TII Releases Falcon Perception: A 0.6B-Parameter Early-Fusion Transformer for Open-Vocabulary Grounding and Segmentation from Natural Language Prompts

In the current state of computer vision, a common operating procedure involves a modular ‘Lego brick’ approach: a vision encoder pre-trained for feature extraction paired with a separate decoder for task prediction. Although effective, this separation of structures makes it difficult to measure and hinders the interaction between language and vision.
I Technology Innovation Institute (TII) a group of researchers are challenging this paradigm Falcon Perceptionparameter 600M-Transformer compact unit. By processing image patches and text tokens in a shared parameter space from the first layer, the TII research team made the first fusion a stack that handles visualization and task modeling with extreme efficiency.
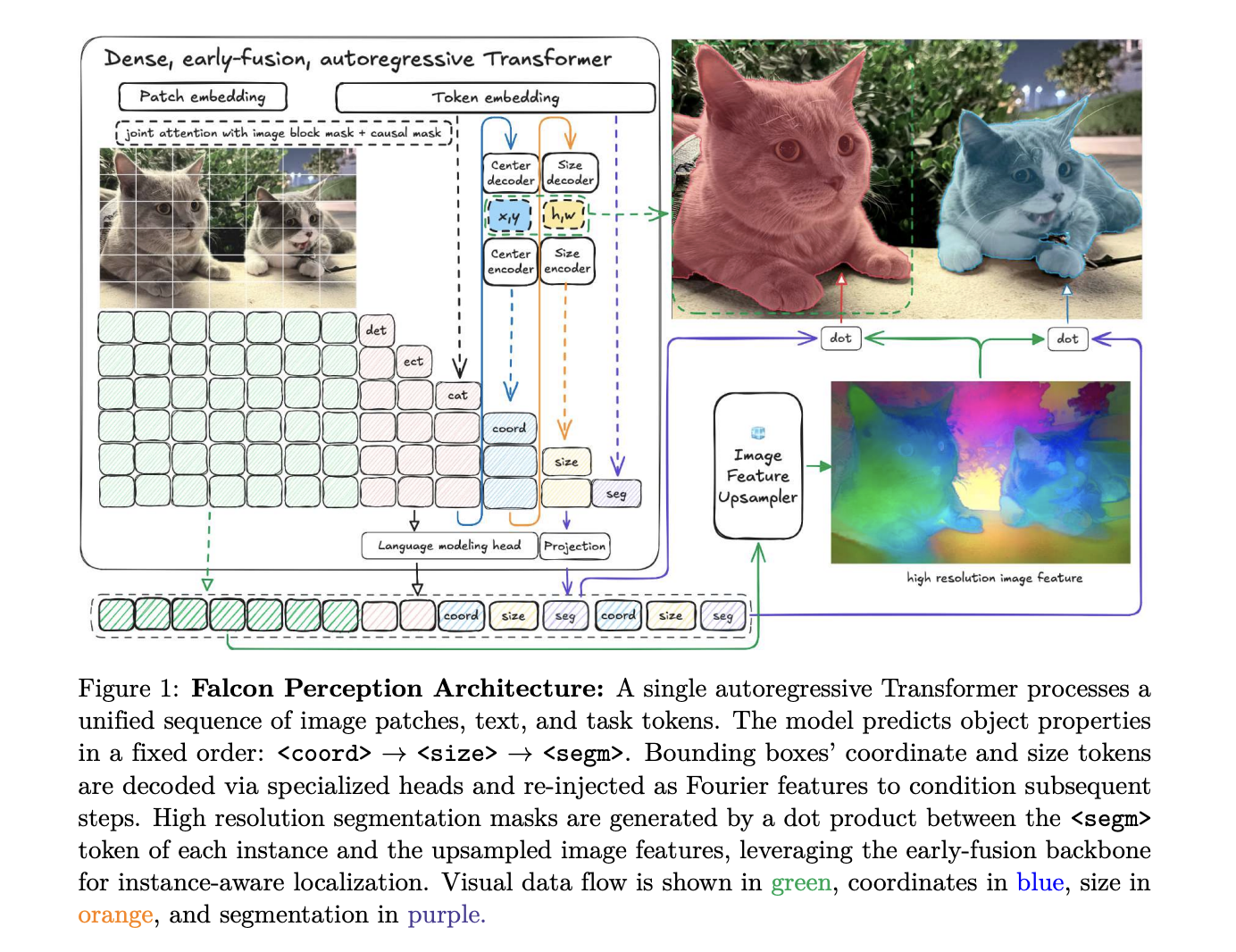
Architecture: One Stack for Every Behavior
The core design of Falcon Perception is built on the idea that a single Transformer can simultaneously learn visual representations and perform task-specific generation..
