Google AI Releases Automated Diagnostics: LLM’s System-wide Language Model for Analyzing Integration Testing Failures at Scale

If you’ve ever stared at thousands of lines of compile tests wondering which sixteen log files contain your error, you’re not alone – and Google now has the data to prove it.
Google’s research team was introduced Automatic identificationa powerful LLM tool that automatically reads failure logs from broken integration tests, finds the root cause, and sends a brief diagnosis directly to the code review where the failure was detected. In a manual analysis of 71 real-world failures that occurred 39 different groupsthe tool correctly identified the cause 90.14% of the time. It continued 52,635 different failure tests on the other side 224,782 executions to 91,130 code changes written by 22,962 different engineerswith only 5.8% of ‘Not helpful’ responses received.
The problem: integration tests are taxing for debugging
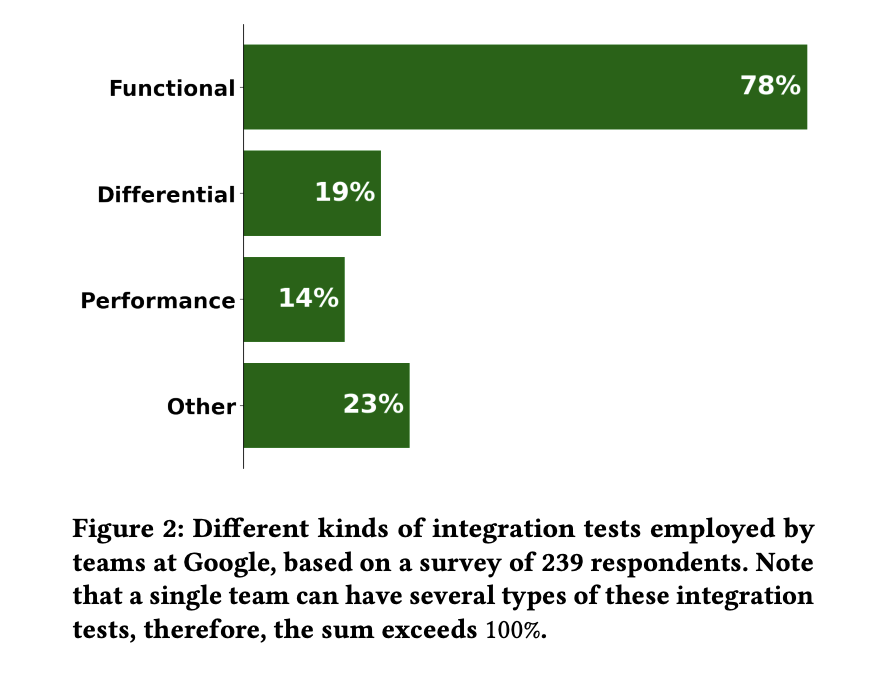
Integration testing ensures that the multiple components of a distributed system communicate properly with each other. Self-diagnostic test objectives are hermetic performance integration test: tests where the entire system under test (SUT) – usually a graph of communication servers – is scaled up in an isolated environment by a test driver, and used against business logic. A separate Google survey of 239 respondents found that 78% of Google’s integration tests workwhich is what inspired the range.
Failure to identify integration tests was shown as one of the top five complaints Sata comprehensive Google survey of 6,059 developers. A follow-up survey of 116 developers found that 38.4% of cluster test failures take more than an hour to diagnose, and 8.9% take more than a day – compared to 2.7% and 0% of unit tests.
The reason is the structure. Test driver logs usually only show the typical symptom (timeout, assertion). The actual error resides somewhere within the SUT log section, often buried under recoverable warning and ERROR level lines that are not actually the cause.

How Auto Diagnostics works
If the integration test fails, the pub/sub event triggers Auto-Diagnosis. The program collects all test driver and SUT component logs at the INFO level and above – across all data centers, processes, and threads – and joins and filters them by timestamp into a single log stream. That stream is included in the information template and component metadata.
Model i Gemini 2.5 Flashcalled no temperature = 0.1 (almost fixed, adjustable output) and topp = 0.8. Gemini didn’t fare well in Google’s integration test data; this is rapid engineering on a general purpose model.
The information itself is the most informative part of this study. It moves the model through a clear step-by-step protocol: scan sections of the log, read part of the context, find failures, summarize errors, and test the conclusion. Importantly, it includes serious negative issues – for example: if the logs do not contain lines from a failed component, do not draw a conclusion.
The response of the model is processed after the detection of the downlink with ==Conclusion==, ==Investigation Steps==again ==Most Relevant Log Lines== parts, then posted as comments to CriticismGoogle’s internal code review system. Each quoted log line is provided as a clickable link.
Numbers from production
Automatically check measurements 110,617 input tokens and 5,962 output tokens per executionand sends the findings via Latency for p50 of 56 seconds and p90 of 346 seconds – fast enough for engineers to see the diagnosis before they change conditions.
Critique presents three feedback buttons for discovery: Please correct (used by reviewers), It is usefulagain It doesn’t help (both used by the authors). 517 complete reports from 437 different developers, 436 (84.3%) said “Please fix” from 370 reviewers – excellent communication, and a sign that reviewers are asking authors to do something about the diagnosis. Among the dev-side response, the help rate (H / (H + N)) is 62.96%, while the rate of “Not helpful” (N / (PF + H + N)) is 5.8% — below Google’s 10% threshold to keep the tool live. On the other side 370 instruments submit findings to CritiqueAutomated Test Standards #14 in assists, up 3.78%.
Manual testing also revealed a useful side effect. Of the seven cases where Auto-Diagnose failed, four were because the test driver logs were not properly saved from the crash, and three were because the SUT component logs were not saved when the component crashed – both real infrastructure bugs, reported to the appropriate teams. In production, about 20 ‘more information is needed‘ diagnosis helped equally infrastructure problems.
Key Takeaways
- Automatic diagnosis reached 90.14% root cause accuracy in a manual analysis of 71 real-world integration test failures spanning 39 teams at Google, 6,059 developers faced issues ranked among their top five complaints in the EngSat survey.
- The program runs on Gemini 2.5 Flash without proper configuration – fast engineering. The pub/sub trigger collects logs from all data centers and processes, joins them with a time stamp, and sends them to the model at a temperature of 0.1 and abovep 0.8.
- The information is designed to reject rather than guess. Hard negative constraints force the model to respond with “more information needed” when the evidence is lacking – a deliberate trade-off to prevent root causes and help reveal real infrastructure bugs in Google’s logging pipeline.
- In production since May 2025, Auto-Diagnose has worked on 52,635 failed tests among 224,782 executions for 91,130 code changes from 22,962 developers.posting findings on p50 in 56 seconds – fast enough for developers to see the diagnosis before changing the content.
Check it out Pre-print paper here. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



