Google DeepMind Introduces Released DiLoCo: An Asynchronous Training Architecture That Achieves 88% Goodput Under High Hardware Failure Rates

Training frontier AI models is, at its core, a correlation problem. Thousands of chips must communicate continuously, synchronizing all gradient updates across the network. If one chip fails or slows down, the entire training run may stop. As models grow to hundreds of billions of parameters, those weaknesses become increasingly unworkable. Google DeepMind now proposes a completely different model.
Introduced by Google DeepMind researchers DiLoCo isolated (Distributed Low-Communication), the creation of distributed training that separates into ‘islands’ that are asynchronous, isolated from the error, which allows a large language model to be pre-trained in all remote data centers without requiring strict synchronization that makes conventional methods difficult to scale.
The Problem with Traditional Distributed Training
To understand why Decoupled DiLoCo is important, it helps to understand how distributed training works in general. General Data-Parallel training returns the model to multiple accelerators (GPUs or TPUs), each processing a small set of data. After each forward and backward pass, the gradients must be equalized for all devices – a process called Everything Reduce – before the next training step begins. This step to prevent synchronization means that every device has to wait a very small time. For the thousands of chips that make up most data centers, that restriction isn’t just an inconvenience; it makes world-class training impossible.
Bandwidth is another difficult constraint. Conventional Data-Parallel training requires approximately 198 Gbps of inter-datacenter bandwidth across all eight data centers – more than a typical wide area network (WAN) can support between geographically distributed locations.
How Decouple DiLoCo Works
Decouple DiLoCo builds on two previous systems from Google. The first one is Methodswhich introduces a distributed AI system based on asynchronous data flow, allowing different computing resources to work at their own pace without interfering with each other. The second says DiLoCowhich dramatically reduced the bandwidth required for distributed training by having each worker perform multiple gradient steps before communicating with peers – dramatically reducing how much data needs to flow between data centers.
Decouple DiLoCo combines both ideas. Built on Pathways, training is divided into different clusters called accelerators student units – ‘islands’ of accounting. Each learner unit trains independently, performing multiple local steps, before sharing a compressed gradient signal with an external stimulus that aggregates updates to all learner units. Because this external synchronization step is asynchronous, the failure of a chip or a slow learner unit in one island does not prevent the others from continuing to train.
The bandwidth savings are amazing. Decoupled DiLoCo reduces the required inter-datacenter bandwidth from 198 Gbps to just 0.84 Gbps across eight data centers – many orders of magnitude lower – making it compatible with standard Internet-scale connections between datacenters instead of requiring high-speed network infrastructure.
Making a living as a Chaos Engineer
One of the most important aspects of Decoupled DiLoCo technology is fault tolerance. A research team was used chaos engineeringa method that deliberately introduces artificial hardware failures into a running system to test its robustness during training. The program continued training after all of the students’ units were lost, then easily restored those units when they came back online. This behavior is what the research team describes as ‘self-sustaining’.