Hybrid Attention and GGROPE
Unlike standard language models that use strong causal masking, Falcon Perception uses a mixed attention strategy. Image tokens take care of each other in a dual way to create a global visual context, while text and function tokens take care of all previous tokens (masking) to enable automatic prediction..
To maintain 2D spatial relationships in a flat sequence, the research team uses 3D Rotary Positional Embedded. This decomposition of the head size into a linear component and a spatial component is used Golden Gate Rope (GGROPE). GGROPE allows attention heads to maintain corresponding positions according to specific angles, making the model robust to rotation and aspect ratio variations.
Minimalist Sequence Logic
The basic sequence of structures follows a Chain-of-Perception format:
[Image] [Text] .
This ensures that the model resolves spatial ambiguity (location and size) as a stop signal before generating the final phase mask..
Engineering Scale: Muon, FlexAttention, and Raster Ordering
The TII research team has introduced several optimizations to stabilize training and maximize GPU utilization for these diverse sequences.
- Muon development: The research team reports that recruiting i Muon optimizer on special heads (links, size, and separation) led to lower training losses and improved performance in benchmarks compared to the standard AdamW.
- FlexAttention packaging and sequence: To process images with native resolution without wasting a computer on padding, the model uses a disassembly and packing strategy. Valid sheets are packed into fixed-length blocks, too FlexAttention is used to limit attention within the boundaries of each image sample.
- Raster ordering: Where many things exist, Falcon Perception predicts them raster order (top-to-bottom, left-to-right). This was found to converge faster and produce lower link loss than random or size-based ordering.
Training Recipe: Distillation to 685GT
The model is used the distillation of many teachers to initiate, distilling knowledge from DINOv3 (ViT-H) by local factors and SigLIP2 (So400m) with language-aligned features. After initialization, the model passes a a three-stage vision training pipeline a total of approx 685 Gigatokens (GT):
- Table of Contents (450 GT): Learning to ‘write’ a list of scenes to create a world context.
- Alignment Work (225 GT): To switch to independent query functions you use Hiding the question to ensure that the model supports each query in the image only.
- Long-Context Finetuning (10 GT): A short adaptation of extreme density, which increases the mask limit to 600 per expression.
In these sections, a specific sequence of operations is used:
I
PBench: The Power of Profiling Beyond the Lines Used for Traffic
