: Specifies to switch to the model’s speech curve.
- BREAK Token: Detects interference signals (barge-ins), triggers the model to immediately stop talking and return to listening.
In most cases, the model uses a an iterative strategy to fill the contextwhere persistent audio features from user input and tokens generated from previous iterations are initialized as context.
Auditory Thinking and Reinforcement Learning
To develop complex reasoning, the model includes Chain of Thought (CoT) to think and Group Relative Policy Optimization (GRPO). The model is developed using a proven compound reward function:
$$R_{total} = R_{accuracy} + R_{format} + R_{consistency} + R_{thinking}$$
This property allows the model to optimize the fit adherence to structured outputs reasonable compatibility and depth of thought .
Testing and Performance
Covo-Audio (7B) shows competitive or superior results in several benchmarks tested, with the strongest claims made for models of comparable scale and selected speech/audio functions. You have MMAU benchmark, get an average score 75.30%the highest among the 7B scale models tested. It is very successful in understanding music by score 76.05%. You have MMSU benchmark, Covo-Audio took the lead 66.64% average accuracy.
Regarding its conversational diversity, Covo-Audio discussion showed strong performance in RO-Benchespecially in speech consulting and conversational activities, the models work best as Qwen3-Omni on the Chinese track. To connect with empathy to VStyle benchmark, found modern results in Mandarin for anger (4.89), sadness (4.93), and anxiety (5.00).
The research team notes a ‘premature response’ problem in the full-duplex GaokaoEval setting, where unusually long pauses between speech fragments can cause premature responses. This ‘early response’ behavior relates to the model’s transient success metric and is identified as an important direction for future improvement.
Key Takeaways
- Unified End-to-End Architecture: Covo-Audio is a 7B parameter model that processes continuous audio input and produces high-fidelity audio output within a single, integrated structure. It eliminates the need for broken ASR-LLM-TTS pipelines, reducing error propagation and information loss.
- Hierarchical Tri-modal Interleaving: The model uses a special strategy to align continuous acoustic features, discrete speech tokens, and natural language text. By combining these methods at both the phrase and sentence levels, it maintains global semantic integrity while capturing well-analysed prosodic nuances.
- Intelligence-Speaker Decoupling: Tencent’s research team presents a method to distinguish conversational intelligence from specific voice rendering. This allows flexible voice customization using lightweight Text-to-Speech (TTS) data, significantly reducing the cost of developing personalized chat agents.
- Full Native Dual Interface: Covo-Audio-Chat-FD variant supports simultaneous listening and talking. It uses specific property tokens—THINK, SHIFT, and BREAK—to handle complex real-time dynamics such as smooth turn-taking, rollback, and user onboarding.
- Superior Parameter Efficiency: Despite its compact 7B rating, Covo-Audio achieves modern or very competitive performance in all major benchmarks, including MMAU, MMSU, and URO-Bench. It often matches or exceeds the performance of very large systems, such as 32B parameter models, on audio and speech recognition tasks.
Check it out Paper, Model in HF again Repo. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.

Michal Sutter is a data science expert with a Master of Science in Data Science from the University of Padova. With a strong foundation in statistical analysis, machine learning, and data engineering, Michal excels at turning complex data sets into actionable insights.