In simulations involving 1.2 million chips under high failure rates, Decoupled DiLoCo maintained a goodput (the fraction of time the system performs useful training) of 88%, compared to only 27% for standard Data-Parallel methods. Goodput is an important performance metric here: high-quality computerized training but low goodput wastes valuable resources.
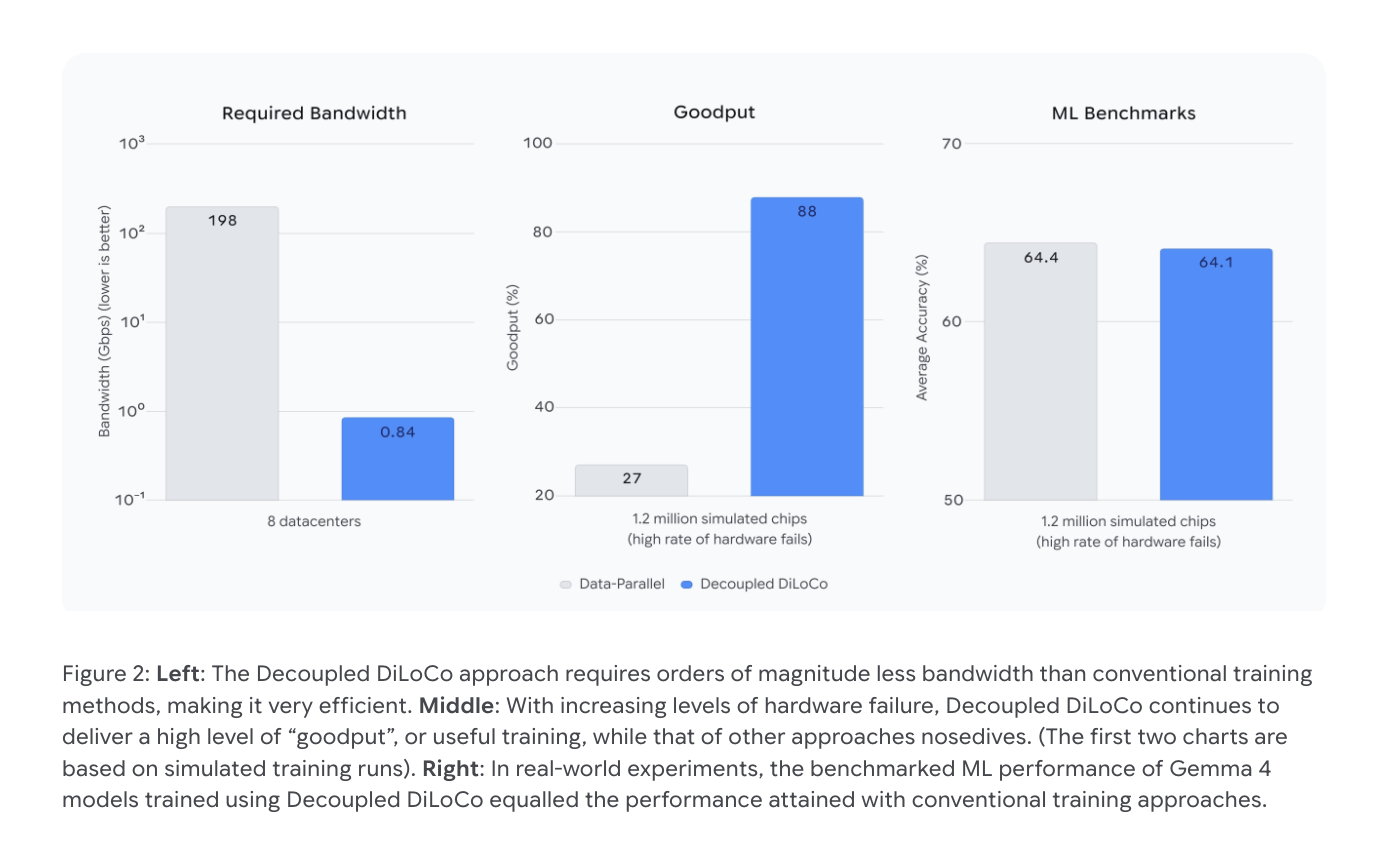
Unfortunately, these durability gains come with a slight degradation in the quality of the models. In real-world testing you use Gemma 4 models, Decoupled DiLoCo achieved an average ML benchmark accuracy of 64.1%, compared to 64.4% of the standard baseline – the difference between the noise of the standard deviation of the test.
Training the 12B Model in Four US States
The research team validated Decoupled DiLoCo at production scale by successfully training a 12 billion parameter model across four different US states use just 2–5 Gbps of wide area connectivity, the bandwidth level achievable by commercial Internet infrastructure between data center facilities. The program achieved this more than 20 times faster than conventional synchronization methods. The main reason: instead of forcing the computer to pause and wait for the communication to be completed, Decoupled DiLoCo combines the communication required for long computation times, eliminating the “blocking” barriers that slow down conventional distributed training on a global scale.
Mixing Hardware Generations
An underappreciated aspect of architecture is its support for various computing platforms. Because the reader units work in parallel, they do not need to run on the same hardware at the same clock speed. The research team demonstrated mixed training runs TPU v6e again TPU v5p chips – generations of different hardware with different performance characteristics – in a single training task, without degrading the performance of ML in relation to parallel runs.
This has two practical implications that should be noted. First, it extends the useful life of existing hardware, allowing older accelerators to continue to make a significant contribution to large-scale training. Second, because new generations of hardware do not arrive everywhere at the same time, being able to train across generations can alleviate recurring logistical and capacity constraints that arise during hardware changeovers – a real operational challenge for organizations using large training infrastructures.
Key Takeaways
- Decoupled DiLoCo eliminates the single-point-of-failure problem in large-scale AI training by dividing the training across non-synchronous, error-isolated “islands” of the computer called learner units – so a chip or cluster failure on one island does not block the rest of the training.
- Architectures reduce data center bandwidth requirements by orders of magnitude – from 198 Gbps down to 0.84 Gbps across eight data centers – making globally distributed pre-training possible using a common wide area network rather than requiring a custom high-speed infrastructure.
- Decoupled DiLoCo is self-sustaining: using chaos engineering to simulate real hardware failures, the system maintained 88% goodput compared to only 27% for standard Data-Parallel training under high failure rates, and seamlessly reassembled offline learner units when they came back online.
- The method was validated on a production scalesuccessfully training a 12 billion parameter model across four US states – achieving this more than 20 times faster than conventional synchronization methods by folding the connection into the calculation rather than as a preventative measure.
- Decoupled DiLoCo supports different hardware in a single training rundemonstrated by mixing TPU v6e and TPU v5p chips without performance degradation – extending the useful life of older accelerators and reducing bottlenecks during hardware manufacturing transitions.
Check it out Paper again Technical details. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? contact us