To measure progress, the TII research team presented PBenchbenchmark that organizes samples into five levels of semantic difficulty to distinguish failure modes of models.
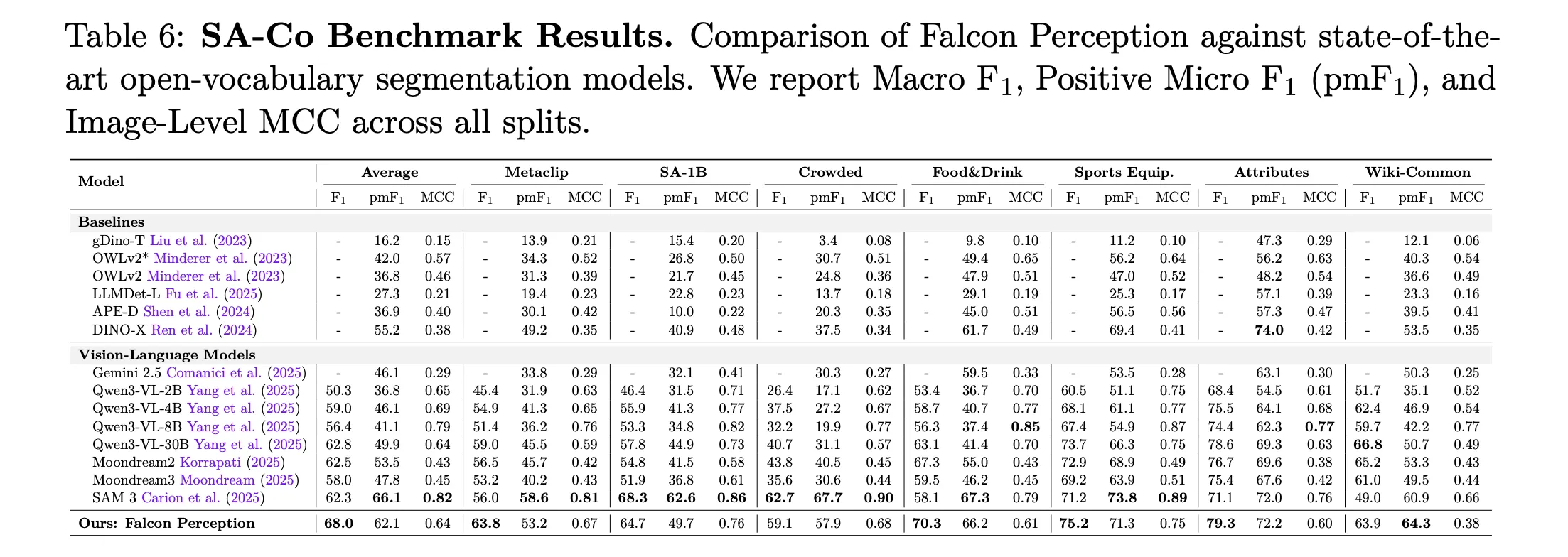
Main Results: Falcon Perception vs. SAM 3 (Macro-F1)
| Benchmark Split | SAM 3 | Falcon Perception (600M) |
| L0: Simple Things | 64.3 | 65.1 |
| L1: Attributes | 54.4 | 63.6 |
| L2: OCR-Guided | 24.6 | 38.0 |
| L3: Spatial Comprehension | 31.6 | 53.5 |
| L4: Relationship | 33.3 | 49.1 |
| Dense Split | 58.4 | 72.6 |
Falcon Perception is more effective than SAM 3 in complex semantic tasks, especially showing a +21.9 points advantage spatial orientation (Level 3).
FalconOCR: 300M Text Expert
The TII team also extended this early integration recipe to it FalconOCRcombined 300M-parameter model started from scratch to prioritize fine-grained glyph recognition. FalconOCR competes with many proprietary modular OCR programs:
- olOCR: He succeeds 80.3% accuracy.matching or surpassing Gemini 3 Pro (80.2%) and GPT 5.2 (69.8%).
- OmniDocBench: It achieves a perfect score of 88.64ahead of GPT 5.2 (86.56) and Mistral OCR 3 (85.20), though trailing the top module pipeline PaddleOCR VL 1.5 (94.37).
Key Takeaways
- Unified Early-Fusion Architecture: Falcon Perception replaces one dense modular-encoder-decoder Transformer pipeline that processes image patches and text tokens in a parameter space allocated from the first layer. It uses a hybrid attentional mask—a dual focus of visual tokens and causal activity tokens—to serve simultaneously as a perceptual encoder and an automatic encoder.
- Chain-of-Perception Sequence: The model organizes the classification of the instance into an orderly sequence which forces it to resolve location and size as a stop signal before generating a pixel-level mask.
- Special Heads and GGROPE: To handle dense spatial data, the model uses Fourier Feature encoders for high-dimensional coordinate mapping and Golden Gate ROPE (GGROPE) to enable isotropic 2D spatial attention. A muon optimizer is used in these special heads to measure the learning rates against a previously trained backbone.
- Benefits of Semantic Functionality: In the new PBench benchmark, which separates semantic power (Levels 0-4), the 600M model shows significant advantages over SAM 3 in complex categories, including a +13.4 point lead in OCR-oriented queries and a +21.9 point lead in spatial recognition.
- A very efficient OCR extension: The property rating comes down to Falcon OCR, a 300M parameter model that achieves 80.3% in olmOCR and 88.64 in OmniDocBench. It matches or exceeds the accuracy of larger programs such as Gemini 3 Pro and GPT 5.2 while maintaining high throughput for large-scale document processing.
Check it out Paper, Model Weight, Repo again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.



