Arcee AI Unveils Big Trinity Thinking: An Open Apache 2.0 Model for Long-Horizon Agent Intelligence and Tooling

The landscape of open source artificial intelligence has shifted from generative models to systems capable of complex, multi-step reasoning. Although ‘consultative’ ownership models dominate the discussion, Arce AI he has released The Trinity is a Great Thought.
This release is an open-weighted logic model distributed under the Apache License 2.0setting it up as an obvious alternative for developers building autonomous agents. Unlike models developed solely for conversational interaction, Trinity Large Thinking is specifically developed for horizon agents, dynamic tool calling, and maintaining context consistency over extended workflows.
Architecture: Sparse MoE at Frontier Scale
Trinity Large Thinking is a meditation-focused iteration of Arcee’s Trinity Large series. Technically, ia Mixed-Expert (MoE) model with 400 billion parameters in total. However, its design is designed for optimal performance; it only works 13 billion parameters per token using a 4-of-256 expert strategy.
This sparsity provides the global information density of a large model without the typical delays of dense 400B architectures. New technologies in the Trinity Large family include:
- SMEBU (Fixed Momentum Expert Bias Updates): A new MoE load balancing technique that prevents expert collapse and ensures the uniform use of special model methods.
- Muon Optimizer: Arcee used the Muon accelerator during the training of the pre-training phase of 17-trillion tokens, which allows for higher fees and better sampling efficiency compared to the standard use of AdamW.
- Attention Mechanism: The model incorporates local and global attention combined with gated attention to improve one’s ability to understand and remember details within large contexts.
Consultation
The main difference of Trinity Large Thinking is its behavior during the decision phase. The Arcee team in their documentation states that the model uses a ‘thinking’ process before delivering its final answer. This internal reasoning allows the model to plan multi-step tasks and validate its assumptions before generating a response.
Operations: Agents, Tools, and Content
Trinity Large Thinking is made for the ‘Agentic’ age. Rather than competing on general knowledge trivia alone, its performance is measured by its reliability in complex software environments.
