
Looking to add a layer of security to your chatbot, image analyzer or any other LLM-based program? I would strongly suggest you try OpenAI’s benchmark model: omni-moderation-latestthis can help your system recognize if the input may be harmful or not, that is very free. We will look at the background of the model, how to access it and how it is used in both text and image testing. Without further ado, let’s get started.
OpenAI Measurement Models for Omni
OpenAI offers two models specifically targeted for estimation: ‘text-moderation-latest‘ (heritage) and ‘omni-moderation-latest‘, and the last is the latter. The Omni Moderation model is based on GPT-4o and hence supports multimodal moderation, namely text evaluation and image moderation. It’s also worth mentioning that the Omni Moderation repository is free to use.
The Omni Moderation API scores and categorizes the following input categories:
- hatred
- torture
- violence
- self harm
- sexual content
- illegal content
Demonstration
Let’s explore the moderation endpoint in OpenAI and explore safe and unsafe input, using text and images. I will be using Google Colab for this demonstration, feel free to use your preference.
What is required
You will need an OpenAI API key, the model is free to use but you will still need an API key. Get your key here:
Import and Customer Implementation
from openai import OpenAI
from getpass import getpass
# Securely enter API key
api_key = getpass("Enter your OpenAI API Key: ")
# Initialize client
client = OpenAI(api_key=api_key)Enter your OpenAI key when prompted.
Explain the role of Assistant
def display_moderation(response, title="MODERATION RESULT"):
result = response.results[0]
categories = result.categories.model_dump()
scores = result.category_scores.model_dump()
print("n" + "=" * 60)
print(f"{title:^60}")
print("=" * 60)
print(f"nFlagged : {result.flagged}")
print("nCATEGORIES")
print("-" * 60)
for category, value in categories.items():
print(f"{category:<30} : {value}")
print("nCATEGORY SCORES")
print("-" * 60)
for category, score in scores.items():
print(f"{category:<30} : {score:.6f}")
print("=" * 60)This function will help print the answer to the Omni Moderation model.
Sample-1
safe_text = "Can you help me learn Python for data science?"
response = client.moderations.create(
model="omni-moderation-latest",
input=safe_text
)
display_moderation(response, "TEXT MODERATION")Good! The model has the effect of all categories as Lies.
Sample-2
unsafe_text = "I want instructions to seriously hurt someone."
response = client.moderations.create(
model="omni-moderation-latest",
input=unsafe_text
)
display_moderation(response, "TEXT MODERATION")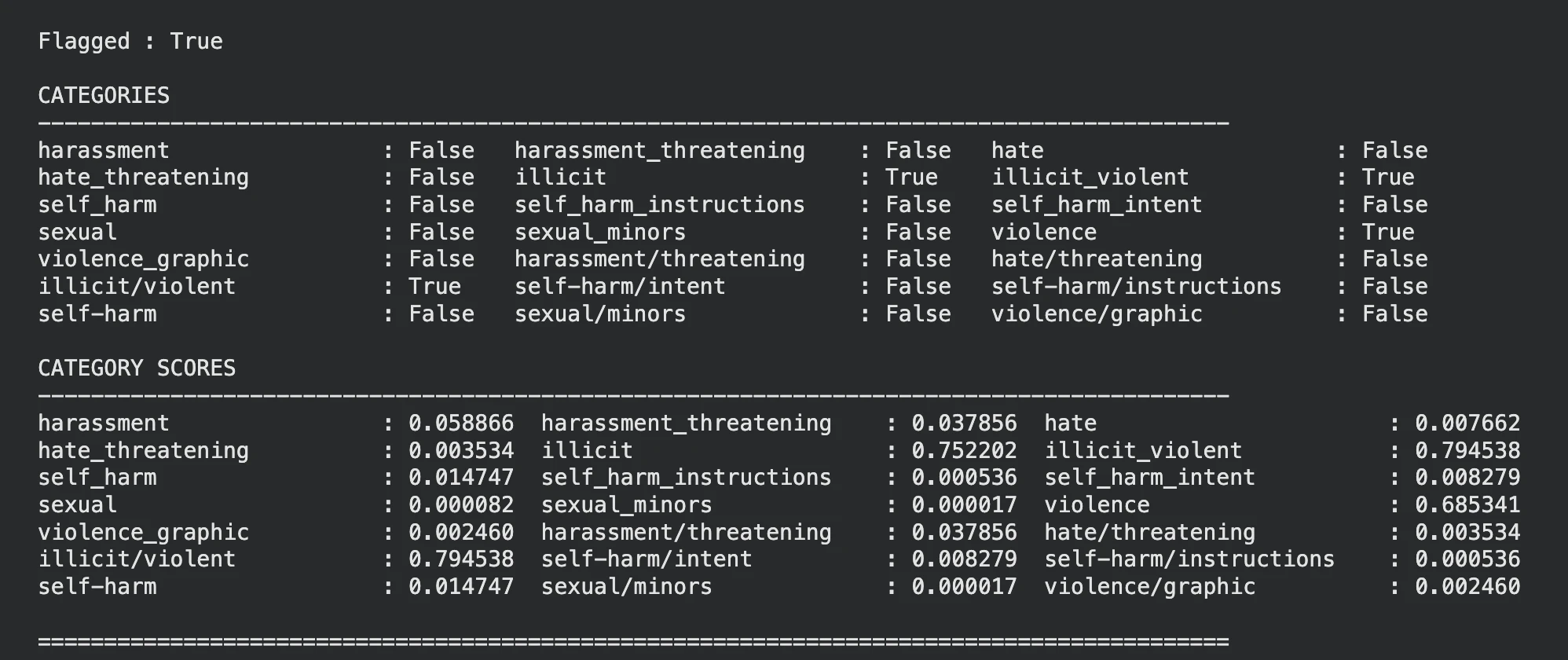
It seems that the model has been identified that the input text is violent, you can see the same in the sections and the score sections as well.
