MiniMax Sparse Attention (MSA): Two-Branch Block-Sparse Attention Trained on 109B-Parameter MoE with a 3T-Token Budget
: Two-Branch Block-Sparse Attention Trained on 109B-Parameter MoE with a 3T-Token Budget")
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built specifically on Grouped Query Attention (GQA). Target one bottleneck: the quadratic cost of softmax attention in the long context. The MiniMax research team tested it within a 109B-parameter Mixture-of-Experts model trained on native multimodal data. They also open sourced the inference kernel and shipped a production model, the MiniMax-M3.
What is MSA (MiniMax Sparse Attention)
MSA (MiniMax Sparse Attention) divides attention into two categories: the Index Branch and the Main Branch. The Index branch determines which key value blocks each query to read. The Master branch then applies softmax attention directly to those blocks only.
The selection happens on a block-by-block basis, not on a per-token basis. The default block size is Bk = 128 tokens. Each question and the GQA group is final k = 16 blocks. That adjusts the budget for each query to kBk = 2,048 key value tokens.
The two cost structures are different. Dense GQA attention rates per query as O(N), full context. MSA scales as O(kBk), which remains stable as N increases. Therefore the calculation gap increases as the length of the core increases.
Selection is shared within each GQA group but is independent across groups. A single key-value header provides multiple query headers, and they share a single block set. Different teams can travel to different long-distance regions.
How the Two Branches Work
The Index Branch adds only two matrices to the standard GQA layer. It defines one query index for each GQA group and one assigned index key header. It finds virtual key tokens, and max-pools those tokens at the block level.
The Top-k operator then selects the blocks with the highest scores per query and group. The local block containing the query is always included. This prevents the selector from discarding the nearest query point.
The Master Branch collects virtual tokens from selected blocks. It works with limited dot-product softmax attention limited to those tokens. Each query head keeps its own query’s assumptions but shares the group block set.
The views in the report show what the index read is selecting. The heads are centered on the diagonal of the area and the first block. They keep the remaining budget on a few long-distance lines.
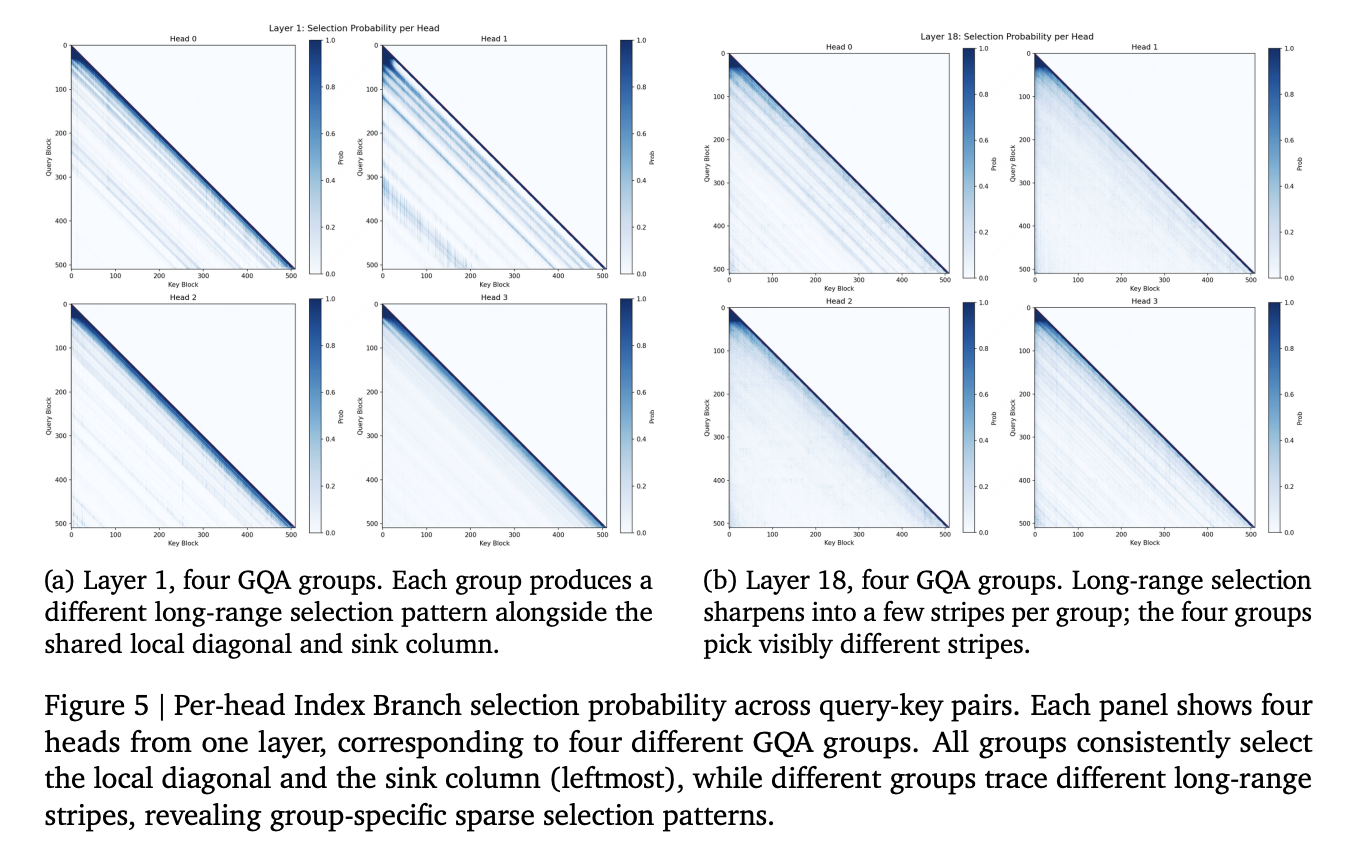
How MSA is trained
Top-k selection is non-variable, so the loss of language template cannot train index prediction. MSA solves this with the loss of KL alignment. The loss corresponds to the distribution of the Reference Branch and the attention pattern of the Main Branch. The teacher is a distribution of the Main branch that is limited by the group over the selected tokens.