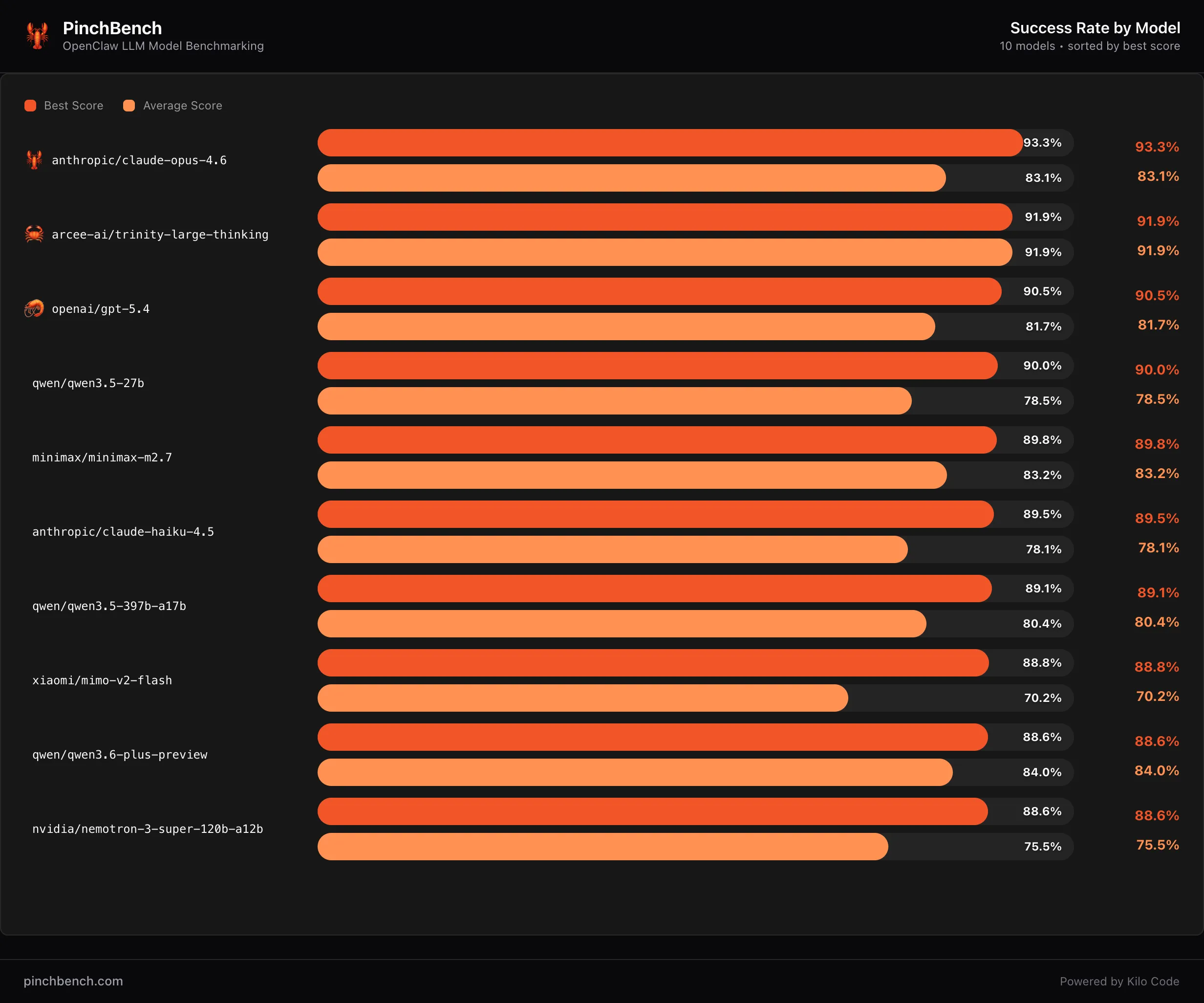
Ratings and standards
The model has shown strong performance in PinchBencha benchmark designed to test the model’s capabilities in autonomous agent environments. Currently, Trinity Large Thinking holds the #2 location on PinchBench, trailing behind only Claude Opus-4.6.
Technical Details
- Content Window: The model supports a Context window for 262,144 tokens (as listed on OpenRouter), enabling it to process large data sets or long conversation histories for agent loops.
- Multi-Turn Reliability: The training focuses on the use of multi-turn tools and systematic results, ensuring that the model can call APIs and extract parameters with high accuracy for many turns.
Key Takeaways
- High-Efficiency Sparse MoE Architecture: Trinity Large Thinking is a 400B-parameter sparse Mixture-of-Experts (MoE) model. It uses a 4-of-256 routing strategy, which only works 13B parameters per token at the time of decision to provide the intelligence of the boundary measurement speed and output of the smallest model.
- Designed for Agentic Workflow: Unlike normal chat models, this release is tuned specifically long-term jobsmulti-tool typing, and high precision following instructions. It is currently on the level #2 on PinchBenchbenchmark for independent agent capabilities, second only to Claude 3.5 Opus.
- Expanded Content Window: The model supports a wide context window for 262,144 tokens (on OpenRouter). This allows it to maintain consistency across large technical documents, complex code bases, and extended multi-step reasoning chains without losing track of the original instructions.
- Open True Identity: Distributed under Apache License 2.0Trinity Large Thinking offers ‘True Open’ weights available in Hugging Face. This allows businesses to test, fine-tune, and manage the model themselves within their infrastructure, ensuring data independence and compliance.
- Advanced Training Stability: To achieve marginal class performance with high cost efficiency, Arcee used Muon optimizer and a proprietary load balancing system called SMB (Soft-clamped Expert Bias Updates), which ensures stable expert use and prevents performance degradation during complex cognitive tasks.
Check it out Technical details again Model weight. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