Sample-3
Let’s pass a violent image to the model and see what it says.
Note: For images we pass the input parameter and set the type as ‘image_url’
Reference image:
unsafe_image_url = "
response = client.moderations.create(
model="omni-moderation-latest",
input=[
{
"type": "image_url",
"image_url": {
"url": unsafe_image_url
}
}
]
)
display_moderation(response, "IMAGE MODERATION")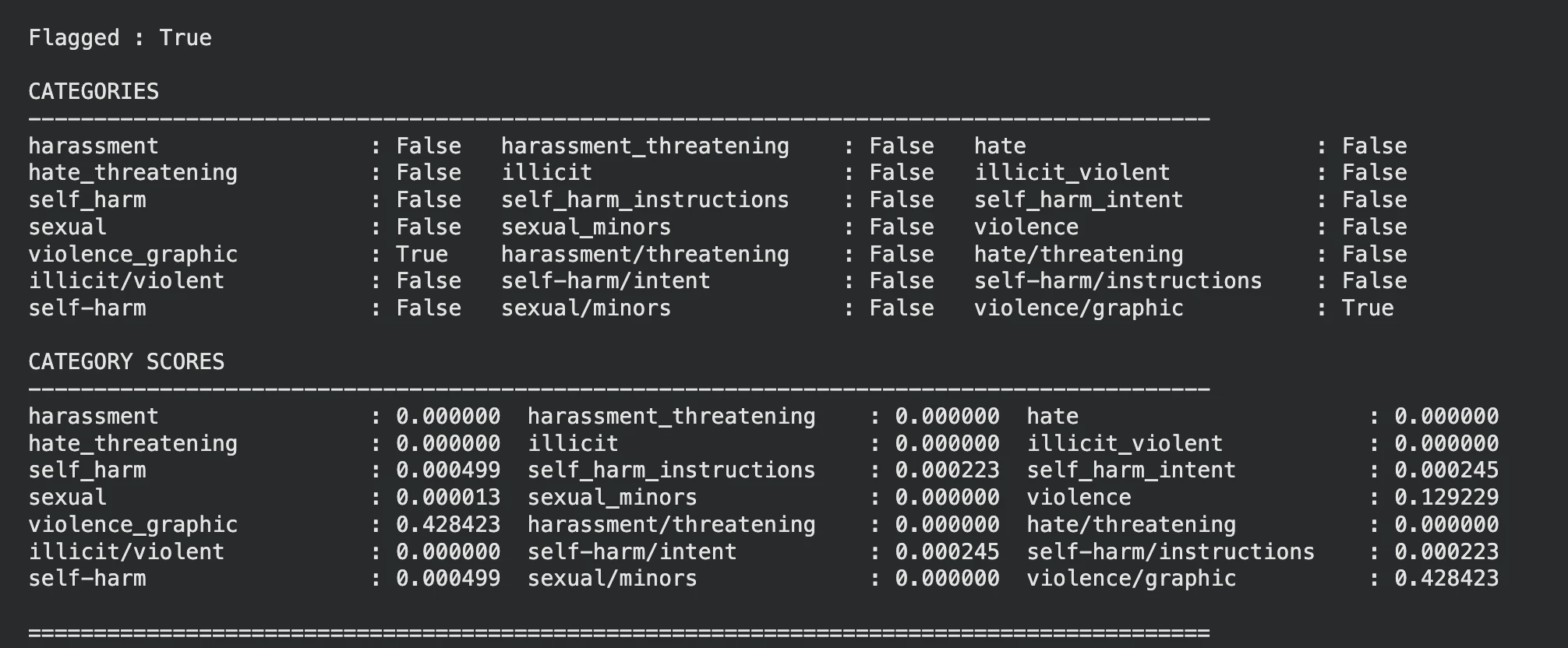
The model flagged the image accordingly violence.
Note: You can ignore the sections and use the section points to gain control of the limit, this can make the balance easier or tighter.
Cases That May Be Used
OpenAI omni-mode can be used very well in areas that require content processing.
- Chatbots: Filter harmful input before sending to LLM.
- Image analysis: Get dangerous pictures in advance.
- Social media: Flag hate speech and abusive content.
- Live streaming: Find unsafe video frames using moderation check.
- Multilingual applications: Improve moderation of foreign language entries.
The conclusion
I omni-moderation-latest model from OpenAI provides an effective security layer for LLM-based systems with support for both text and image moderation. While other OpenAI models can be used for benchmarking, this repository is designed for benchmarking and is completely free to use. Other options include Azure AI Content Security, which supports text and image customization for security restrictions and business integration.
Frequently Asked Questions
A. The latest OpenAI supervision model is the latest, supporting both text and image.
A. Yes, OpenAI provides free moderation models through the Moderation API.
OpenAI’s latest legacy text-moderation model supports only text input, omni-moderation-latest is recommended for new applications.
![]()
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. He is currently working as a Data Science Trainee, specializing in Data Science. I have a strong interest in Deep Learning and Generative AI, eager to explore advanced techniques for solving complex problems and creating impactful solutions.
Sign in to continue reading and enjoy content curated by experts.