Three ways to stabilize micro training. Gradient Detach applies a stop-gradient to the input of the Index branch. This puts the loss of KL on the display of the index, not the spine. Without it, the large coefficients of KL caused the increase of the gradient and the variation of the loss.
Indexer Warmup uses full attention on both branches for the first iteration. The indicator learns from the loss of KL before it controls the route. Forced Local Block reserved one area of the immediate context.
Ablations form the ultimate recipe. The original exception added an Index Branch value header with its output. Once the warmup has been applied, that value head is no longer needed. The final design is reduced for efficiency reasons.
MSA supports two training routes. MSA-PT trains from the beginning after the warming of the 40B token index. MSA-CPT transforms the GQA dense test space trained on 2.6T tokens. Then it continues with 400B tokens, including 40B warmup tokens.
Kernel Co-Design
Theory sparsity does not speed up without a parallel GPU approach. MSA combines the algorithm with two kernel concepts.
First of all is a timeless Top-k choice. Softmax maintains order, so the level of green points shows the same indicators. The kernel skips the steps max, exp, and sum before selecting. In the context of 128K with k = 16moved 5.1× faster than torch.topk. It also beat the TileLang radix-select kernel by 3.7×.
The second one KV-external little attention to the question to collect. Repeating KV blocks raises the arithmetic intensity compared to repeating queries. The kernel packs ⌈128/G⌉ query points into 128×128 points for a single MMA. The two-stage forward divides the attention and unites the steps in all CTAs.
An open source kernel, fmha_sm100it targets NVIDIA SM100 GPUs. It ships FlashAttention dense and Top-k sparse kernels under the MIT license. Supports BF16, FP8, NVFP4, and FP4 accuracy.
How MSA Compares to Other Microsystems
The research team pitted MSA against four traditionally trained designs.
The table below summarizes the differences it describes.
| The way | The backbone | Granularity of choice | Indicator / selection signal |
|---|---|---|---|
| MSA | GQA | Block rate (B_k = 128), with GQA-group Top-k | Loss of KL alignment |
| The NSA | QA/MHA | Blocks pressed + selected + sliding window | Native training (end to end). |
| InfLLM-V2 | Density↔changeable constant | Parameterless block selection + sliding window | Parameter-free (no index qualified) |
| MoBA | GQA | Largest KV blocks (block-average keys) | LM gradient only |
| DSA | MLA (MQA mode) | The level of tokens; One Top-k is shared by heads | ReLU lightning indexer |
The distinguishing pair of MSA is the Top-k share of each GQA group combined with block level selection. This keeps the KV readable together while giving each group their own recovery.
The quality side is rising. Both minority models remain widely competitive with the Full Attention base.
The table below shows the results of representatives under the 3T-token budget.
| Benchmark | It’s full | MSA-PT | MSA-CPT |
|---|---|---|---|
| MMLU | 67.0 | 67.2 | 66.8 |
| GSM8K | 76.2 | 77.7 | 73.7 |
| HumanEval | 61.0 | 64.0 | 57.9 |
| GOVERNOR-8K | 79.8 | 84.2 | 77.2 |
| GOVERNOR-32K | 75.0 | 77.5 | 75.7 |
| VideoMME | 41.11 | 45.48 | 39.65 |
After extended content, MSA-CPT remained close to full in HELMET-128K and RULER-128K. Each query still only checks for 2,048 key-value tokens.
A playground for interpretation



